DialogStudio
1.0.0

Papier, Huggingface, Model, Twitter
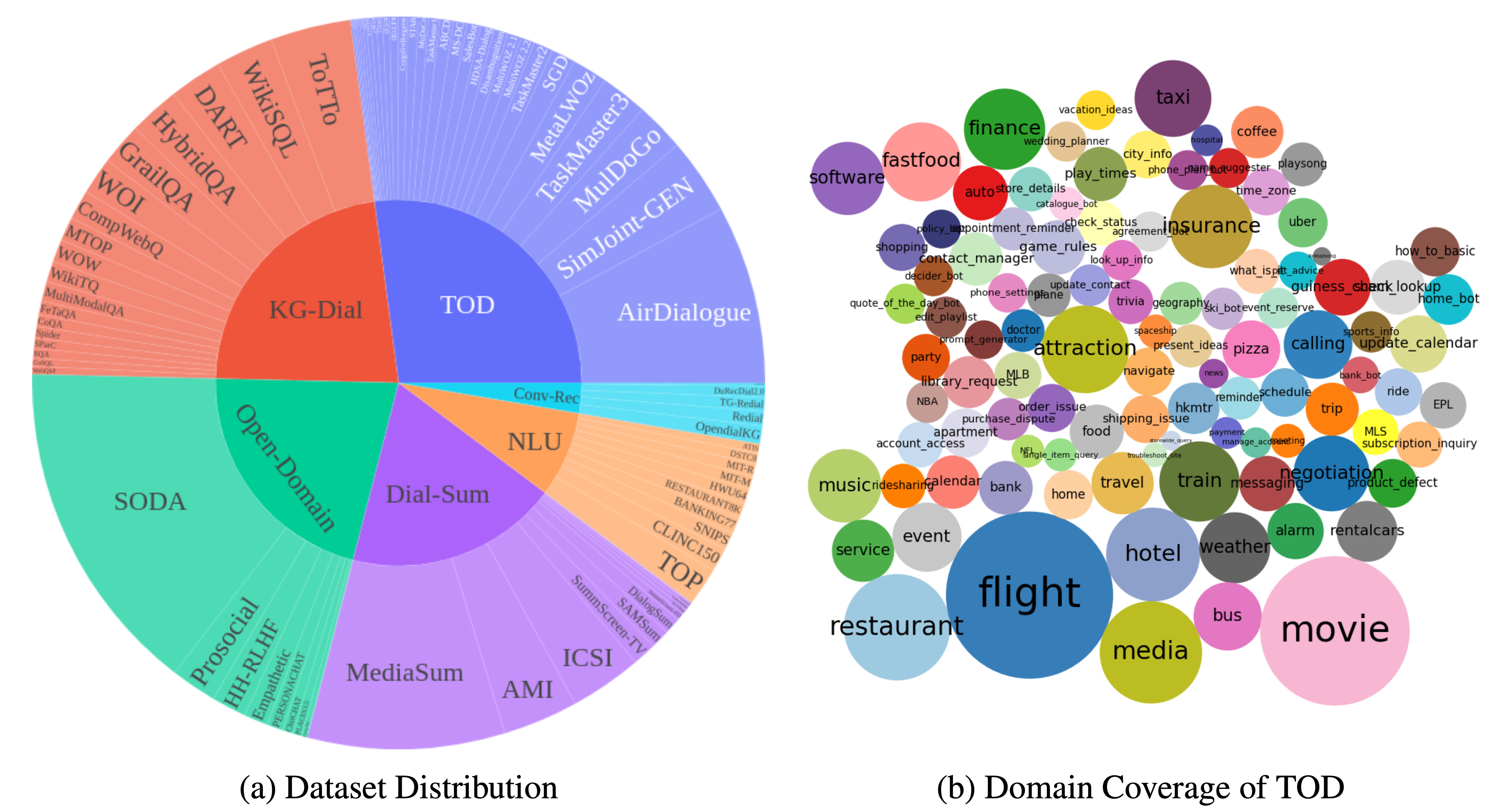
DialogStudio ist eine große Sammlung und einheitliche Dialogdatensätze. Die folgende Abbildung bietet eine Zusammenfassung der allgemeinen Statistiken im Zusammenhang mit DialogStudio . DialogStudio hat jeden Datensatz vereinheitlicht und dabei seine ursprünglichen Informationen beibehalten. Dies hilft bei der Unterstützung der Forschung sowohl an einzelnen Datensätzen als auch beim LLM-Training (Large Language Model). Die vollständige Liste aller verfügbaren Datensätze finden Sie hier.
