nnl
gpt2-xl assets
nnl ist eine Inferenz-Engine für große Modelle auf einer GPU-Plattform mit wenig Speicher.
Große Modelle sind zu groß, um in den GPU-Speicher zu passen. nnl behebt dieses Problem durch einen Kompromiss zwischen PCIE-Bandbreite und Speicher.
Eine typische Inferenzpipeline sieht wie folgt aus:
Mit dem GPU-Speicherpool und der Speicherdefragmentierung ermöglicht NNIL den Rückschluss auf ein großes Modell auf einer Low-End-GPU-Plattform.
Dies ist nur ein Hobbyprojekt, das in ein paar Wochen geschrieben wurde. Derzeit wird nur das CUDA-Backend unterstützt.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aDieser Befehl erstellt die beiden statischen Bibliotheken: lib/lib nnl _cuda.a und lib/lib nnl _cuda_kernels.a . Die erste ist die Kernbibliothek mit CUDA-Backend in C++ und die zweite ist für die CUDA-Kernel.
Ein Demoprogramm von GPT2-XL (1.6B) wird hier bereitgestellt. Dieses Programm kann mit diesem Befehl kompiliert werden:
make gpt2_1558mNachdem wir alle Gewichte aus der Version heruntergeladen haben, können wir den folgenden Befehl auf einer Low-End-GPU-Plattform wie GTX 1050 (2 GB Speicher) ausführen:
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " Und die Ausgabe sieht so aus: 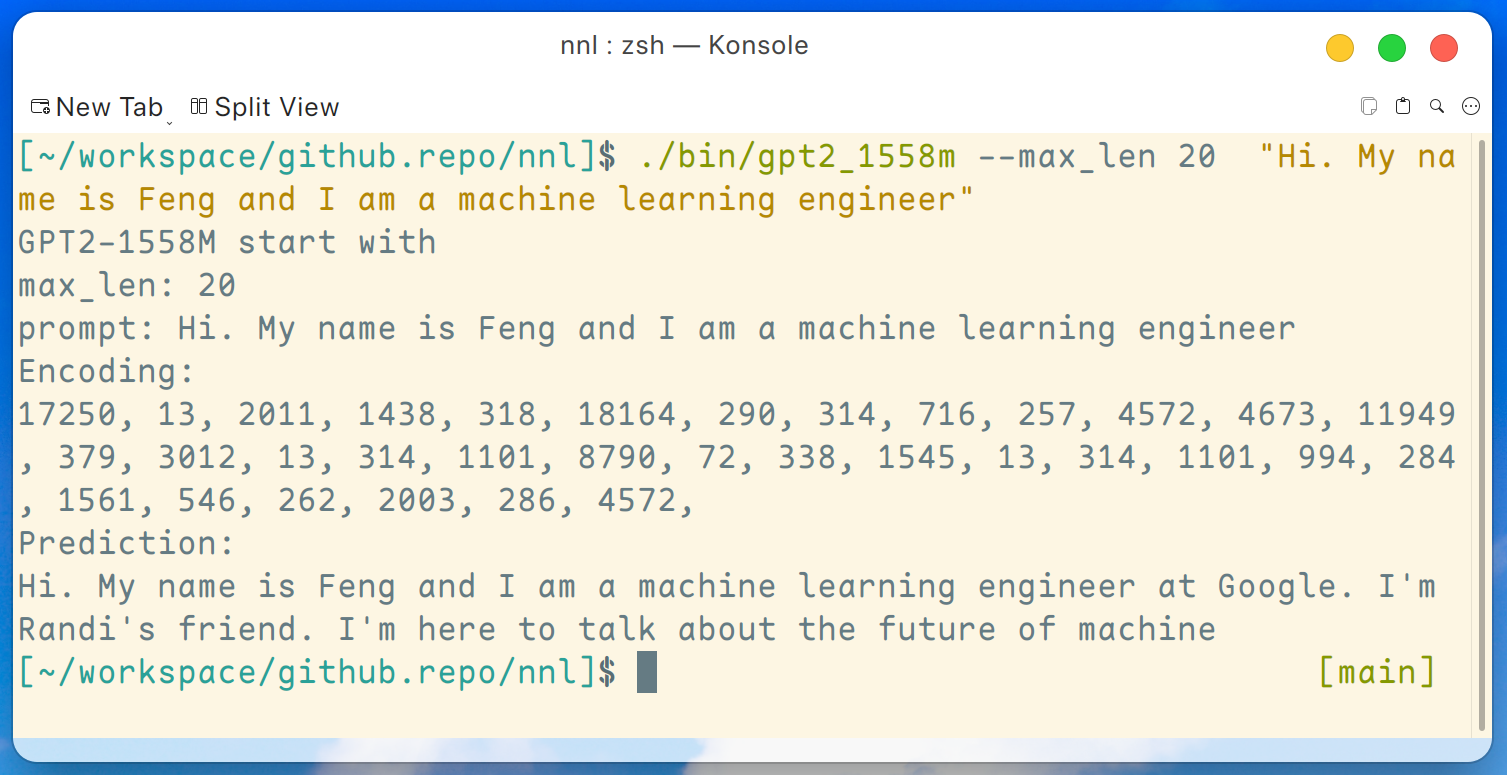
Haftungsausschluss: Dies ist nur ein von gpt2-xl generiertes Beispiel. Ich arbeite nicht bei Google und kenne Randi nicht.
