FileMasta
Beta 4.6
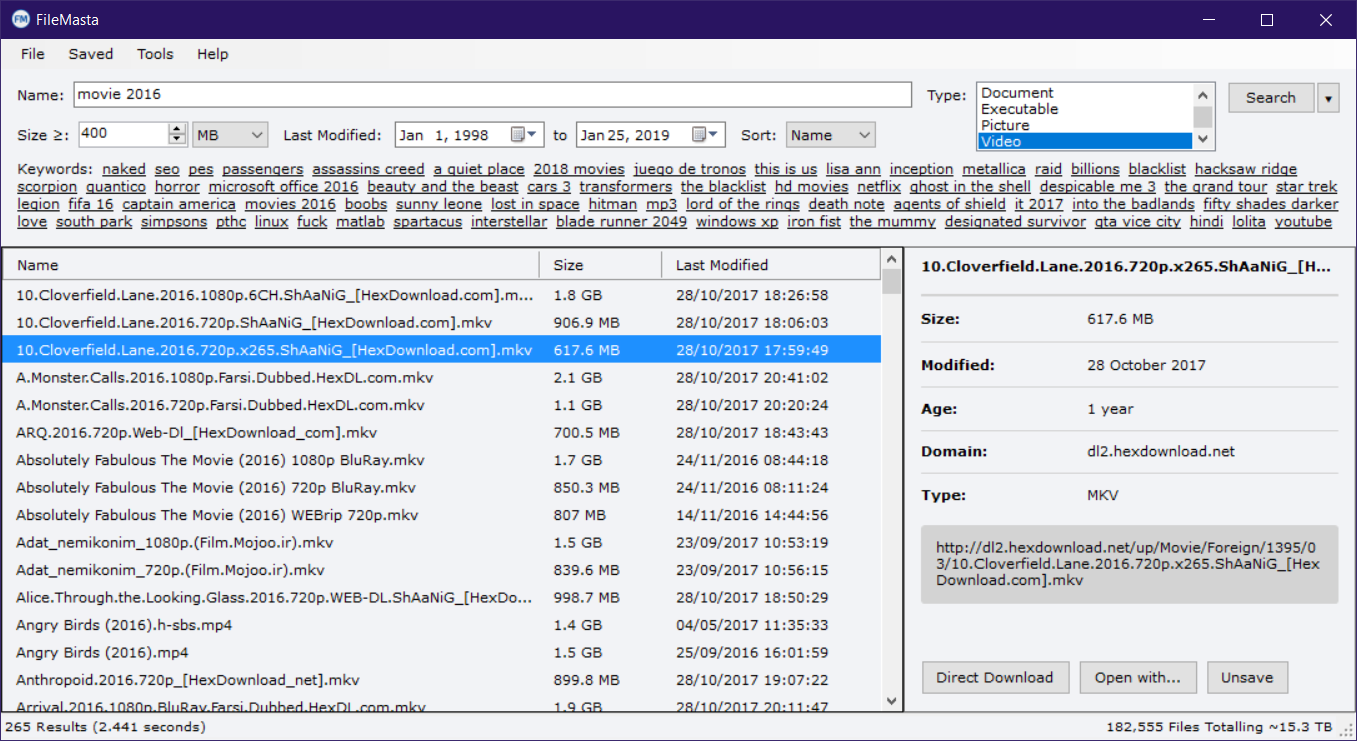
Eine Verbundsuchanwendung zum Entdecken interessanter Dateien, die online geteilt werden, wie z. B. Videos, Musik, Bücher, Software, Spiele, Untertitel und vieles mehr. Alle Daten werden von der od-database gecrawlt, die Informationen über die Inhalte von Servern weltweit sammelt. Wir durchsuchen keine Dateiinhalte.
Wir hosten keine Inhalte, sondern bieten nur Zugriff auf bereits verfügbare Dateien, genau wie Google und andere Suchmaschinen.
Ich suche derzeit jemanden, der dieses Projekt unterstützt, etwa das Laden beschleunigt und schnellere Suchergebnisse erhält. Bitte senden Sie mir eine E-Mail, wenn Sie glauben, dass Sie mit mir daran arbeiten möchten.
Laden Sie die neueste Version des Installationsprogramms von der Release-Seite herunter und führen Sie sie aus.
Wenn Sie einen Fehler finden oder eine Funktionsanfrage haben, erstellen Sie bitte ein Problem.
Beiträge sind jedoch sehr willkommen, außer bei sehr kleinen Änderungen. Reichen Sie bitte ein Problem ein und lassen Sie uns darüber diskutieren, bevor Sie eine Pull-Anfrage öffnen.
Dafür kann es mehrere Gründe geben:
Sie benötigen kein spezielles Programm, es ist jedoch sehr zu empfehlen. Wenn Sie beispielsweise einfach den Link in Ihrem Webbrowser öffnen, können Sie nicht sehen, was genau zwischen Ihnen und dem Webserver passiert (siehe vorherige Frage). Daher würde ich empfehlen, einen guten Web-Client zu verwenden, der Warteschlangen unterstützt, oder Ihren bevorzugten Download-Manager. Wenn Sie die Datei gefunden haben, die Sie herunterladen möchten, kopieren Sie einfach den Link und fügen Sie ihn in Ihren Web-Client ein oder was auch immer, das war’s.
Dieses Projekt ist unter der General Public License v3 lizenziert.


