Patron
1.0.0
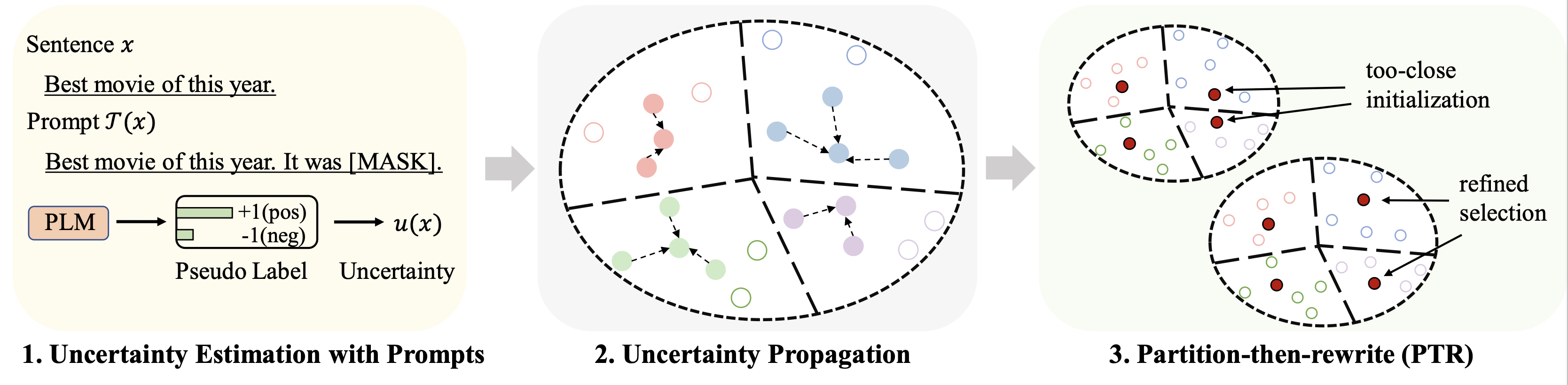
Dieses Repo enthält den Code für unser ACL 2023-Papier „Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach“.
Die Ergebnisse verschiedener Datensätze (unter Verwendung von 128 Labels als Budget) zur Feinabstimmung werden wie folgt zusammengefasst:
| Verfahren | IMDB | Yelp-voll | AGNews | Yahoo! | DBPedia | TREC | Bedeuten |
|---|---|---|---|---|---|---|---|
| Vollständige Betreuung (RoBERTa-Basis) | 94.1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88.1 |
| Zufallsstichprobe | 86,6 | 47,7 | 84,5 | 60.2 | 95,0 | 85,6 | 76,7 |
| Beste Baseline (Chang et al. 2021) | 88,5 | 46.4 | 85,6 | 61.3 | 96,5 | 87,7 | 77,6 |
| Patron (unser) | 89,6 | 51.2 | 87,0 | 65.1 | 97,0 | 91.1 | 80.2 |
Für prompt-basiertes Lernen verwenden wir dieselbe Pipeline wie das LM-BFF. Das Ergebnis mit 128 Etiketten wird wie folgt dargestellt.
| Verfahren | IMDB | Yelp-voll | AGNews | Yahoo! | DBPedia | TREC | Bedeuten |
|---|---|---|---|---|---|---|---|
| Vollständige Betreuung (RoBERTa-Basis) | 94.1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88.1 |
| Zufallsstichprobe | 87,7 | 51.3 | 84,9 | 64,7 | 96,0 | 85,0 | 78,2 |
| Beste Basislinie (Yuan et al., 2020) | 88,9 | 51.7 | 87,5 | 65,9 | 96,8 | 86,5 | 79,5 |
| Patron (unser) | 89,3 | 55,6 | 87,8 | 67,6 | 97,4 | 88,9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
Für die Hauptexperimente verwenden wir die folgenden vier Datensätze.
| Datensatz | Aufgabe | Anzahl der Klassen | Anzahl unbeschrifteter Daten/Testdaten |
|---|---|---|---|
| IMDB | Gefühl | 2 | 25k/25k |
| Yelp-voll | Gefühl | 5 | 39k/10k |
| AG-Nachrichten | Nachrichtenthema | 4 | 119.000/7,6.000 |
| Yahoo! Antworten | QA-Thema | 5 | 180.000/30,1.000 |
| DBPedia | Thema Ontologie | 14 | 280.000/70.000 |
| TREC | Fragethema | 6 | 5k/0,5k |
Die verarbeiteten Daten finden Sie unter diesem Link. Der Ordner zum Ablegen dieser Datensätze wird in den folgenden Abschnitten beschrieben.
Führen Sie die folgenden Befehle aus
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
Wir stellen die Pseudovorhersage bereit, die wir über die Eingabeaufforderungen im obigen Link für Datensätze erhalten. Einzelheiten entnehmen Sie bitte den Originalunterlagen.
Führen Sie die folgenden Befehle aus (Beispiel für den AG News-Datensatz)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
Einige wichtige Hyperparameter:
rho : der Parameter, der für die Ausbreitung der Unsicherheit in Gl. verwendet wird. 6 des Papiersbeta : die Regularisierung der Distanz in Gl. 8 des Papiersgamma : das Gewicht des Regularisierungsterms in Gl. 10 des Papiers Ausführliche Anweisungen finden Sie im finetune Ordner.
Ausführliche Anweisungen finden Sie im Ordner prompt_learning .
Sehen Sie sich diesen Link als Pipeline zum Generieren der auf Eingabeaufforderungen basierenden Vorhersagen an. Beachten Sie, dass Sie Ihre Aufforderungsverbalisierer und Vorlagen anpassen müssen.
Um die Dokumenteinbettungen zu generieren, können Sie die oben genannten Befehle mithilfe von SimCSE befolgen.
Sobald Sie den Index für die ausgewählten Daten generiert haben, können Sie die Pipelines in Running Fine-tuning Experiments und Running Prompt-based Learning Experiments für die Feinabstimmung mit wenigen Schüssen und auf aufforderungsbasierten Lernexperimente verwenden.
Bitte zitieren Sie das folgende Dokument, wenn Sie dieses Repo für Ihre Recherche hilfreich finden. Dank im Voraus!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
Wir möchten den Autoren des Repos SimCSE und OpenPrompt für den gut organisierten Code danken.


