UniIR
1.0.0
Startseite | ? Datensatz (M-BEIR-Benchmark) | ? Kontrollpunkte ( UniIR Modelle) | arXiv | GitHub
Dieses Repo enthält die Codebasis für das ECCV-2024-Papier „ UniIR : Training and Benchmarking Universal Multimodal Information Retrievers“.
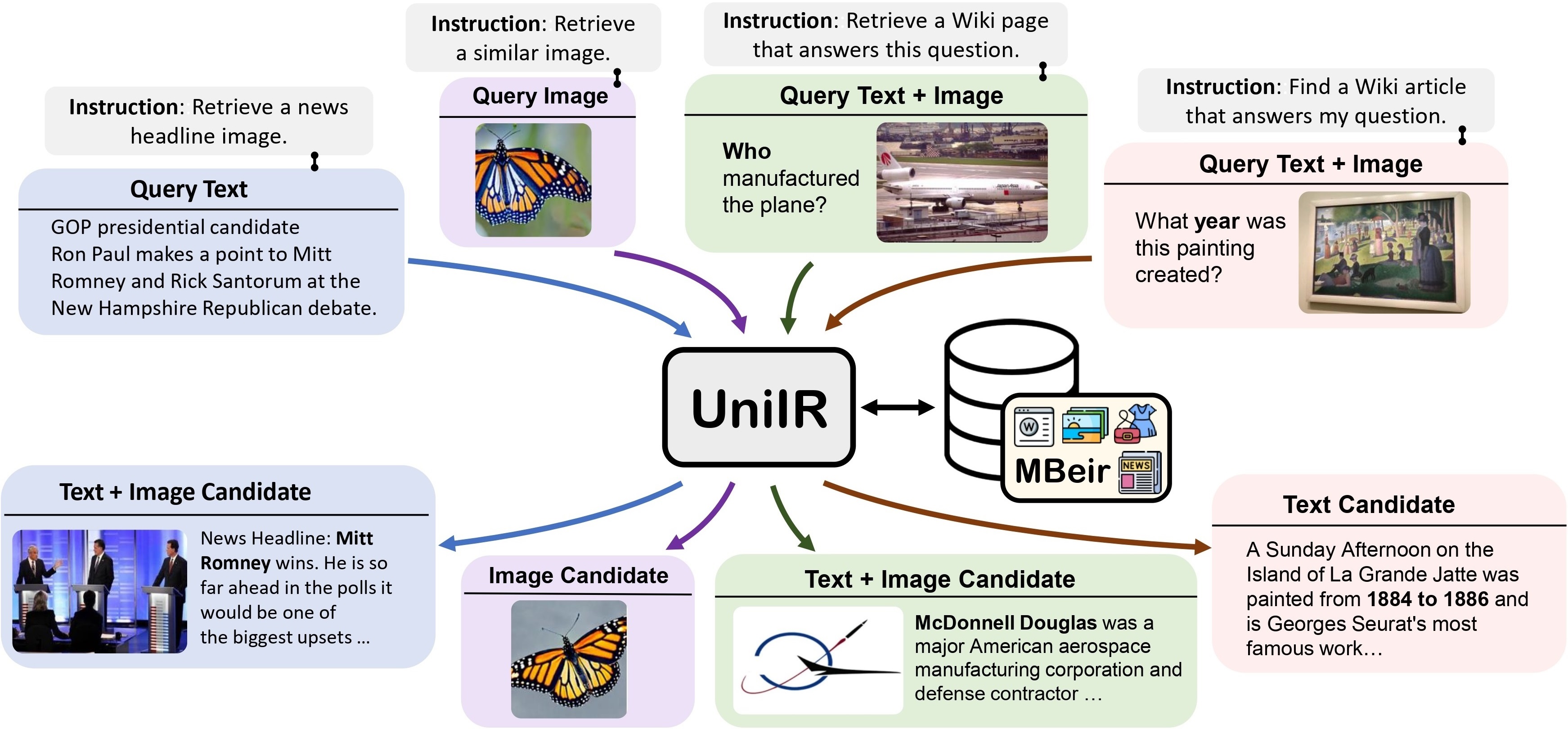
Wir schlagen das UniIR Framework (Universal Multimodal Information Retrieval) vor, um einem einzelnen Retriever beizubringen, (möglicherweise) jede Retrieval-Aufgabe zu erfüllen. Im Gegensatz zu herkömmlichen IR-Systemen muss UniIR den Anweisungen folgen, um eine heterogene Abfrage aus einem heterogenen Kandidatenpool mit Millionen von Kandidaten in verschiedenen Modalitäten abzurufen.
 UniIR-Teaser" style="width: 80%; maximale Breite: 100 %;">
UniIR-Teaser" style="width: 80%; maximale Breite: 100 %;">
Um universelle multimodale Retrieval-Modelle zu trainieren und zu bewerten, erstellen wir einen groß angelegten Retrieval-Benchmark namens M-BEIR (Multimodal BEnchmark for Instructed Retrieval).
Wir stellen den M-BEIR-Datensatz im ? Datensatz . Bitte befolgen Sie die Anweisungen auf der HF-Seite, um den Datensatz herunterzuladen und die Daten für das Training und die Auswertung vorzubereiten. Sie müssen GiT LFS einrichten und das Repo direkt klonen:
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
Wir stellen die Codebasis für das Training und die Evaluierung der UniIR -Modelle CLIP-ScoreFusion, CLIP-FeatureFusion, BLIP-ScoreFusion und BLIP-FeatureFusion bereit.