Die Daten können über Huggingface heruntergeladen werden, wie unter „Laden von Daten“ beschrieben. Wir stellen auch Beispiele für jeden Datensatz in diesem Repo bereit. Detailliertere und kategoriespezifische Details finden Sie in den einzelnen Ordnern, die jeder Kategorie innerhalb der DialogStudio Sammlung entsprechen, z. B. MULTIWOZ2_2-Datensatz unter der Kategorie „Aufgabenorientierte Dialoge“.
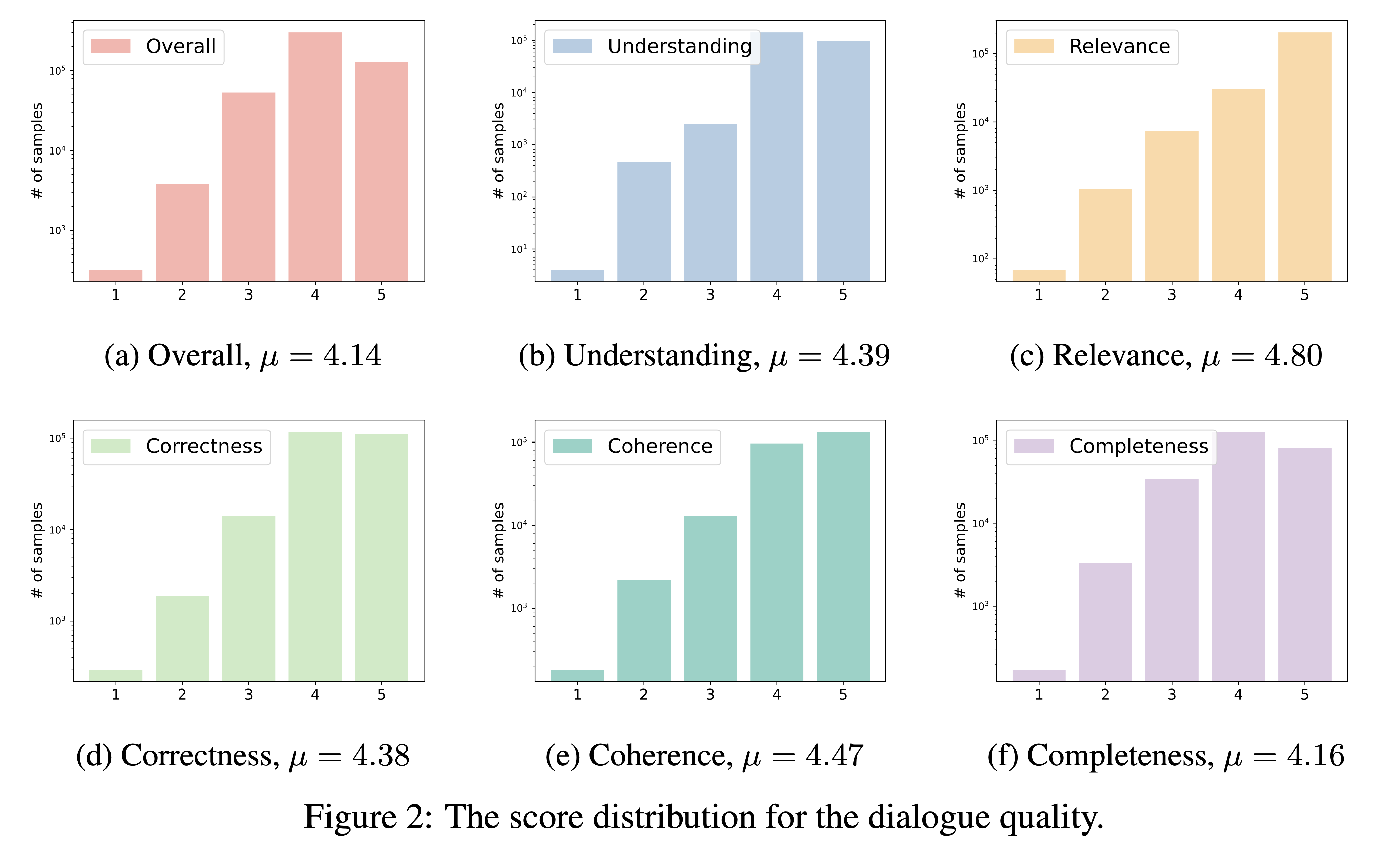
DialogStudio bewertet die Dialogqualität anhand von sechs kritischen Kriterien: Verständnis, Relevanz, Korrektheit, Kohärenz, Vollständigkeit und Gesamtqualität. Jedes Kriterium wird auf einer Skala von 1 bis 5 bewertet, wobei die höchsten Punkte für außergewöhnliche Dialoge reserviert sind.
Angesichts der großen Anzahl an Datensätzen, die in DialogStudio integriert sind, haben wir „gpt-3.5-turbo“ verwendet, um 33 verschiedene Datensätze auszuwerten. Das entsprechende Skript, das für diese Auswertung verwendet wird, kann über den Link aufgerufen werden.
Nachfolgend stellen wir Ihnen die Ergebnisse unserer Dialogqualitätsbewertung vor. Wir beabsichtigen, in der kommenden Zeit Bewertungsergebnisse für einzelne ausgewählte Dialoge zu veröffentlichen.
Sie können jeden Datensatz im DialogStudio vom HuggingFace-Hub laden, indem Sie den {dataset_name} beanspruchen, der genau der Name des Datensatzordners ist. Alle verfügbaren Datensätze werden im Datensatzinhalt beschrieben.
