JustJoking.ai
1.0.0
In diesem Projekt habe ich ein Transformatormodell trainiert, um kurze Witze zu generieren. Mit einer geringfügigen Modifikation der Inferenzmethode konnte ich dann dasselbe Modell verwenden, sodass das Modell bei gegebener Anfangszeichenfolge als Eingabe versucht, diese auf humorvolle Weise zu vervollständigen.
Es gibt zwei Notebooks, die beide die gleiche Aufgabe erledigen.
Ergebnis der Witzgenerierung 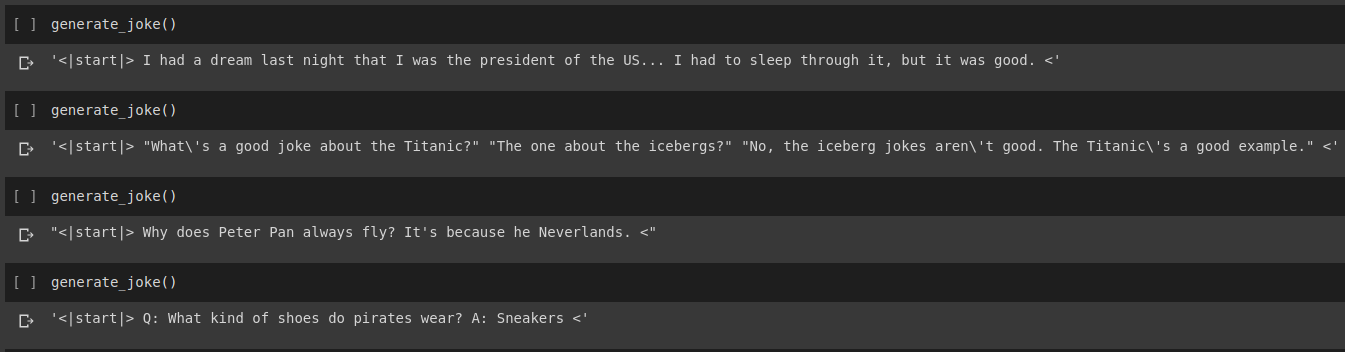
Ergebnis der Satzvervollständigung 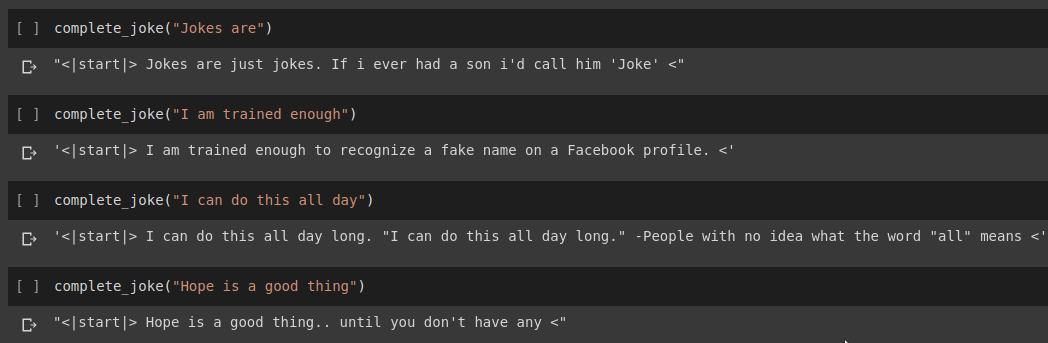
Ergebnisse 
Für unsere Aufgabe verwenden wir den auf Kaggle bereitgestellten Datensatz. Es handelt sich um eine CSV-Datei mit über 200.000 Kurzwitzen, die aus Reddit stammen.
Hinweis: Da der Datensatz einfach aus verschiedenen Subreddits entfernt wurde, sind viele der Witze im Datensatz ziemlich rassistisch und sexistisch. Da jede KI ihre Trainingsdaten als einzige Wissensquelle annimmt, ist zu erwarten, dass unser Modell manchmal ähnliche Witze generiert.
Sobald wir unsere Witzzeichenfolge tokenisiert haben, fügen wir am Ende der tokenisierten Liste ein start_token und ein end_token hinzu. Da unsere Scherzzeichenfolge außerdem unterschiedliche Längen haben kann, füllen wir alle Zeichenfolgen auf eine bestimmte max_length auf, sodass alle Tensoren in unseren Stapeln eine ähnliche Form haben.