Bereiten Sie die Codebasis des UniIR -Projekts und der Conda-Umgebung mit den folgenden Befehlen vor:
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.ymlUm die UniIR Modelle anhand vorab trainierter CLIP- und BLIP-Kontrollpunkte zu trainieren, befolgen Sie bitte die nachstehenden Anweisungen. Die Skripte laden automatisch die vorab trainierten CLIP- und BLIP-Prüfpunkte herunter.
Bitte laden Sie den M-BEIR-Benchmark herunter, indem Sie den Anweisungen im Abschnitt M-BEIR folgen.
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/ Ändern Sie inbatch.yaml für die Optimierung von Hyperparametern und run_inbatch.sh für Ihre eigene Umgebung und Pfade.
UniIR _DIR in run_inbatch.sh in das Verzeichnis, in dem Sie die Prüfpunkte speichern möchten.MBEIR_DATA_DIR in run_inbatch.sh in das Verzeichnis, in dem Sie den M-BEIR-Benchmark speichern.SRC_DIR in run_inbatch.sh in das Verzeichnis, in dem Sie die Codebasis des UniIR -Projekts (dieses Repo) speichern..env Umgebung mit WANDB_API_KEY , WANDB_PROJECT und WANDB_ENTITY festgelegt ist.Anschließend können Sie den folgenden Befehl ausführen, um das UniIR CLIP_SF Large-Modell zu trainieren.
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/ Ändern Sie inbatch.yaml für die Optimierung von Hyperparametern und run_inbatch.sh für Ihre eigene Umgebung und Pfade.
bash run_inbatch.shWir stellen die Evaluierungspipeline für die UniIR -Modelle auf dem M-BEIR-Benchmark bereit.
Bitte erstellen Sie eine Umgebung für die FAISS-Bibliothek:
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.ymlBitte laden Sie den M-BEIR-Benchmark herunter, indem Sie den Anweisungen im Abschnitt M-BEIR folgen.
Sie können die UniIR Modelle von Grund auf trainieren oder die vorab trainierten UniIR Kontrollpunkte herunterladen, indem Sie den Anweisungen im Abschnitt „Modell-Zoo“ folgen.
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/ Ändern Sie embed.yaml , index.yaml , retrieval.yaml und run_eval_pipeline_inbatch.sh für Ihre eigene Umgebung, Pfade und Auswertungseinstellungen.
UniIR _DIR in run_eval_pipeline_inbatch.sh in das Verzeichnis, in dem Sie große Dateien speichern möchten, einschließlich der Prüfpunkte, Einbettungen, Index- und Abrufergebnisse. Anschließend können Sie die Datei clip_sf_large.pth im folgenden Pfad ablegen: $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthmodel.ckpt_config in der Datei embed.yaml angegeben wird.MBEIR_DATA_DIR in run_eval_pipeline_inbatch.sh in das Verzeichnis, in dem Sie den M-BEIR-Benchmark speichern.SRC_DIR in run_eval_pipeline_inbatch.sh in das Verzeichnis, in dem Sie die Codebasis des UniIR -Projekts speichern (dieses Repo). Die Standardkonfiguration bewertet das UniIR CLIP_SF Large-Modell sowohl anhand der Benchmarks M-BEIR (5,6 Mio. heterogener Kandidatenpool) als auch M-BEIR_local (homogener Kandidatenpool). UNION in den Yaml-Dateien bezieht sich auf M-BEIR (5,6 Mio. heterogener Kandidatenpool). Sie können den Kommentaren in den Yaml-Dateien folgen und die Konfigurationen ändern, um das Modell nur im M-BEIR_local-Benchmark zu bewerten.
bash run_eval_pipeline_inbatch.sh embed , index , logger und retrieval_results werden im Verzeichnis $ UniIR _DIR gespeichert.
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/ Wenn Sie unser vorab trainiertes UniIR -Modell herunterladen, können Sie die Datei blip_ff_large.pth ebenfalls im folgenden Pfad platzieren:
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pthDie Standardkonfiguration bewertet das UniIR BLIP_FF Large-Modell sowohl im M-BEIR- als auch im M-BEIR_local-Benchmark.
bash run_eval_pipeline_inbatch.shDie UniRAG-Auswertung ist der Standardauswertung mit den folgenden Unterschieden sehr ähnlich:
retrieval_results . Dies ist nützlich, wenn die abgerufenen Ergebnisse in nachgelagerten Anwendungen wie RAG verwendet werden.retrieve_image_text_pairs in retrieval.yaml auf True gesetzt ist, wird für jeden Kandidaten mit der Nur text oder image -Modalität ein Komplementkandidat abgerufen. Mit dieser Einstellung verfügen der Kandidat und seine Ergänzung immer über image, text . Komplementkandidaten werden abgerufen, indem die ursprünglichen Kandidaten als Abfragen verwendet werden (z. B. Abfragetext -> Kandidatenbild -> Komplementkandidatentext ).InBatch und inbatch durch UniRAG bzw. unirag . Wir stellen die Checkpoints UniIR Modells im ? Kontrollpunkte . Sie können die Prüfpunkte direkt für Abrufaufgaben verwenden oder die Modelle für Ihre eigenen Abrufaufgaben optimieren.
| Modellname | Version | Modellgröße | Modelllink |
|---|---|---|---|
| UniIR (CLIP-SF) | Groß | 5,13 GB | Download-Link |
| UniIR (BLIP-FF) | Groß | 7,49 GB | Download-Link |
Sie können sie hier herunterladen
git clone https://huggingface.co/TIGER-Lab/UniIR
BibTeX:
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

