DiSQ Score
1.0.0
Offizielle Umsetzung für unseren Aufsatz: Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations (2024) Yisong Miao, Hongfu Liu, Wenqiang Lei, Nancy F. Chen, Min-Yen Kan. ACL 2024.
Papier-PDF: https://yisong.me/publications/acl24-DiSQ-CR.pdf
Folien: https://yisong.me/publications/acl24-DiSQ-Slides.pdf
Poster: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
Möchten Sie den DiSQ Score für ein beliebiges Sprachmodell erfahren? Gerne können Sie diesen einzeiligen Befehl verwenden!

Wir bieten einen vereinfachten Befehl zum Auswerten aller Sprachmodelle (LM), die im HuggingFace-Modell-Hub gehostet wurden. Es wird empfohlen, dies für jedes neue Modell zu verwenden (insbesondere für diejenigen, die in unserer Arbeit nicht untersucht wurden).
bash scripts/one_model.sh <modelurl>
Die Variable modelurl gibt den verkürzten Pfad im Huggingface-Hub an, zum Beispiel:
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
Bevor Sie die Bash-Dateien ausführen, bearbeiten Sie bitte die Bash-Datei, um Ihren Pfad zu Ihrem lokalen HuggingFace-Cache anzugeben.
Zum Beispiel in scripts/one_model.sh:
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
Sie können YOUR_PATH in den absoluten Verzeichnisspeicherort Ihres Huggingface-Cache ändern (z. B. /disk1/yisong/hf-cache ).
Wir empfehlen mindestens 200 GB freien Speicherplatz.
Unter data/results/verbalizations/Meta-Llama-3-8B.txt wird eine Ausgabetextdatei gespeichert, die Folgendes enthält:
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
Wir speichern unsere Datensätze in JSON-Dateien unter data/datasets/dataset_pdtb.json und data/datasets/dataset_ted.json . Nehmen wir zum Beispiel eine Instanz aus dem PDTB-Datensatz:
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
Hier sind die Felder in diesem Wörterbucheintrag:
Didx : Die Diskurs-ID.arg1 und arg2 : Die beiden Argumente.DR : Die Diskursrelation.Conn : Der Diskurskonnektiv.events : Eine Liste von Paaren, in der die als hervorstechende Signale vorhergesagten Ereignispaare gespeichert werden.context : Der Diskurskontext. cd DiSQ-Score
bash scripts/question_generation.sh
Diese Bash-Datei ruft question_generation.py auf, um Fragen unter verschiedenen Konfigurationen zu generieren.
Die Argumente für question_generation.py lauten wie folgt:
--dataset : Gibt den Datensatz an, entweder pdtb oder ted .--modelname : Aliase für Modelle wurden erstellt. 13b bezieht sich auf LLaMA2-13B, 13bchat auf LLaMA2-13B-Chat und vicuna-13b auf Vicuna-13B. Die spezifischen URLs für diese Modelle finden Sie in disq_config.py .--version : Gibt mit den Optionen v1 , v2 , v3 und v4 an, welche Version der Eingabeaufforderungsvorlagen verwendet werden soll.--paraphrase : Ersetzt die Standardfragen durch ihre umschriebenen Versionen mit den Optionen p1 und p2 . Im Gegensatz zu den Standardfunktionen, die qa_utils.py aufrufen, rufen die paraphrasierten Funktionen jeweils qa_utils_p1.py und qa_utils_p2.py auf.--feature : Gibt an, welche Sprachfunktionen für die Diskussionsfragen verwendet werden sollen. Zu den sprachlichen Merkmalen gehören conn (Diskurskonnektiv) und context (Diskurskontext). Für historische QA-Daten ist ein separates Skript erforderlich. Die Ausgabe wird beispielsweise unter data/questions/dataset_pdtb_prompt_v1.json unter der Konfiguration dataset==pdtb und version==v1 gespeichert.
Wir bitten unsere Benutzer, die Fragen selbst zu generieren, da dieser Ansatz automatisch erfolgt und dabei hilft, Platz in unserem GitHub-Repository zu sparen (der bis zu ca. 200 MB betragen könnte). Wenn Sie die Bash-Datei nicht ausführen können, kontaktieren Sie uns bitte für die Fragedateien.
cd DiSQ-Score
bash scripts/question_answering.sh
Diese Bash-Datei ruft question_answering.py auf, um „Discursive Socratic Questioning“ (DiSQ) für ein beliebiges Modell durchzuführen. question_answering.py übernimmt alle Argumente von question_generation.py sowie die folgenden neuen Argumente:
--modelurl : Gibt die URL für alle neuen Modelle an, die derzeit nicht in der Konfigurationsdatei enthalten sind. Beispielsweise gibt „meta-llama/Meta-Llama-3-8B“ das LLaMA3-8B-Modell an und überschreibt das Argument modelname .--hf-path : Gibt den Pfad zum Speichern der großen Modellparameter an. Es werden mindestens 200 GB freier Speicherplatz empfohlen.--device_number : Gibt die ID der zu verwendenden GPU an. Die Ausgabe wird beispielsweise unter data/results/13bchat_dataset_pdtb_prompt_v1/ gespeichert. Die Vorhersage für jede Frage ist eine Liste von Tokens und deren Wahrscheinlichkeiten, die in einer Pickle-Datei im Ordner gespeichert werden.
