CTCWordBeamSearch
1.0.0
Connectionist Temporal Classification (CTC)-Decoder mit Wörterbuch und Sprachmodell (LM).
pip install .tests/ und führen Sie pytest aus, um zu überprüfen, ob die Installation funktioniert hat Das folgende Spielzeugbeispiel zeigt, wie die Wortstrahlsuche verwendet wird. Das hypothetische Modell (z. B. ein Texterkennungsmodell) ist in der Lage, drei verschiedene Zeichen zu erkennen: „a“, „b“ und „ “ (Leerzeichen). Wörter in diesem Spielzeugbeispiel können die Zeichen „a“ und „b“ enthalten (jedoch nicht „ “, das das Worttrennzeichen darstellt). Das Sprachmodell wird aus einem Textkorpus trainiert, der nur zwei Wörter enthält: „a“ und „ba“.
In diesem Codeausschnitt wird eine Instanz der Wortstrahlsuche erstellt und ein TxBx(C+1)-förmiges Numpy-Array dekodiert:
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )Der Decoder gibt eine Liste mit einer decodierten Label-Zeichenfolge für jedes Batch-Element zurück. Um schließlich die Zeichenfolgen zu erhalten, ordnen Sie jede Beschriftung dem entsprechenden Zeichen zu:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )Beispiele:
tests/test_word_beam_search.py Parameter des Konstruktors der WordBeamSearch -Klasse:
0<len(wordChars)<len(chars) . Falls nur einzelne Wörter erkannt werden müssen, ist kein Trennzeichen erforderlich, daher können die beiden Parameter auch gleich sein: 0<len(wordChars)<=len(chars) Eingabe in die WordBeamSearch.compute -Methode:
Die Wortstrahlsuche ist ein CTC-Dekodierungsalgorithmus. Es wird für Sequenzerkennungsaufgaben wie handschriftliche Texterkennung oder automatische Spracherkennung verwendet.
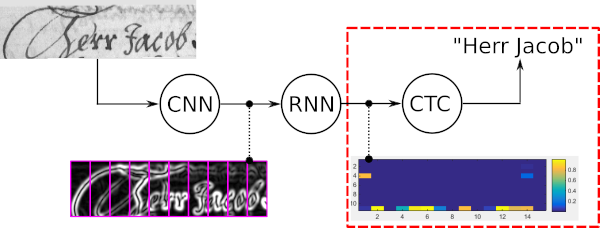
Die vier Haupteigenschaften der Wortstrahlsuche sind:
Das folgende Beispiel zeigt einen typischen Anwendungsfall der Wortstrahlsuche zusammen mit den Ergebnissen von fünf verschiedenen Decodern. Die beste Pfaddecodierung und die Vanilla-Beam-Suche führen zu falschen Wörtern, da diese Decoder nur den verrauschten Ausgang des optischen Modells verwenden. Die Erweiterung der Vanilla-Beam-Suche um einen LM auf Zeichenebene verbessert das Ergebnis, da nur wahrscheinliche Zeichenfolgen zugelassen werden. Beim Token-Passing werden ein Wörterbuch und ein LM auf Wortebene verwendet, sodass alle Wörter richtig sind. Es ist jedoch nicht in der Lage, beliebige Zeichenfolgen wie Zahlen zu erkennen. Die Wortstrahlsuche ist in der Lage, mithilfe eines Wörterbuchs Wörter zu erkennen, aber auch Nicht-Wort-Zeichen korrekt zu identifizieren.

Weitere Informationen:
extras/prototype/extras/tf/ Bitte zitieren Sie den folgenden Artikel, wenn Sie in Ihrer Forschungsarbeit die Wortstrahlsuche verwenden.
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


