pianola
1.0.0
 Pianola in Aktion" style="max-width: 100%;">
Pianola in Aktion" style="max-width: 100%;">
pianola ist eine Anwendung, die KI-generierte Klaviermusik abspielt. Benutzer setzen das KI-Modell in Gang (d. h. „fordern es auf“), indem sie Noten auf der Tastatur spielen oder Beispielausschnitte aus klassischen Stücken auswählen.
In dieser Readme-Datei erklären wir die Funktionsweise der KI und gehen detailliert auf die Architektur des Modells ein.
Musik kann auf viele Arten dargestellt werden, von rohen Audiowellenformen bis hin zu halbstrukturierten MIDI-Standards. Beim pianola unterteilen wir musikalische Takte in regelmäßige, gleichmäßige Intervalle (z. B. Sechzehntelnoten/Sechzehntelnoten). Noten, die innerhalb eines Intervalls gespielt werden, gelten als zum selben Zeitschritt gehörend, und eine Reihe von Zeitschritten bildet eine Sequenz. Unter Verwendung der gitterbasierten Sequenz als Eingabe sagt das KI-Modell die Noten im nächsten Zeitschritt voraus, die wiederum als Eingabe für die Vorhersage des nachfolgenden Zeitschritts auf autoregressive Weise verwendet werden.
Zusätzlich zu den zu spielenden Noten sagt das Modell auch die Dauer (Dauer, wie lange die Note gedrückt wird) und die Geschwindigkeit (wie stark eine Taste angeschlagen wird) jeder Note voraus.
Das Modell besteht aus drei Modulen: einem Einbetter, einem Transformator und einem Decoder. Diese Module lehnen sich an bekannte Architekturen wie Inception-Netzwerke, LLaMA-Transformatoren und Multi-Label-Klassifikatorketten an, sind jedoch für die Arbeit mit Musikdaten angepasst und in einem neuartigen Ansatz kombiniert.
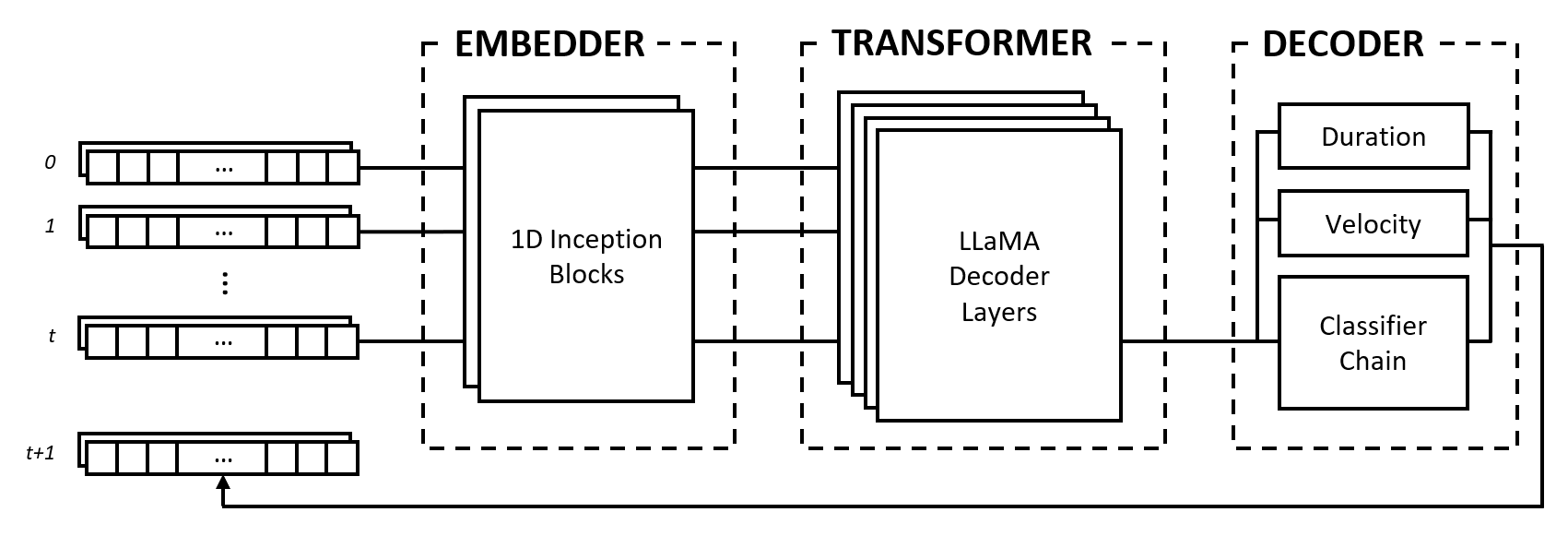
Der Einbetter wandelt jeden Eingabezeitschritt der Form (num_notes, num_features) in einen Einbettungsvektor um, der in den Transformator eingespeist werden kann. Im Gegensatz zu Texteinbettungen, die One-Hot-Vektoren einem anderen dimensionalen Raum zuordnen, sorgen wir jedoch für eine induktive Verzerrung, indem wir Faltungs- und Pooling-Ebenen auf die Eingabe anwenden. Wir tun dies aus mehreren Gründen:
2^num_notes , wobei num_notes 64 oder 88 für kurze bis normale Klaviere ist), daher ist es nicht möglich, sie als One-Hot-Vektoren darzustellen.Damit der Einbetter lernen kann, welche Abstände nützlich sind, lassen wir uns von Inception-Netzwerken inspirieren und stapeln Faltungen unterschiedlicher Kernelgrößen.