Vorsichtsmaßnahme: Das Wizard-Modell wurde von den Entwicklern entfernt. Wir raten Benutzern davon ab, diese Modelle auszuprobieren. Schauen Sie sich den Diskussionsthread an: https://huggingface.co/posts/WizardLM/329547800484476.
cd DiSQ-Score
bash scripts/eval.sh
Diese Bash-Datei ruft eval.py auf, um die zuvor erhaltenen Modellvorhersagen auszuwerten.
eval.py verwendet denselben Parametersatz wie question_answering.py .
Das Ergebnis der Auswertung wird in disq_score_pdtb.csv gespeichert, wenn der angegebene Datensatz PDTB ist.
Die CSV-Datei enthält 20 Spalten, nämlich:
taskcode : Gibt die getestete Konfiguration an, z. B. dataset_pdtb_prompt_v1_13bchat .modelname : Gibt an, welches Sprachmodell getestet wird.version : Gibt die Version der Eingabeaufforderung an.paraphrase : Der Parameter für Paraphrase.feature : Gibt an, welche Funktion verwendet wurde.Overall : Der Gesamt- DiSQ Score .Targeted : Gezielte Punktzahl, eine der drei Komponenten im DiSQ Score .Counterfactual : Kontrafaktischer Score, eine der drei Komponenten im DiSQ Score .Consistency : Konsistenzbewertung, eine der drei Komponenten im DiSQ Score .Comparison.Concession : Der DiSQ Score für diese spezifische Diskursbeziehung.Beachten Sie, dass wir die besten Ergebnisse zwischen den Versionen v1 bis v4 auswählen, um die Auswirkungen von Eingabeaufforderungsvorlagen zu minimieren.
Dazu extrahiert eval.py automatisch die besten Ergebnisse:
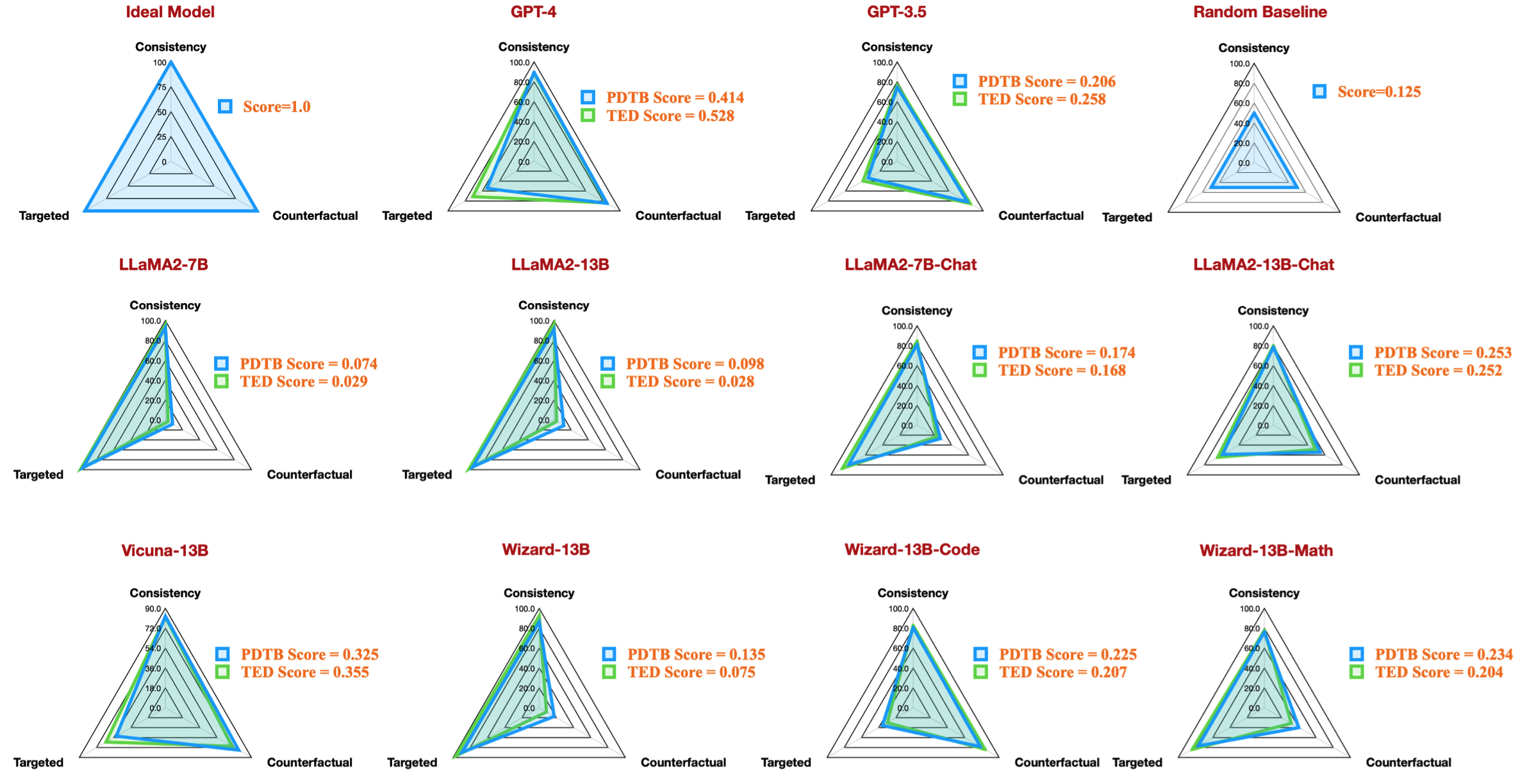
| Taskcode | Modellname | Version | Paraphrase | Besonderheit | Gesamt | Gezielt | Kontrafaktisch | Konsistenz | Vergleich.Konzession | Vergleich.Kontrast | Kontingenz. Grund | Kontingenz.Ergebnis | Expansion.Konjunktion | Erweiterung.Äquivalenz | Erweiterung.Instantiierung | Erweiterung. Detaillierungsgrad | Erweiterung.Substitution | Zeitlich.Asynchron | Zeitlich.Synchron |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_pdtb_prompt_v4_7b | 7b | v4 | 0,074 | 0,956 | 0,084 | 0,929 | 0,03 | 0,083 | 0,095 | 0,095 | 0,077 | 0,054 | 0,086 | 0,068 | 0,155 | 0,036 | 0,047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7bchat | v1 | 0,174 | 0,794 | 0,271 | 0,811 | 0,231 | 0,435 | 0,132 | 0,173 | 0,214 | 0,105 | 0,121 | 0,15 | 0,199 | 0,107 | 0,04 | ||
