LM SupCon
1.0.0
Dieses Repo behandelt die Umsetzung des folgenden Papiers: Contrastive Learning for Prompt-based Few-shot Language Learners von Yiren Jian, Chongyang Gao und Soroush Vosoughi, angenommen bei NAACL 2022.
Wenn Sie dieses Repo für Ihre Forschung nützlich finden, denken Sie bitte darüber nach, das Papier zu zitieren.
@inproceedings { jian-etal-2022-contrastive ,
title = " Contrastive Learning for Prompt-based Few-shot Language Learners " ,
author = " Jian, Yiren and
Gao, Chongyang and
Vosoughi, Soroush " ,
booktitle = " Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies " ,
month = jul,
year = " 2022 " ,
address = " Seattle, United States " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2022.naacl-main.408 " ,
pages = " 5577--5587 " ,
abstract = "The impressive performance of GPT-3 using natural language prompts and in-context learning has inspired work on better fine-tuning of moderately-sized models under this paradigm. Following this line of work, we present a contrastive learning framework that clusters inputs from the same class for better generality of models trained with only limited examples. Specifically, we propose a supervised contrastive framework that clusters inputs from the same class under different augmented {``}views{''} and repel the ones from different classes. We create different {``}views{''} of an example by appending it with different language prompts and contextual demonstrations. Combining a contrastive loss with the standard masked language modeling (MLM) loss in prompt-based few-shot learners, the experimental results show that our method can improve over the state-of-the-art methods in a diverse set of 15 language tasks. Our framework makes minimal assumptions on the task or the base model, and can be applied to many recent methods with little modification.",
} Unser Code ist stark von LM-BFF und SupCon ( /src/losses.py ) entlehnt.
Dieses Repo wurde mit Ubuntu 18.04.5 LTS, Python 3.7, PyTorch 1.6.0 und CUDA 10.1 getestet. Für Experimente mit RoBERTa-base benötigen Sie eine 48-GB-GPU und für RoBERTa-large 4x 48-GB-GPUs. Wir führen unsere Experimente auf Nvidia RTX-A6000 und RTX-8000 durch, aber auch Nvidia A100 mit 40 GB sollte funktionieren.
Wir verwenden vorverarbeitete Datensätze (SST-2, SST-5, MR, CR, MPQA, Subj, TREC, CoLA, MNLI, SNLI, QNLI, RTE, MRPC, QQP) von LM-BFF. LM-BFF bietet hilfreiche Skripte zum Herunterladen und Vorbereiten des Datensatzes. Führen Sie einfach die folgenden Befehle aus.
cd data
bash download_dataset.shVerwenden Sie dann den folgenden Befehl, um die 16-Schuss-Datensätze zu generieren, die wir in der Studie verwendet haben.
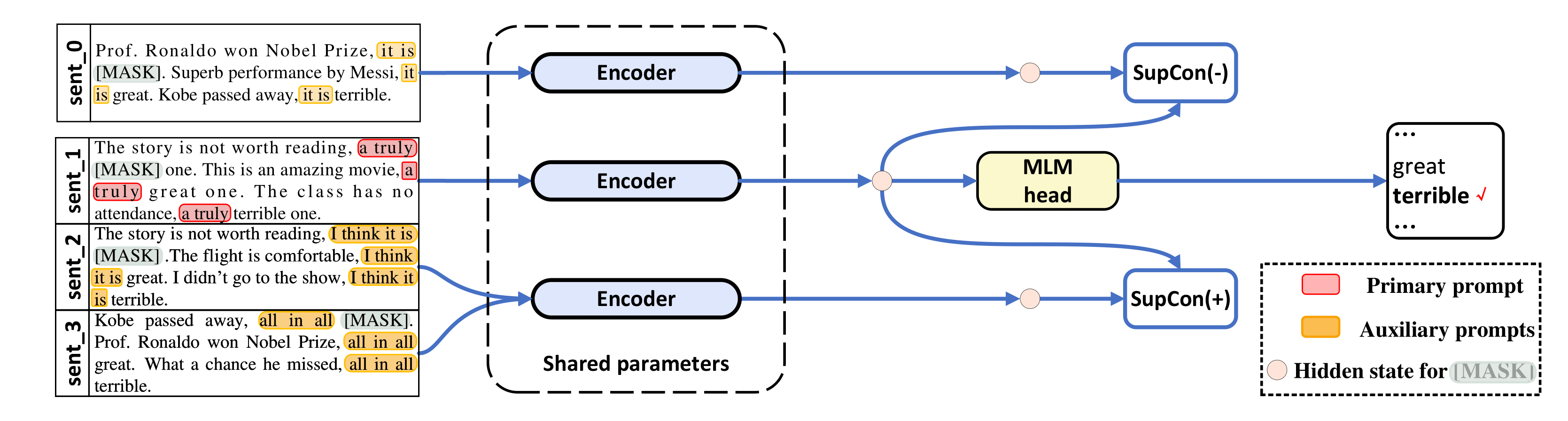
python tools/generate_k_shot_data.py Die für Aufgaben verwendeten primären Eingabeaufforderungen (Vorlagen) wurden in run_experiments.sh vordefiniert. Die Hilfsvorlagen, die beim Generieren mehrerer Ansichten von Eingaben für kontrastives Lernen verwendet werden, finden Sie in /auto_template/$TASK .
Unter der Annahme, dass Sie eine GPU in Ihrem System haben, zeigen wir ein Beispiel für die Ausführung unserer Feinabstimmung auf SST-5 (zufällige Vorlagen und zufällige Demonstrationen für „erweiterte Ansichten“ von Eingaben).
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 40 # ### batch size
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-base
bash run_experiment.sh
done
done
done
done
rm -rf result/ Unser Framework gilt auch für auf Eingabeaufforderungen basierende Methoden ohne Demonstrationen, d. h. TYPE=prompt (In diesem Fall greifen wir nur nach dem Zufallsprinzip auf Vorlagen zum Generieren von „erweiterten Ansichten“ zurück). Die Ergebnisse werden im log gespeichert.
Für die Verwendung von RoBERTa-large als Basismodell sind 4 GPUs mit jeweils 48 GB Speicher erforderlich. Sie müssen zuerst Zeile 20 in src/models.py so bearbeiten, dass sie def __init__(self, hidden_size=1024) ist.
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 10 # ### batch size for each GPU, total batch size is then 40
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-large
bash run_experiment.sh
done
done
done
done
rm -rf result/ python tools/gather_result.py --condition "{'tag': 'exp', 'task_name': 'sst-5', 'few_shot_type': 'prompt-demo'}"
Es sammelt die Ergebnisse aus log und berechnet den Mittelwert und die Standardabweichung über diese 5 Zugtest-Splits.
Bei Fragen wenden Sie sich bitte an die Autoren.
Vielen Dank an LM-BFF und SupCon für die vorläufigen Implementierungen.