Das Transformatormodul besteht aus LLaMA-Transformatorschichten, die Selbstaufmerksamkeit auf die Sequenz der Eingabeeinbettungsvektoren anwenden.
Wie viele generative KI-Modelle verwendet dieses Modul nur den „Decoder“-Teil des ursprünglichen Transformers-Modells von Vaswani et al. (2017). Wir verwenden hier die Bezeichnung „Transformator“, um dieses Modul vom folgenden zu unterscheiden, das die eigentliche Dekodierung der von den Selbstaufmerksamkeitsschichten erzeugten Zustände übernimmt.
Wir wählen die LLaMA-Architektur gegenüber anderen Transformatortypen vor allem deshalb, weil sie Rotary Positional Embeddings (RoPE) verwendet, das relative Positionen mit Entfernungsabfall über Zeitschritte kodiert. Da wir Musikdaten als feste Intervalle darstellen, sind die relativen Positionen sowie Abstände zwischen Zeitschritten wichtige Informationen, die der Transformator explizit nutzen kann, um Musik mit konsistentem Rhythmus zu verstehen und zu erzeugen.
Der Decoder erfasst die besuchten Zustände und sagt die zu spielenden Noten zusammen mit ihrer Dauer und Geschwindigkeit voraus. Das Modul besteht aus mehreren Unterkomponenten, nämlich einer Klassifikatorkette zur Notenvorhersage und mehrschichtigen Perzeptronen (MLPs) zur Merkmalsvorhersage.
Die Klassifikatorkette besteht aus binären Klassifikatoren num_notes , also einem für jede Taste auf einem Klavier, um einen Klassifikator mit mehreren Bezeichnungen zu erstellen. Um Korrelationen zwischen Notizen zu nutzen, werden die binären Klassifikatoren miteinander verkettet, sodass das Ergebnis früherer Notizen die Vorhersagen für die folgenden Notizen beeinflusst. Wenn beispielsweise eine positive Korrelation zwischen Oktavnoten besteht, führt eine aktive tiefere Note (z. B. C3 ) zu einer höheren Wahrscheinlichkeit, dass die höhere Note (z. B. C4 ) vorhergesagt wird. Dies ist auch in Fällen negativer Korrelationen von Vorteil, wenn man zwischen zwei benachbarten Noten wählen kann, die entweder eine Dur- oder eine Moll-Tonleiter ergeben (z. B. CDE vs. CD-Eb ), aber nicht beides.
Aus Gründen der Recheneffizienz begrenzen wir die Länge der Kette auf 12 Glieder, also eine Oktave. Schließlich wird eine Sampling-Dekodierungsstrategie verwendet, um Noten im Verhältnis zu ihren Vorhersagewahrscheinlichkeiten auszuwählen.