| dataset_pdtb_prompt_v2_13b | 13b | v2 | 0,097 | 0,945 | 0,112 | 0,912 | 0,037 | 0,099 | 0,081 | 0,094 | 0,126 | 0,101 | 0,113 | 0,107 | 0,077 | 0,083 | 0,093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13bchat | v1 | 0,253 | 0,592 | 0,545 | 0,785 | 0,195 | 0,485 | 0,129 | 0,173 | 0,289 | 0,155 | 0,326 | 0,373 | 0,285 | 0,194 | 0,028 | ||
| dataset_pdtb_prompt_v2_vicuna-13b | Vicuna-13b | v2 | 0,325 | 0,512 | 0,766 | 0,829 | 0,087 | 0,515 | 0,201 | 0,352 | 0,369 | 0,0 | 0,334 | 0,46 | 0,199 | 0,511 | 0,074 |
Diese Tabelle zeigt beispielsweise das beste Ergebnis für PDTB-Datensätze für verfügbare Open-Source-Modelle, die die Radarzahl in unserem Artikel reproduzieren:
Wir bieten auch Anleitungen zur Bewertung von Diskussionsfragen zu sprachlichen Merkmalen:
--feature als conn und context in question_generation.py an (Schritt 1) und führen Sie alle Experimente erneut aus.question_generation_history.py aus. Dieses Skript extrahiert Antworten aus den gespeicherten QA-Ergebnissen und generiert neue Fragen.Für die meisten NLP-Benutzer ist es wahrscheinlich möglich, unseren Code mit Ihren vorhandenen virtuellen (Conda-)Umgebungen auszuführen.
Als wir unsere Experimente durchführten, waren die Paketversionen wie folgt:
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
Wir haben jedoch beobachtet, dass neuere Modelle aktualisierte Paketversionen erfordern:
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
Wenn Sie unsere Arbeit interessant finden, sind Sie herzlich eingeladen, unseren Datensatz/Codebasis auszuprobieren.
Bitte zitieren Sie unsere Forschung, wenn Sie unseren Datensatz/Codebasis verwendet haben:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
Wenn Sie Fragen oder Fehlerberichte haben, melden Sie bitte ein Problem oder kontaktieren Sie uns direkt per E-Mail:
E-Mail-Adresse: ?@?
wobei ?️= yisong , ?= comp.nus.edu.sg
CC von 4.0


