CrawlerTutorial
1.0.0
Wenn wir im Internet surfen, sehen wir oft eine Vielzahl interessanter Inhalte, wie zum Beispiel Nachrichten, Produkte, Videos, Bilder usw. Wenn Sie jedoch eine große Menge spezifischer Informationen von diesen Webseiten sammeln möchten, sind manuelle Vorgänge zeitaufwändig und mühsam.
Zu diesem Zeitpunkt ist der Webcrawler (Web Crawler) praktisch! Einfach ausgedrückt ist ein Webcrawler ein Programm, das das Verhalten eines menschlichen Browsers nachahmen und Webinformationen automatisch crawlen kann. Mithilfe der Automatisierungsfunktionen dieses Programms können wir die für uns interessanten Daten ganz einfach von der Website „crawlen“ und diese Daten dann für eine spätere Analyse speichern.
Die Funktionsweise eines Webcrawlers besteht normalerweise darin, zunächst eine HTTP-Anfrage an die Zielwebsite zu senden, dann die HTML-Antwort von der Website abzurufen, den Inhalt der Seite zu analysieren und dann nützliche Daten zu extrahieren. Wenn wir beispielsweise Titel, Autor, Zeit und andere Informationen von Artikeln im PTT-Klatschforum sammeln möchten, können wir die Webcrawler-Technologie verwenden, um diese Informationen automatisch zu erfassen und zu speichern. Auf diese Weise erhalten Sie die benötigten Informationen, ohne die Website manuell durchsuchen zu müssen.
Webcrawler haben viele praktische Anwendungen, wie zum Beispiel:
Wenn wir Webcrawler verwenden, müssen wir uns natürlich an die Nutzungsbedingungen und Datenschutzrichtlinien der Website halten und dürfen keine Informationen crawlen, die gegen die Vorschriften der Website verstoßen. Um den normalen Betrieb der Website sicherzustellen, müssen wir gleichzeitig geeignete Crawling-Strategien entwickeln, um eine übermäßige Belastung der Website zu vermeiden.
Dieses Tutorial verwendet Python3 und verwendet pip, um die erforderlichen Pakete zu installieren. Folgende Pakete müssen installiert werden:
requests : Wird zum Senden und Empfangen von HTTP-Anfragen und -Antworten verwendet.requests_html : Wird zum Analysieren und Crawlen von Elementen in HTML verwendet.rich : Lassen Sie die Informationen schön an die Konsole ausgeben, z. B. durch die Anzeige einer schönen Tabelle.lxml oder PyQuery : Wird zum Parsen von Elementen in HTML verwendet.Befolgen Sie die folgenden Anweisungen, um diese Pakete zu installieren:
pip install requests requests_html rich lxml PyQueryIm Basiskapitel stellen wir kurz vor, wie Daten von der PTT-Webseite erfasst werden, z. B. Artikeltitel, Autor und Uhrzeit.
Nutzen wir die Versionsleseartikel von PTT als unsere Crawler-Ziele!
Beim Crawlen einer Webseite verwenden wir die Funktion requests.get() um zu simulieren, dass der Browser eine HTTP-GET-Anfrage zum „Durchsuchen“ der Webseite sendet. Diese Funktion gibt ein requests.Response -Objekt zurück, das den Antwortinhalt der Webseite enthält. Es ist jedoch zu beachten, dass dieser Inhalt in Form eines reinen Textquellcodes dargestellt wird und nicht vom Browser gerendert wird. Wir können es über die Eigenschaft „ response.text erhalten.
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
Bei späteren Verwendungen müssen wir requests_html verwenden, um requests Außerdem müssen wir HTML-Webseiten analysieren und den Quellcode response.text zur späteren Verwendung in requests_html.HTML requests_html . Das Umschreiben ist ebenfalls sehr einfach. Verwenden Sie session.get() um das obige requests.get() zu ersetzen.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )Wenn wir jedoch versuchen, diese Methode auf Klatsch und Tratsch anzuwenden, können Fehler auftreten. Dies liegt daran, dass die Website beim ersten Durchsuchen des Klatschforums bestätigt, ob wir über 18 Jahre alt sind. Wenn wir zur Bestätigung klicken, speichert der Browser die entsprechenden Cookies, sodass wir beim nächsten Besuch nicht erneut nachfragen Geben Sie ein (Sie können versuchen, den Inkognito-Modus zu verwenden, um den Test zu öffnen und die Homepage der Bagua-Version anzusehen). Für Webcrawler müssen wir jedoch dieses spezielle Cookie aufzeichnen, damit wir beim Surfen so tun können, als hätten wir den achtzehn Jahre alten Test bestanden.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) Als Nächstes können wir die Methode response.html.find() verwenden, um das Element zu finden, und den CSS-Selektor verwenden, um das Zielelement anzugeben. In diesem Schritt können wir beobachten, dass sich in der PTT-Webversion die Titelinformationen jedes Artikels in einem div -Tag mit einer r-ent -Kategorie befinden. Daher können wir den CSS-Selektor div.r-ent verwenden, um auf diese Elemente abzuzielen.
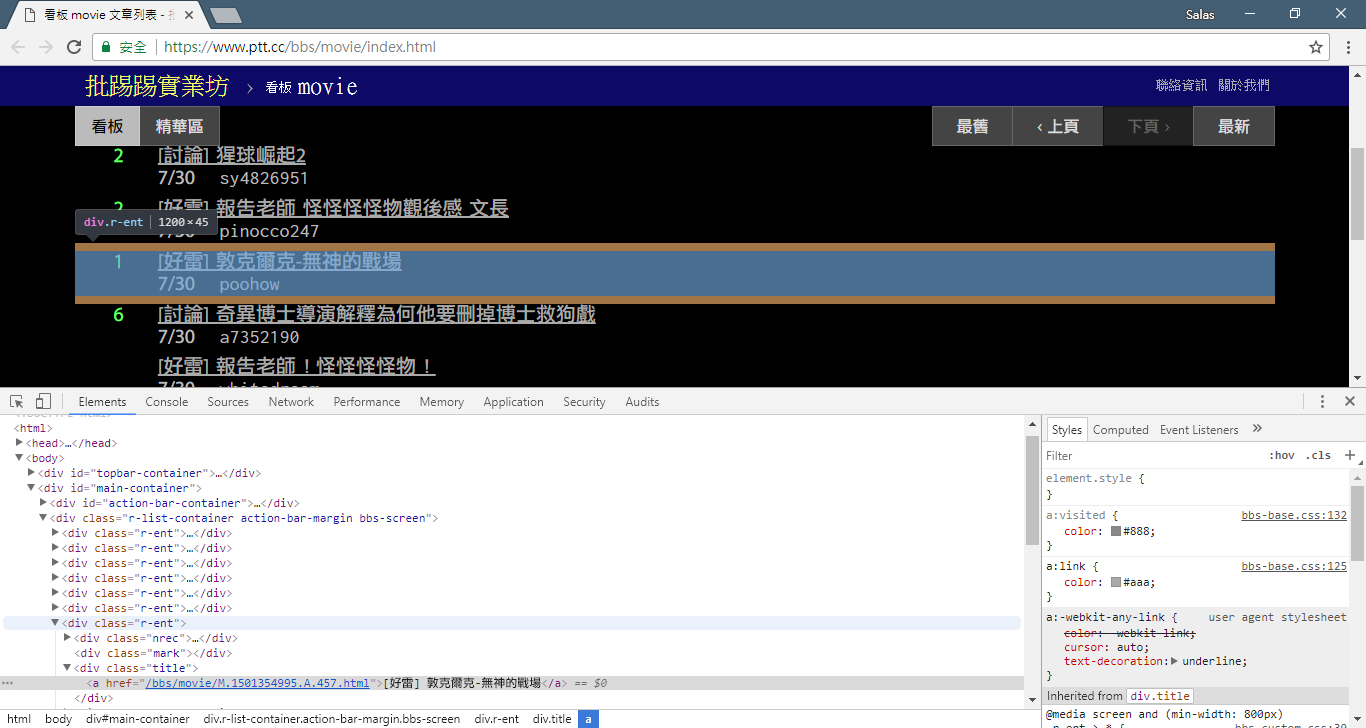
Die Verwendung der Methode „ response.html.find() gibt eine Liste von Elementen zurück, die die Bedingungen erfüllen, sodass wir diese Elemente mithilfe for Schleife einzeln verarbeiten können. Innerhalb jedes Elements können wir element.find() verwenden, um das Element weiter zu analysieren und CSS-Selektoren verwenden, um die zu extrahierenden Informationen anzugeben. In diesem Beispiel können wir den CSS-Selektor div.title verwenden, um auf das Titelelement abzuzielen. Ebenso können wir die Eigenschaft element.text verwenden, um den Textinhalt eines Elements abzurufen.
Hier ist ein Beispielcode mit requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... Im vorherigen Schritt haben wir die Methode response.html.find() verwendet, um die Elemente jedes Artikels zu finden. Diese Elemente werden mithilfe des CSS-Selektors div.r-ent gezielt angesprochen. Mit der Funktion „Entwicklertools“ können Sie die Elementstruktur einer Webseite beobachten. Nach dem Öffnen der Webseite und dem Drücken der F12-Taste wird ein Entwicklertools-Panel angezeigt, das die HTML-Struktur der Webseite und andere Informationen enthält.
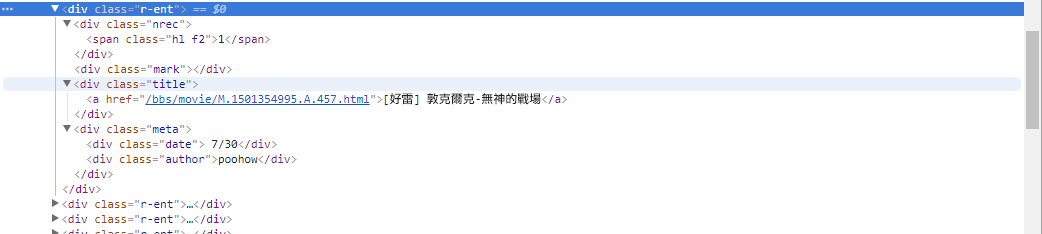
Mithilfe der Entwicklertools können Sie mit dem Mauszeiger ein bestimmtes Element auf der Webseite auswählen und dann die HTML-Struktur, CSS-Attribute und andere Details des Elements im Bedienfeld „Entwicklertools“ anzeigen. Auf diese Weise können Sie bestimmen, auf welches Element Sie abzielen und welchen CSS-Selektor Sie verwenden möchten. Außerdem erfahren Sie vielleicht, warum das Programm manchmal schief geht? ! Als ich mir die Webversion ansah, stellte ich fest, dass beim Löschen eines Artikels auf der Seite die結構des Elements <本文已被刪除> auf der Webseite sich von der ursprünglichen unterschied! So können wir es weiter stärken, um die Situation zu bewältigen, in der Artikel gelöscht werden.
Kehren wir nun zum Beispielcode für die Informationsextraktion mit requests_html zurück:
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )Ausgabetextverarbeitung:
Hier können wir rich verwenden, um eine schöne Ausgabe anzuzeigen. Erstellen Sie zunächst ein rich -Tabellenobjekt und ersetzen Sie dann print in der Schleife des obigen Beispielcodes durch add_row zur Tabelle. Abschließend verwenden wir die print von rich , um die Tabelle korrekt an das Terminal auszugeben.
Ausführungsergebnis
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )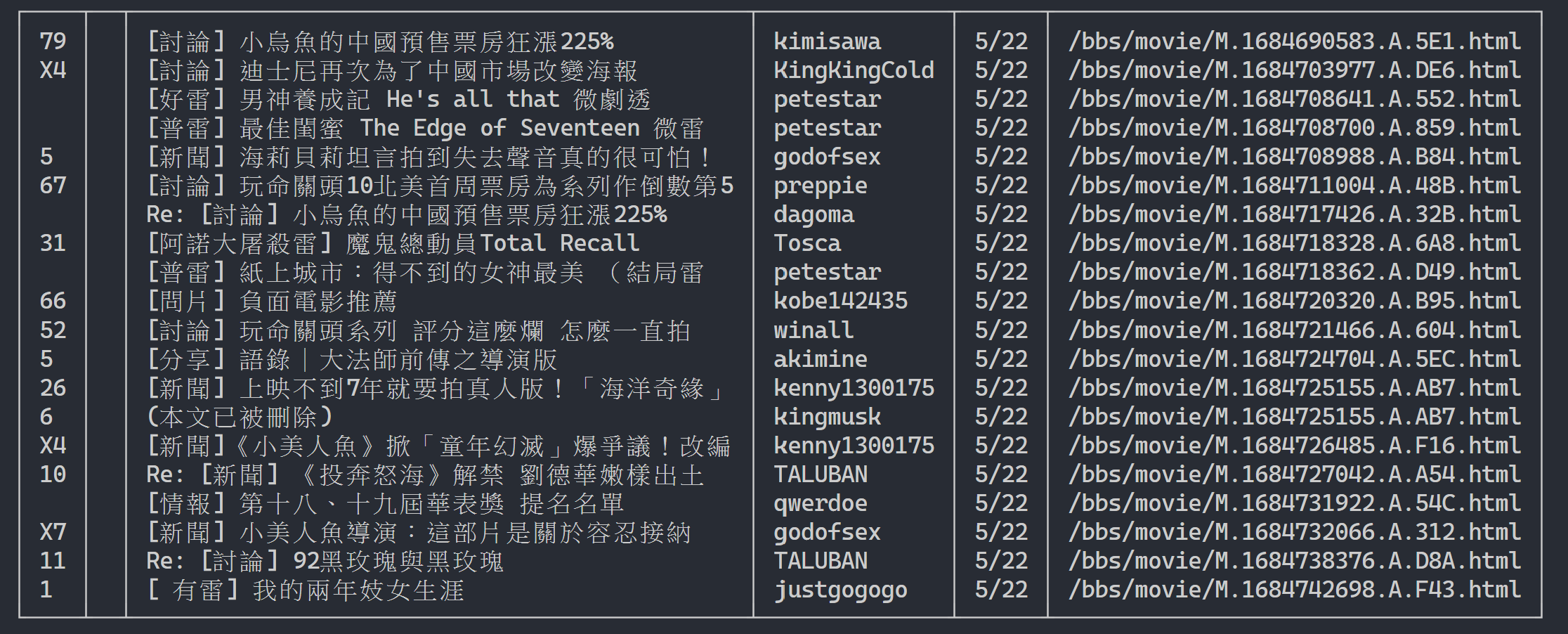
Jetzt verwenden wir die „Beobachtungsmethode“, um den Link zur vorherigen Seite zu finden. Nein, ich frage Sie nicht, wo sich die Schaltfläche in Ihrem Browser befindet, sondern nach dem „Quellbaum“ in den Entwicklertools. Ich glaube, Sie haben herausgefunden, dass sich der Hyperlink für den Seitensprung im <a class="btn wide"> -Element von <div class="action-bar"> befindet. Daher können wir sie wie folgt extrahieren:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )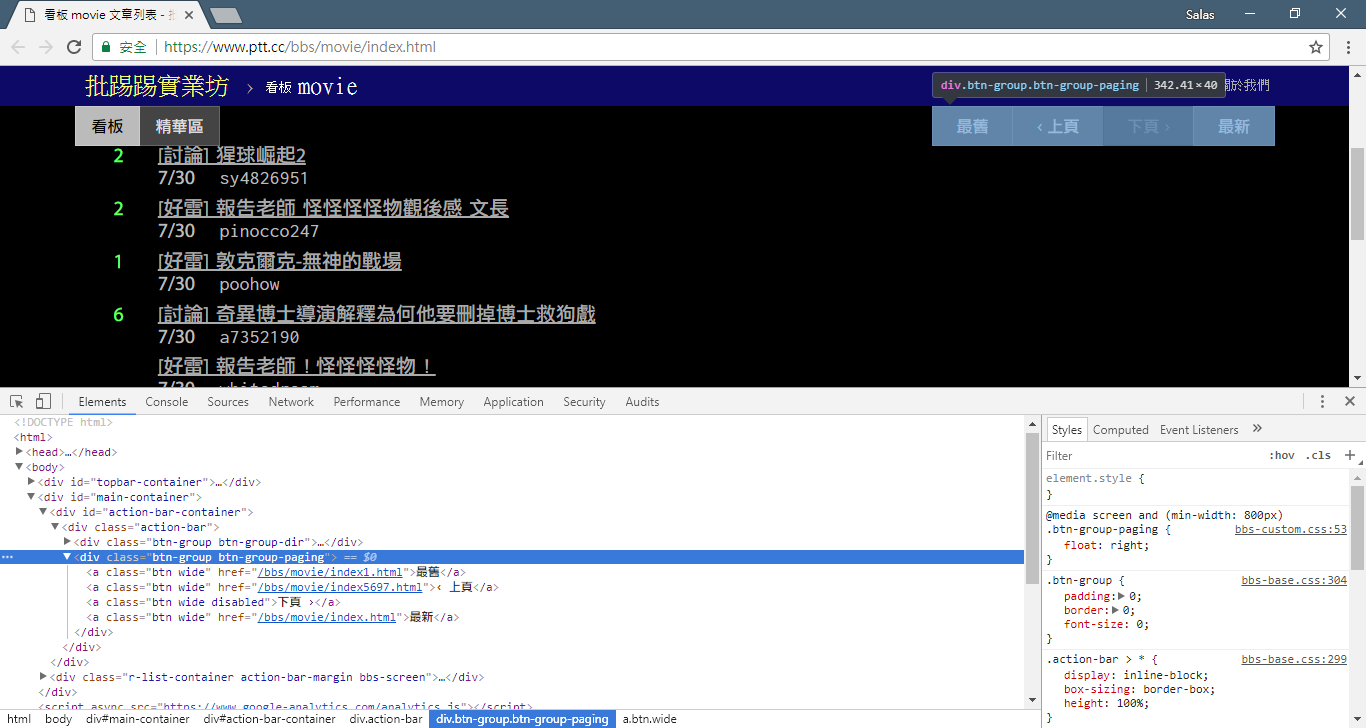
Was wir brauchen, ist die Funktion „Vorherige Seite“. Da die neuesten Artikel in PTT im Vordergrund angezeigt werden, müssen Sie vorwärts scrollen, wenn Sie nach Informationen suchen möchten.
Wie benutzt man es? Schnappen Sie sich zuerst den zweiten href im control (Index ist 1), dann sieht es möglicherweise so aus: /bbs/movie/index3237.html und die vollständige Website-Adresse (URL) muss https://www.ptt.cc/ sein ( Domänen-URL), also verwenden Sie urljoin() (oder eine direkte String-Verbindung), um den Link zur Film-Homepage mit dem neuen Link zu vergleichen und zu einer vollständigen URL zusammenzuführen!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url Lassen Sie uns nun die Funktion neu anordnen, um die nachfolgende Erklärung zu erleichtern. Lassen Sie uns das Beispiel der Verarbeitung jedes Artikelelements in Schritt 3 ändern: Schauen wir uns diese Titelnachrichten in eine unabhängige Funktion parse_article_entries(elements) an.
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsAls nächstes können wir mehrseitige Inhalte verarbeiten
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlAusgabeergebnis:
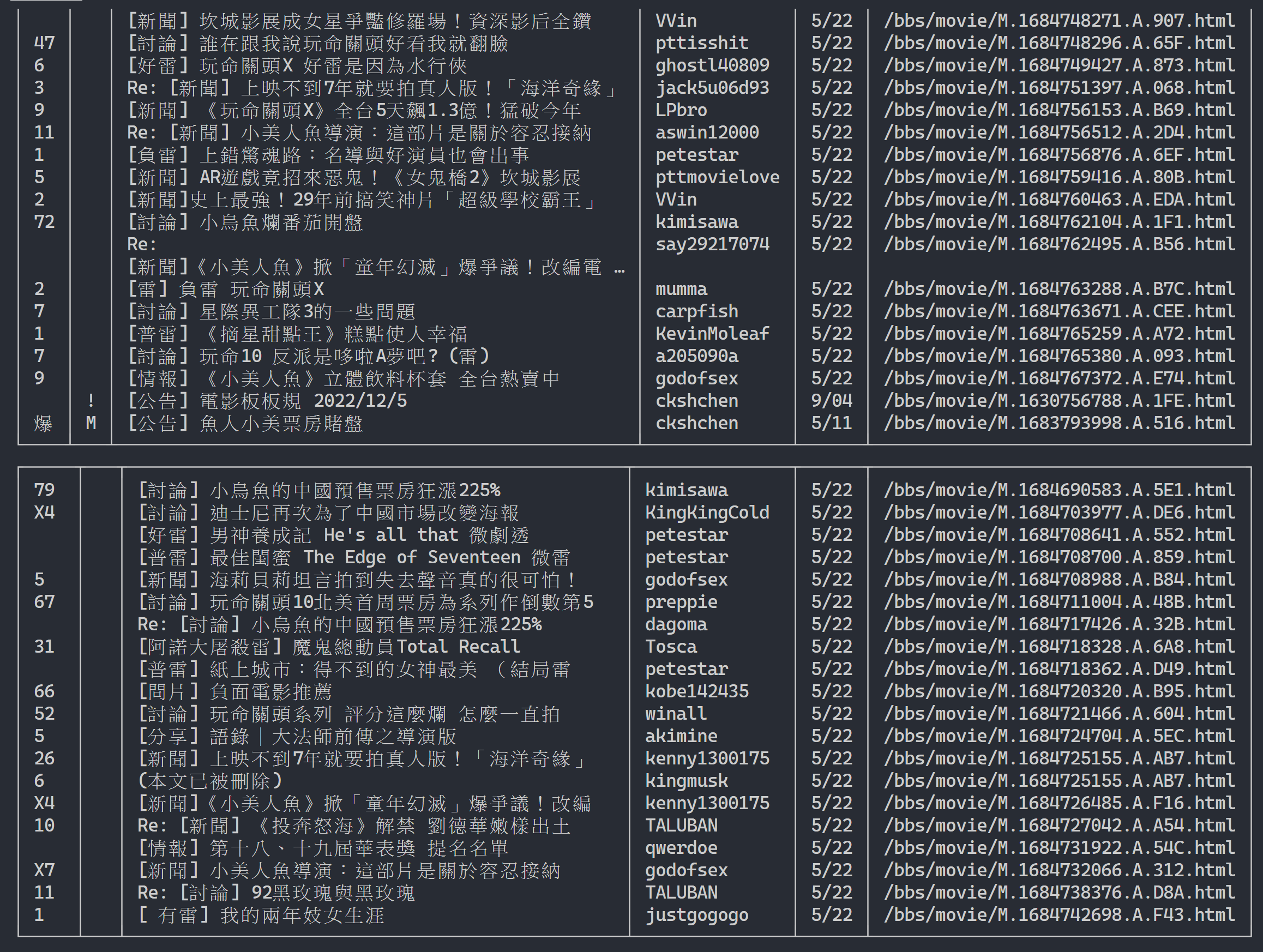
Nachdem Sie die Informationen zur Artikelliste erhalten haben, besteht der nächste Schritt darin, den Inhalt des Artikels (PO-Artikels) (Beitragsinhalt) abzurufen! link in den Metadaten ist der Link jedes Artikels. Wir verwenden auch urllib.parse.urljoin um die vollständige URL zu verketten, und geben dann HTTP GET aus, um den Inhalt des Artikels abzurufen. Wir können beobachten, dass die Aufgabe, den Inhalt jedes Artikels zu erfassen, sehr repetitiv ist und sich sehr gut für die Verarbeitung mithilfe einer Parallelisierungsmethode eignet.
In Python können Sie multiprocessing.Pool verwenden, um Multiprocessing-Programmierung auf hoher Ebene durchzuführen ~ Dies ist der einfachste Weg, Multiprozess in Python zu verwenden! Es eignet sich sehr gut für dieses SIMD-Anwendungsszenario (Single Instruction Multiple Data). Verwenden Sie die with Anweisungssyntax, um Prozessressourcen nach der Verwendung automatisch freizugeben. Die Verwendung von ProcessPool ist ebenfalls sehr einfach: pool.map(function, items) , was ein wenig dem Konzept der funktionalen Programmierung ähnelt. Wenden Sie eine Funktion auf jedes Element an und erhalten Sie schließlich die gleiche Anzahl von Ergebnislisten wie Elemente.
Wird bei der zuvor eingeführten Aufgabe zum Crawlen von Artikelinhalten verwendet:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )Im Anhang finden Sie die Versuchsergebnisse:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章Es ist ersichtlich, dass die Gesamtausführungsgeschwindigkeit um fast das Fünffache beschleunigt wurde, aber je mehr Process desto besser. Neben den Hardwarespezifikationen wie der CPU hängt dies hauptsächlich von den Einschränkungen externer Geräte wie Netzwerkkarten usw. ab Netzwerkgeschwindigkeiten.
Der obige Code ist in ( src/basic_crawler.py ) zu finden!
Neue Funktion in PTT Web: Suchen! Endlich in der Webversion verfügbar
Nutzen wir auch die Filmversion von PTT als Crawler-Ziel! Zu den in der neuen Funktion durchsuchbaren Inhalten gehören:
Die ersten drei können alle Regeln aus der neuen Version des Seitenquellcodes finden und Anfragen senden, aber die Tweet-Zählungssuche scheint nicht in der Benutzeroberfläche der Webversion aufgetaucht zu sein, daher sind hier die vom Autor aus PTT 網站原始碼ermittelten Parameter PTT 網站原始碼. Das PTT, das wir normalerweise durchsuchen, umfasst tatsächlich den BBS-Server (dh BBS) und den Front-End-Webserver (Webversion). Der Front-End-Webserver ist in der Go-Sprache (Golang) geschrieben und kann direkt auf das Back-End zugreifen BBS-Daten und -Nutzung Der allgemeine Website-Interaktionsmodus rendert den Inhalt in eine Webseite zum Durchsuchen.
