ndvr
1.0.0
2. Platz für den Neural Search Hackathon?
Wir haben ein explosionsartiges Wachstum der Videodaten auf einer Vielzahl von Video-Sharing-Websites erlebt. Da Milliarden von Videos im Internet verfügbar sind, wird es zu einer großen Herausforderung, eine nahezu doppelte Videoabfrage (NDVR) aus einer großen Videodatenbank durchzuführen. NDVR zielt darauf ab, nahezu doppelte Videos aus einer riesigen Videodatenbank abzurufen, wobei nahezu doppelte Videos als Videos definiert werden, die den Originalvideos optisch nahe kommen.
Benutzer haben einen starken Anreiz, ein angesagtes Kurzvideo zu kopieren und eine erweiterte Version hochzuladen, um Aufmerksamkeit zu erregen. Mit der Zunahme von Kurzvideos tauchen neue Schwierigkeiten und Herausforderungen bei der Erkennung nahezu doppelter Kurzvideos auf.
Hier haben wir mit Jina eine neuronale Suchlösung entwickelt, um die Herausforderung von NDVR zu lösen.
Inhaltsverzeichnis

Beispiel für harte positive Kandidatenvideos. Obere Reihe: seitlich gespiegelt, farbgefiltert und mit Wasser gewaschen. Mittlere Reihe: Der horizontale Bildschirm wurde in einen vertikalen Bildschirm mit großen schwarzen Rändern geändert. Untere Reihe: gedreht
Beispiel für harte Negativvideos. Alle Kandidaten ähneln optisch der Abfrage, sind jedoch keine annähernden Duplikate.
Für die Auswahl von Kandidatenvideos gibt es drei Strategien:
Aus Zeit- und Ressourcengründen haben wir uns für die Strategie „Transformed Retrieval“ entschieden. In realen Anwendungen würden Benutzer Trendvideos kopieren, um persönliche Anreize zu schaffen. Benutzer entscheiden sich normalerweise dafür, ihre kopierten Videos leicht zu ändern, um die Erkennung zu umgehen. Diese Änderungen umfassen das Zuschneiden von Videos, das Einfügen von Rändern usw.
Um ein solches Benutzerverhalten nachzuahmen, definieren wir eine zeitliche Transformation, z. B. Videogeschwindigkeit, und drei räumliche Transformationen, z. B. Videozuschneiden, Einfügen schwarzer Ränder und Videorotation.
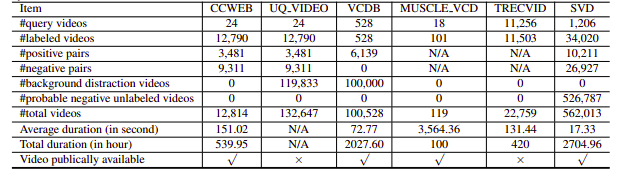
Leider hatten die untersuchten NDVR-Datensätze entweder eine niedrige Auflösung oder waren riesig, domänenspezifisch oder nicht öffentlich verfügbar (wir haben auch nur wenige persönlich kontaktiert). Daher haben wir beschlossen, unseren kleinen benutzerdefinierten Datensatz zum Experimentieren zu erstellen.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexDer Index Flow ist wie folgt definiert:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueDies gliedert sich in die folgenden Schritte:
Hier verwenden wir eine YAML-Datei, um einen Flow zu definieren und ihn zum Indizieren der Daten zu verwenden. Die index benötigt einen input_fn Parameter, der einen Iterator benötigt, um Dateipfade zu übergeben, die weiter in eine IndexRequest verpackt und an den Flow gesendet werden.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query Anschließend können Sie Jinabox mit dem benutzerdefinierten Endpunkt http://localhost:45678/api/search öffnen
Der Abfragefluss ist wie folgt definiert:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlDer Abfrageablauf gliedert sich in die folgenden Schritte:


