telegram archive server
v0.4.1 - 蔚蓝更新
Ein Such- und Archivierungsroboter für Telegram-Gruppenchats, der für die CJK-Umgebung geeignet ist.

Klicken Sie auf die Schaltfläche [Suchen], um die Suchoberfläche automatisch zu authentifizieren und zu öffnen.
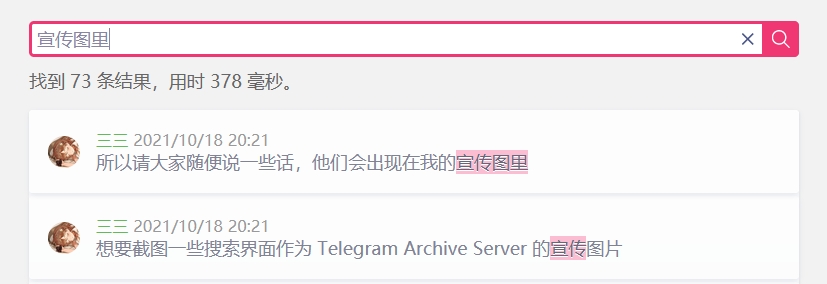
Klicken Sie auf den Zeitlink, um zur Chat-Oberfläche zu springen.
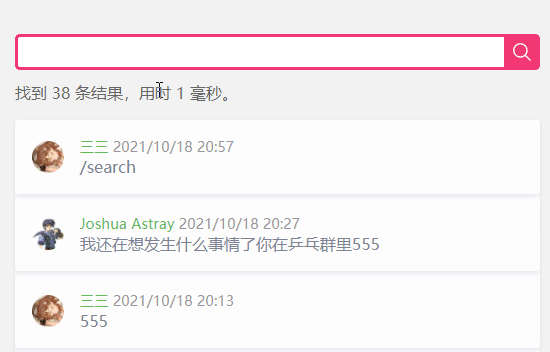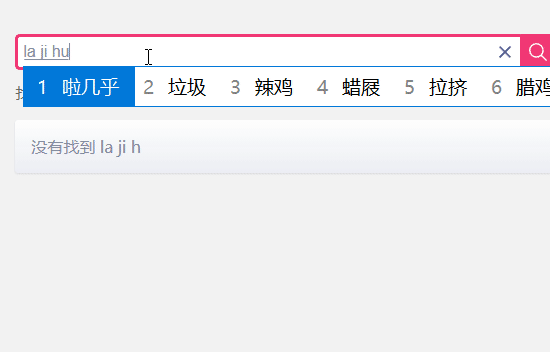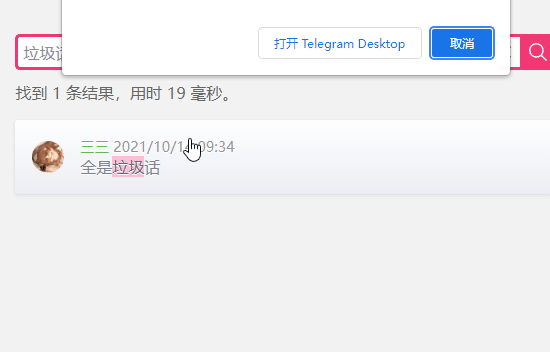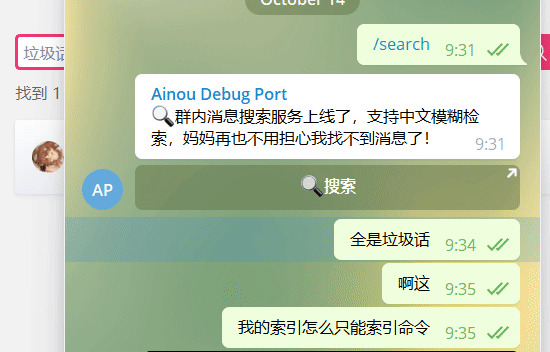
Sie müssen:
Laden Sie die Datei .env.example herunter, lesen Sie die internen Kommentare und konfigurieren Sie sie entsprechend.
Sie können es als .env speichern oder als Umgebungsvariable konfigurieren.
TAS bietet keinen integrierten https-Dienst. Es wird empfohlen, Caddy oder eine ähnliche Software zum Reverse-Proxy-TAS zu verwenden.
docker run -d --restart=always --env-file=.env quay.io/oott123/telegram-archive-serverNatürlich können Sie es auch mit Kubernetes oder Docker-Compose ausführen.