Tatsächlich ist die Verwendung dieser neuen Funktionen sehr einfach. Sie müssen lediglich eine HTTP GET -Anfrage verwenden und eine Standardabfragezeichenfolge hinzufügen, um diese Informationen zu erhalten. Die endpoint -URL, die die Suchfunktion bereitstellt, ist /bbs/{看板名稱}/search . Verwenden Sie einfach die entsprechende Abfrage, um die Suchergebnisse von hier zu erhalten. Nehmen Sie zunächst das Titelschlüsselwort als Beispiel:
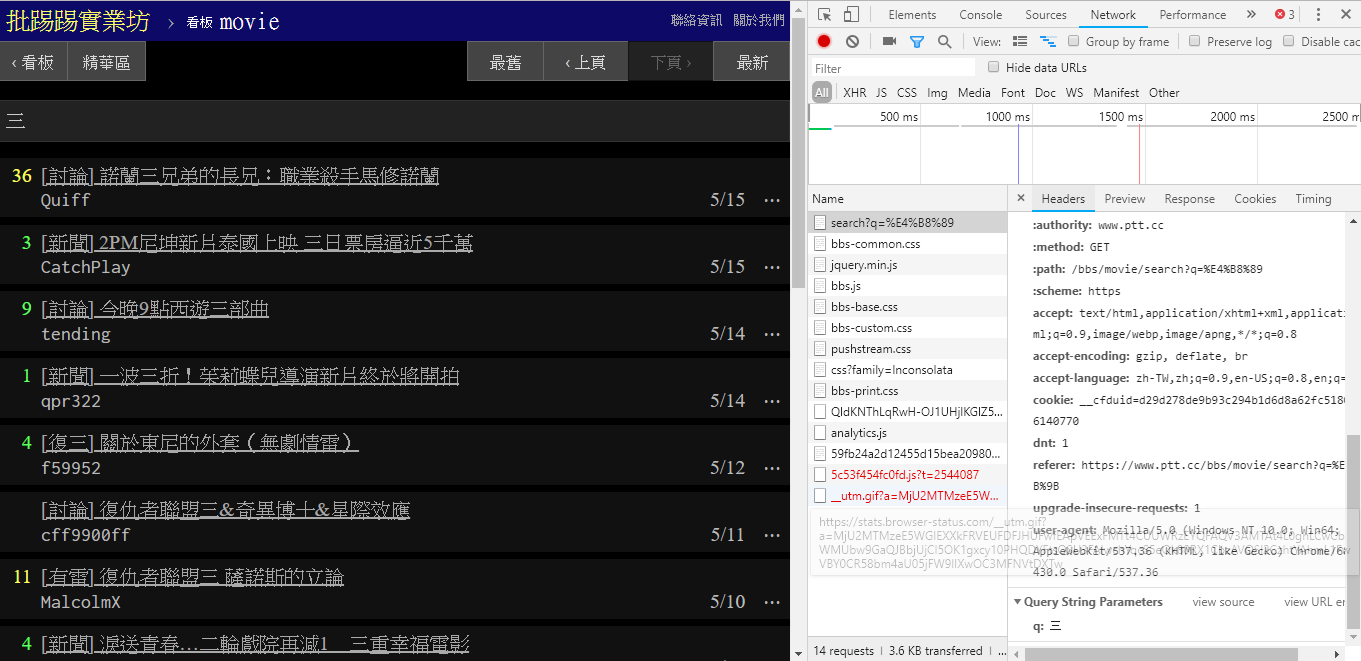
Wie in der unteren rechten Ecke des Bildes zu sehen ist, wird bei der Suche tatsächlich eine GET Anfrage mit q=三an endpoint gesendet, sodass die gesamte vollständige URL wie https://www.ptt.cc/bbs/movie/search?q=三aussehen sollte. https://www.ptt.cc/bbs/movie/search?q=三kann die aus der Adressleiste kopierte URL die Form https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 haben, da dies auf Chinesisch der Fall war HTML-codiert, hat aber die gleiche Bedeutung. Wenn Sie in requests zusätzliche Abfrageparameter hinzufügen möchten, müssen Sie die Zeichenfolgenform nicht manuell selbst erstellen. Sie müssen sie lediglich über dict() von param= in die Funktionsparameter einfügen, wie folgt:
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })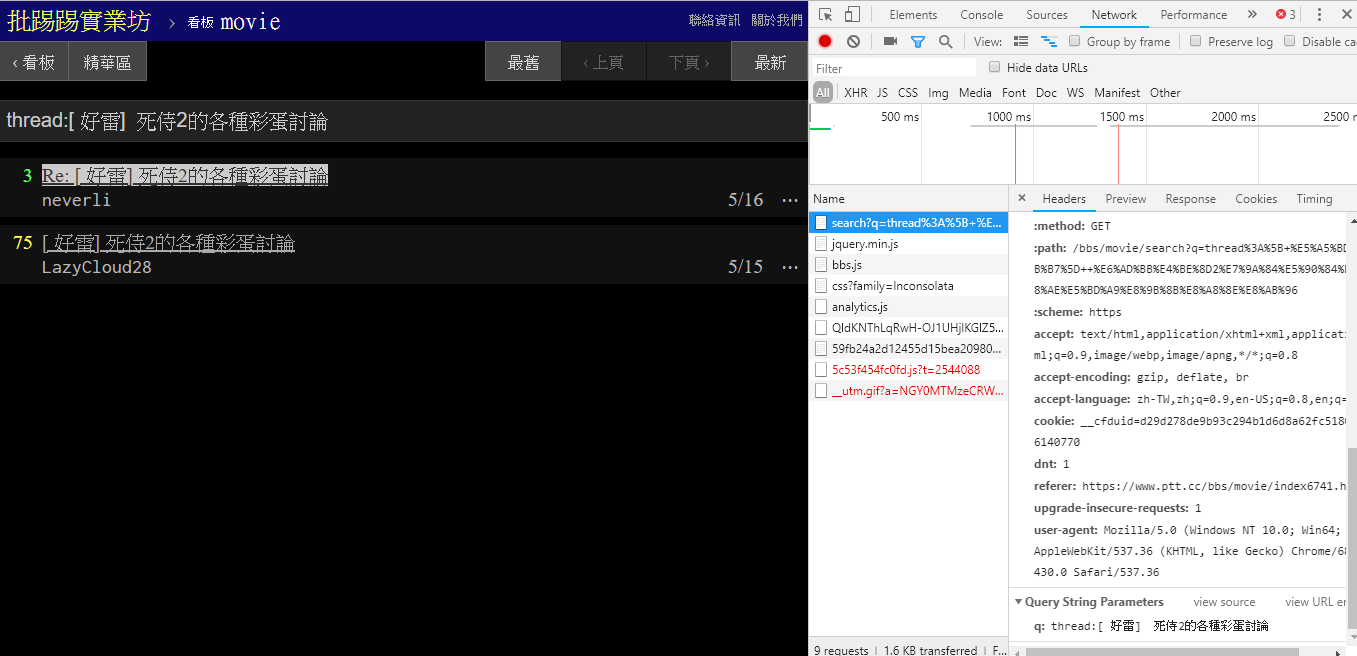
Wenn Sie nach demselben Artikel (Thread) suchen, können Sie anhand der Informationen in der unteren rechten Ecke erkennen, dass Sie tatsächlich die Zeichenfolge thread: vor dem Titel anhängen und die Anfrage senden.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })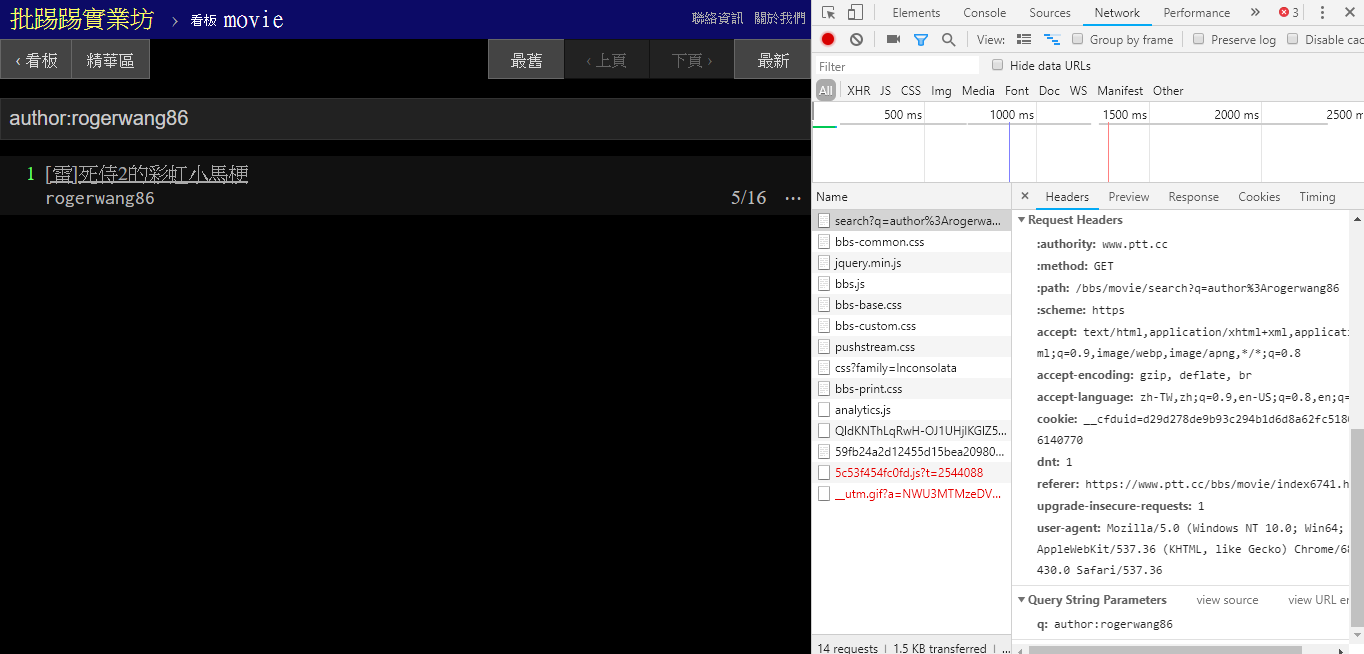
Bei der Suche nach Artikeln mit dem gleichen Autor (Autor) ist auch an der Information unten rechts zu erkennen, dass author: -String mit dem Namen des Autors verkettet und dann die Anfrage gesendet wird.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })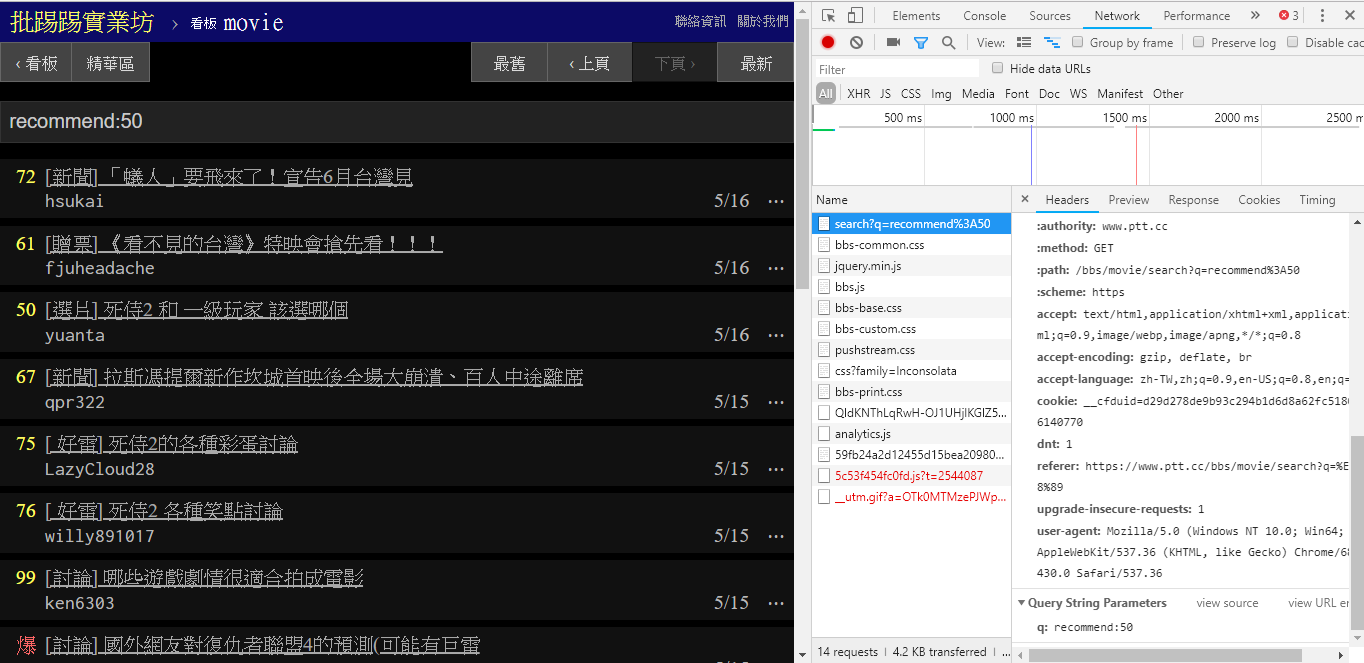
Wenn Sie nach Artikeln suchen, deren Anzahl an Tweets größer als (empfohlen) ist, verketten Sie die Zeichenfolge recommend: mit der Mindestanzahl an Tweets, die Sie durchsuchen möchten, und senden Sie dann die Abfrage. Darüber hinaus ist dem Quellcode des PTT-Webservers zu entnehmen, dass die Anzahl der Tweets nur innerhalb von ±100 eingestellt werden kann.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })Quellcode dieser Parameter für die PTT-Web-Parsing-Funktion
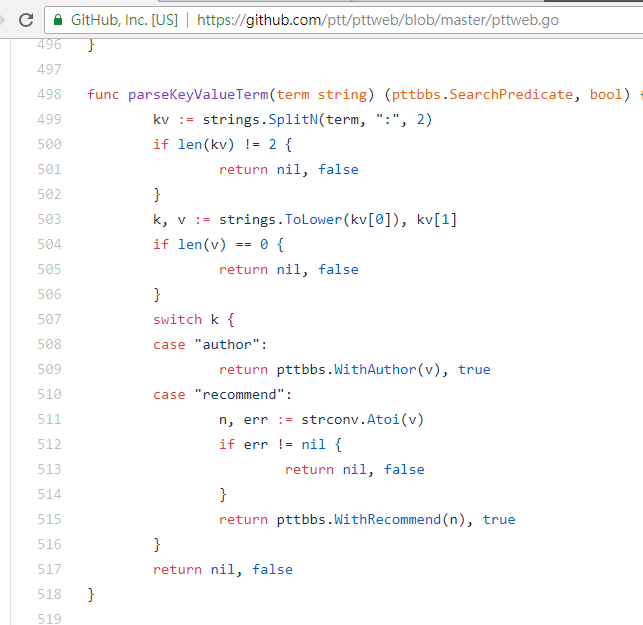
Erwähnenswert ist auch, dass die endgültige Darstellung der Suchergebnisse mit dem in den Grundlagen genannten allgemeinen Layout übereinstimmt, sodass Sie die vorherigen Funktionen direkt wiederverwenden können. Don't do it again!
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] Es gibt einen weiteren Parameter in der page , genau wie bei der Google-Suche. Sie können diesen zusätzlichen Parameter verwenden, um zu steuern, welche Ergebnisseite Sie erhalten möchten, ohne einen Link erstellen zu müssen die Seite.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) Durch die Integration aller vorherigen Funktionen in ptt-parser können Befehlszeilenfunktionen und爬蟲in Form von APIs bereitgestellt werden, die programmgesteuert aufgerufen werden können.
scrapy , um PTT-Daten stabil zu crawlen.
Dieses Werk wurde von leVirve produziert und wird unter einer Creative Commons Attribution 4.0 International License veröffentlicht.