Code hierfür finden Sie im Notebook Joke Generation.ipynb . Hier importieren wir das GPT2Tokenizer- und das TFGPT2LMHead-Modell aus der HuggingFace-Bibliothek. Der Code ist in Tensorflow2 geschrieben. Das Notizbuch enthält an geeigneten Stellen Kommentare, die den Code erläutern. Außerdem bieten die HuggingFace-Dokumente eine gute Dokumentation der Eingabeparameter und des Rückgabewerts des Modells. Informationen zur PyTorch-basierten Implementierung finden Sie im Humour.ai-Repo von Tanul Singh
Code hierfür finden Sie im Notebook Joke_Completion_Pure_TF2_Implementation.ipynb . Um das Projekt noch einen Schritt weiterzuführen, um tiefer zu verstehen, wie die Dinge funktionieren, habe ich versucht, einen Transformator ohne externe Bibliothek zu erstellen. Ich habe auf das von Tensorflow bereitgestellte Tutorial für Transformers verwiesen und einige der in ihrem Tutorial erwähnten Erklärungen mit weiteren Erklärungen in mein Notizbuch eingefügt, damit es leicht zu verstehen ist, was vor sich geht.
Ich habe zunächst einen Tokenizer für unseren Datensatz erstellt und damit die Zeichenfolgen tokenisiert. Anschließend wurde eine Ebene für Positional Encodings und MultiHeadAttention erstellt. Außerdem habe ich eine Lambda layer verwendet, um die geeigneten Masken für unsere Daten zu erstellen.
Dann habe ich den Aufbau einer einzelnen decoder layer für unseren Decoder erstellt. Das Folgende ist die Architektur einer einzelnen Decoderschicht.
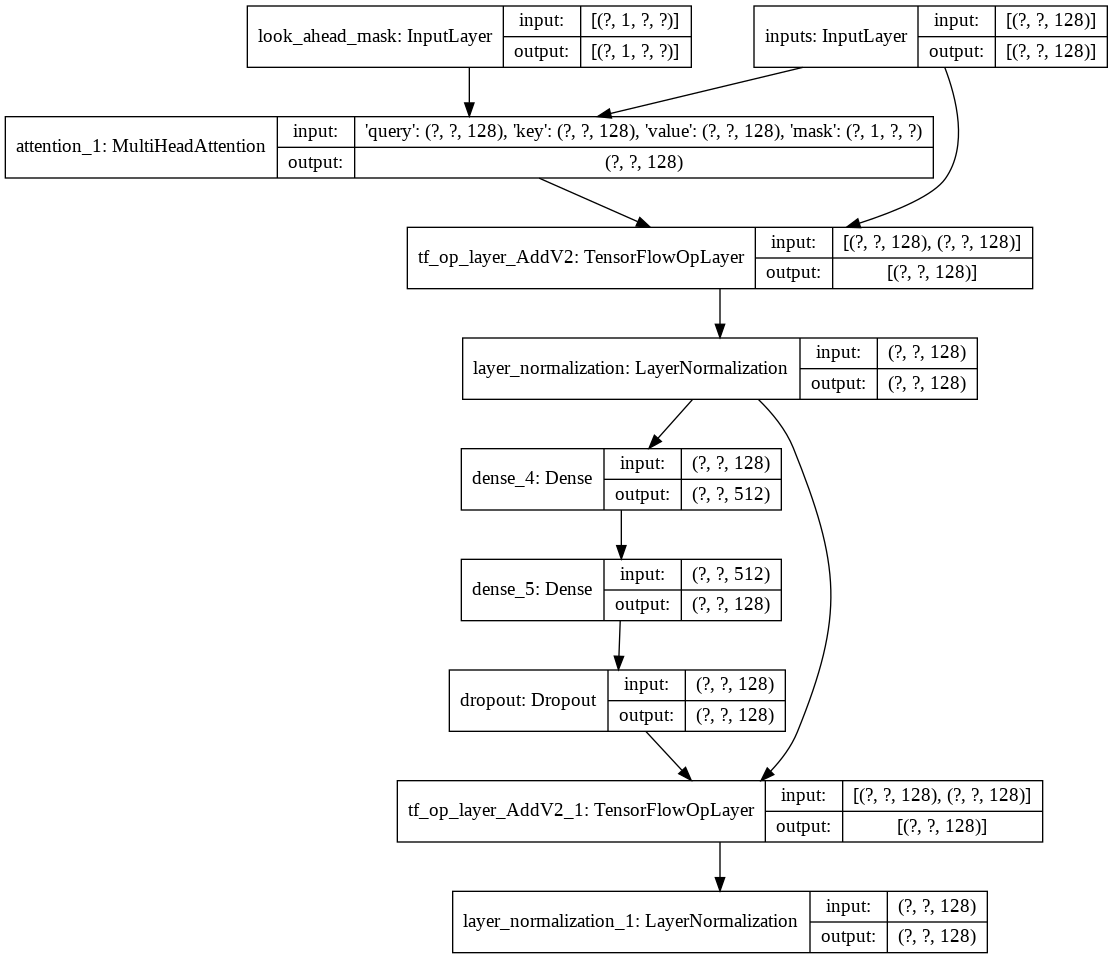
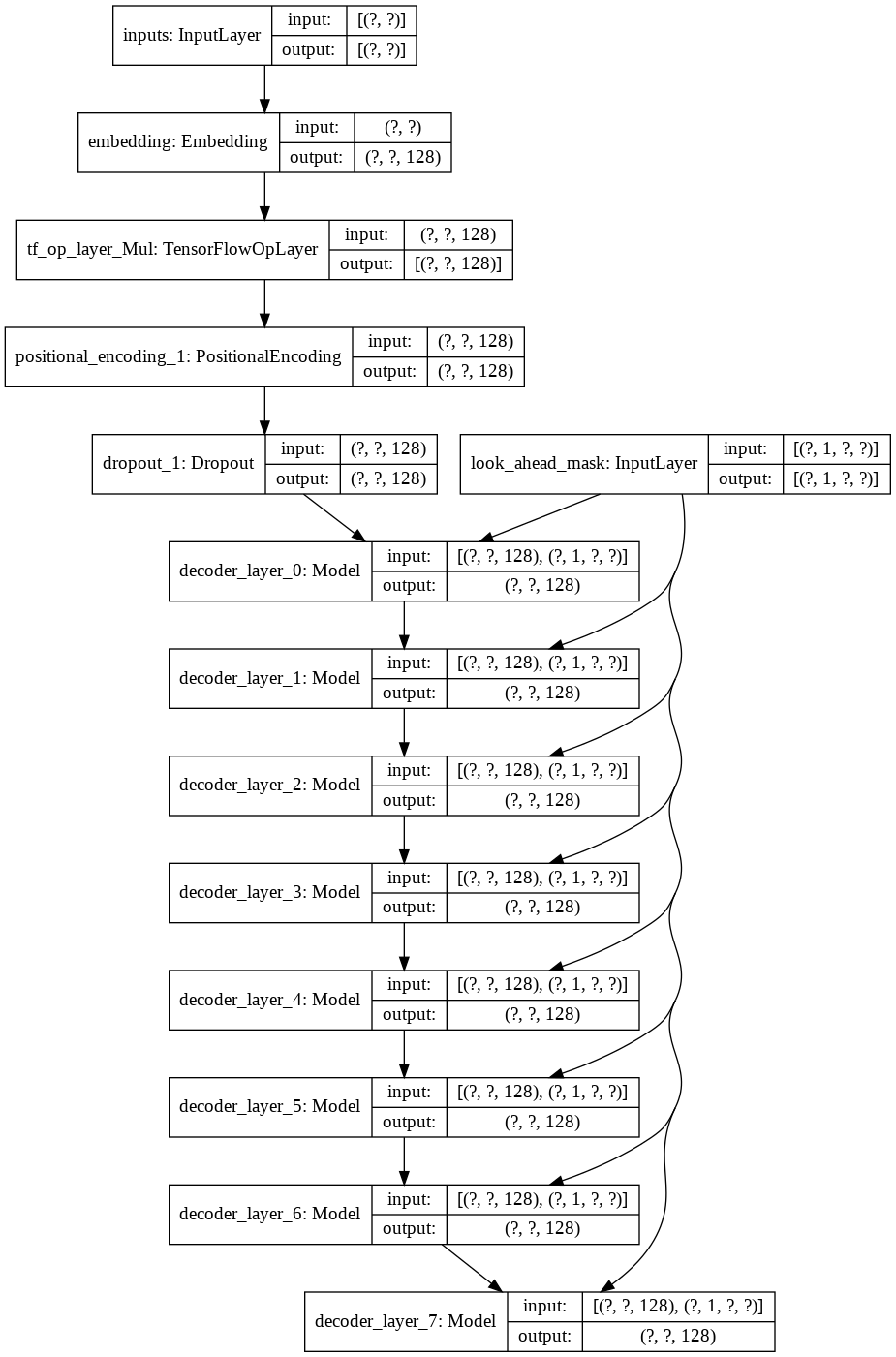
Für das endgültige transformer nimmt es die Eingabetokens, leitet sie durch die Lamda-Schicht, um die Maske zu erhalten, und übergibt sowohl die Maske als auch die Tokens an unseren Sprachdecoder, dessen Ausgabe dann durch eine dichte Schicht geleitet wird. Im Folgenden finden Sie die Architektur unseres endgültigen Modells.