Wenn Sie Docker nicht haben oder Docker nicht verwenden möchten, können Sie auch aus dem Quellcode kompilieren und bereitstellen. An dieser Stelle benötigen Sie außerdem:
git clone https://github.com/oott123/telegram-archive-server.git
cd telegram-archive-server
# git checkout vX.X.X
cp .env.example .env
vim .env
yarn
yarn build
yarn start Senden /search in der Gruppe. Der Bot fordert Sie möglicherweise auf, die Domäne festzulegen. Befolgen Sie einfach die Anweisungen.
Benutzer müssen die folgenden Kriterien erfüllen, damit ihr Avatar in den Suchergebnissen angezeigt wird:
Da MeiliSearch eine schlechte Indexierungseffizienz für neue Nachrichten aufweist, werden Nachrichten nur dann in den Index aufgenommen, wenn eine der folgenden Bedingungen erfüllt ist:
Wenn Redis nicht zum Beibehalten der Nachrichtenwarteschlange verwendet wird, können Nachrichten, die nicht in die Warteschlange eingegeben wurden, verloren gehen, wenn das Programm abnormal ist oder der Server neu gestartet wird.
Derzeit wird nur der Import von Supergruppen unterstützt.
Klicken Sie im Desktop-Client auf die Schaltfläche mit den drei Punkten – Chatverlauf exportieren, warten Sie, bis der Export abgeschlossen ist, und rufen Sie result.json ab.
implementieren:
curl
-H " Content-Type: application/json "
-H " Authorization: Bearer $AUTH_IMPORT_TOKEN "
-XPOST -T result.json
http://localhost:3100/api/v1/import/fromTelegramGroupExportDatensätze können importiert werden. Beachten Sie, dass jeweils nur Datensätze einer einzelnen Gruppe importiert werden können.
Wenn Sie die OCR-Warteschlange aktivieren, ist Redis erforderlich (kann eine Instanz mit dem Cache teilen) und einen Erkennungsdienst eines Drittanbieters konfigurieren. Der Identifizierungsprozess läuft wie folgt ab:
Die Erkennung und Speicherung kann auf verschiedenen Rolleninstanzen erfolgen: Das Herunterladen von Bildern und die Textspeicherung werden auf der Bot-Instanz abgeschlossen, und die OCR-Instanz muss nur auf den OCR-Dienst zugreifen.
Dieses Design ermöglicht es Betreuern, eine zentralisierte Offline-Identifizierung zu entwerfen (z. B. eine präemptive Instanz zum Ausführen des Identifizierungsdienstes zu verwenden und ihn nach dem Löschen der Warteschlange herunterzufahren), um die Identifizierungskosten zu senken.
Wenn Sie einen Cloud-Dienst eines Drittanbieters verwenden, können Sie die OCR-Warteschlange direkt deaktivieren oder die Bot- und OCR-Rollen in derselben Instanz aktivieren.
Weitere Informationen finden Sie in der Dokumentation zur Texterkennung von Google Cloud Vision und in den Abrechnungsregeln für Google Cloud Vision. Die Konfiguration ist wie folgt:
OCR_DRIVER=google
OCR_ENDPOINT=eu-vision.googleapis.com # 或者 us-vision.googleapis.com ,决定 Google 在何处存储处理数据
GOOGLE_APPLICATION_CREDENTIALS=/path/to/google/credentials.json # 从 GCP 后台下载的 json 鉴权文件Sie benötigen eine Instanz von Paddleocr-Web. Die Konfiguration ist wie folgt:
OCR_DRIVER=paddle-ocr-web
OCR_ENDPOINT=http://127.0.0.1:8980/apiErstellen Sie eine Azure Vision-Ressource und konfigurieren Sie die Ressourceninformationen wie folgt:
OCR_DRIVER=azure
OCR_ENDPOINT=https://tas.cognitiveservices.azure.com
OCR_CREDENTIALS=000000000000000000000000000000000docker run [...] dist/main ocr,bot
# or
node dist/main ocr,botDEBUG=app: * ,grammy * yarn start:debug Nachdem der Suchdienst authentifiziert wurde, springt der Server zu: $HTTP_UI_URL/index.html mit den folgenden URL-Parametern:
tas_server – Server-Basis-URL im Format http://localhost:3100/api/v1tas_indexName – Gruppennummer im Format supergroup1234567890tas_authKey – Vom Server ausgegebenes JWT, das als API-Schlüssel von MeiliSearch verwendet werden kann. /api/v1/search/compilable/meili kann als normale MeiliSearch-Instanz durchsucht werden.
Der Indexname sollte eine Gruppennummer in der Form supergroup1234567890 verwenden; der API-Schlüssel ist der vom Server ausgegebene JWT.
Bitte beachten Sie, dass der Filter aus Sicherheitsgründen vorübergehend nicht verfügbar ist.