Die Dauer- und Geschwindigkeitsmerkmale werden als Regressionsprobleme behandelt und mithilfe von Vanilla-MLPs vorhergesagt. Während die Features für jede Notiz vorhergesagt werden, verwenden wir während des Trainings eine benutzerdefinierte Verlustfunktion, die nur Feature-Verluste aus aktiven Notizen aggregiert, ähnlich der Verlustfunktion, die bei einer Bildklassifizierung mit Lokalisierungsaufgabe verwendet wird.
Unsere Entscheidung, Musikdaten als Raster darzustellen, hat Vor- und Nachteile. Wir diskutieren diese Punkte, indem wir sie mit dem von Oore et al. vorgeschlagenen ereignisbasierten Vokabular vergleichen. (2018), ein viel zitierter Beitrag zur Musikgenerierung.
Einer der Hauptvorteile unseres Ansatzes ist die Entkopplung des Mikro- und Makroverständnisses von Musik, was zu einer klaren Aufgabentrennung zwischen Einbetter und Transformator führt. Die Aufgabe des ersteren besteht darin, die Interaktion von Noten auf einer Mikroebene zu interpretieren, beispielsweise wie die relativen Abstände zwischen den Noten musikalische Beziehungen wie Akkorde bilden, und die Aufgabe des letzteren besteht darin, diese Informationen über die Zeitdimension zu synthetisieren, um den Musikstil auf einer Makroebene zu verstehen Ebene.
Im Gegensatz dazu überlässt eine ereignisbasierte Darstellung einem Sequenzmodell die gesamte Last, One-Hot-Tokens zu interpretieren, die Tonhöhe, Timing oder Geschwindigkeit, drei unterschiedliche Konzepte, darstellen könnten. Huang et al. (2018) stellen fest, dass es notwendig ist, ihrem Transformer-Modell einen relativen Aufmerksamkeitsmechanismus hinzuzufügen, um kohärente Fortsetzungen zu erzeugen, was darauf hindeutet, dass das Modell eine induktive Vorspannung erfordert, um mit dieser Darstellung gut zu funktionieren.
In einer Rasterdarstellung ist die Wahl der Intervalllänge ein Kompromiss zwischen Datentreue und Sparsität. Ein längeres Intervall verringert die Granularität des Notentimings, verringert die musikalische Ausdruckskraft und komprimiert möglicherweise schnelle Elemente wie Triller und wiederholte Noten. Andererseits erhöht ein kürzeres Intervall die Sparsity exponentiell, indem viele leere Zeitschritte eingeführt werden, was für Transformer-Modelle ein erhebliches Problem darstellt, da sie in der Sequenzlänge eingeschränkt sind.
Darüber hinaus können Musikdaten einem Raster zugeordnet werden, entweder über den Zeitablauf ( 1 timestep == X milliseconds 1 timestep == 1 sixteenth note/semiquaver . Eine ereignisbasierte Darstellung vermeidet diese Probleme vollständig, indem sie den Zeitablauf als Ereignis spezifiziert.
Trotz ihrer Nachteile hat die Rasterdarstellung einen praktischen Vorteil, da sie bei der Entwicklung von pianola viel einfacher zu handhaben ist. Die Modellausgabe ist für Menschen lesbar und die Anzahl der Zeitschritte entspricht einer festen Zeitspanne, wodurch die Entwicklung neuer Funktionen erheblich beschleunigt wird.
Darüber hinaus werden Forschungen zur Erweiterung der Sequenzlängen von Transformer-Modellen und kontinuierliche Verbesserungen der Hardware die durch Datenknappheit verursachten Probleme schrittweise reduzieren, und ab Ende 2023 sehen wir große Sprachmodelle, die Zehntausende von Token verarbeiten können. Mit der Optimierung der Techniken und der zunehmenden Zugänglichkeit leistungsstarker Hardware glauben wir, dass sich die Wiedergabetreue weiter verbessern wird, genau wie bei der Bilderzeugung, was zu größerer Ausdruckskraft und Nuancen bei KI-generierter Musik führen wird.
Der Quellcode dieses Projekts ist zum Zwecke der akademischen Forschung und des Wissensaustauschs öffentlich einsehbar. Alle Rechte verbleiben bei den Erstellern, sofern keine ausdrücklichen Genehmigungen erteilt wurden.
Site-Symbol geändert von Freepik - Flaticon.
Kontaktieren Sie uns auf outlook.com unter der Adresse bruce <dot> ckc .