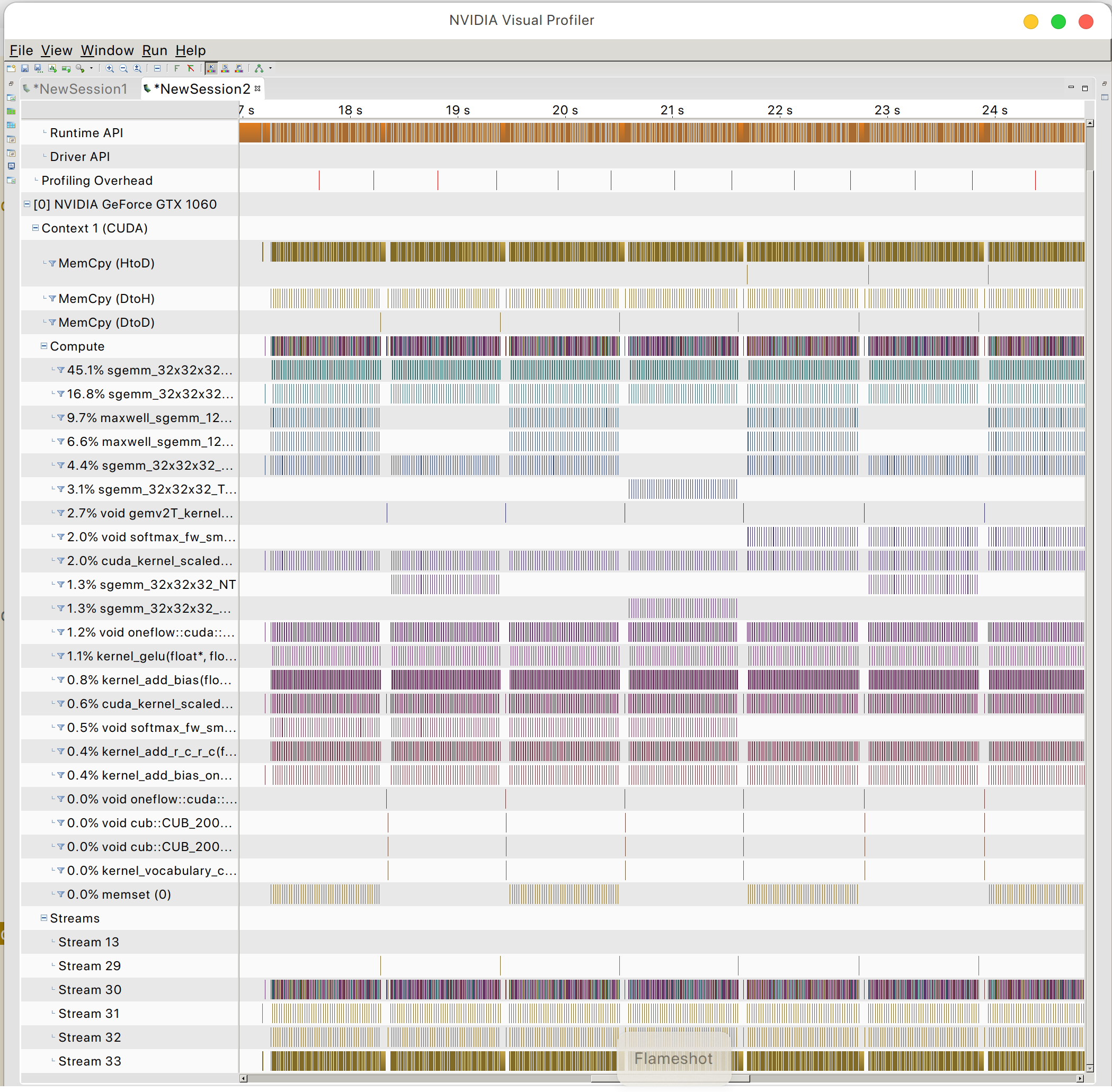
Und Sie können das GPU-Speicherzugriffsmuster finden
PeaceOSL