Nachfolgend finden Sie ein Beispiel zum Laden des Datensatzes MULTIWOZ2_2 in der Kategorie „Aufgabenorientierte Dialoge“:
Laden Sie den Datensatz
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )Hier ist die Ausgabestruktur von MultiWOZ 2.2
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})Die Datensätze sind in diesem GitHub-Repository und HuggingFace-Hub in mehrere Kategorien unterteilt. Weitere Informationen finden Sie in der Tabelle des Datensatzes. Und Sie können in jeden Ordner klicken, um einige Beispiele anzusehen:
Wir haben Version 1.0 von Modellen ( DialogStudio -t5-base-v1.0, DialogStudio -t5-large-v1.0, DialogStudio -t5-3b-v1.0) eingeführt, die auf einigen ausgewählten DialogStudio Datensätzen trainiert wurden. Weitere Einzelheiten finden Sie auf den einzelnen Modellkarten.
Unten finden Sie ein Beispiel für die Ausführung des Modells auf der CPU:
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Unser Projekt folgt bezüglich der Lizenzierung folgender Struktur:
Detaillierte Lizenzinformationen finden Sie in den spezifischen Lizenzen, die den Originaldatensätzen beiliegen. Es ist wichtig, dass Sie sich mit diesen Bedingungen vertraut machen, da wir keine Verantwortung für Lizenzfragen übernehmen.
Wir danken allen Datensatzautoren, die zum Bereich Conversational AI beigetragen haben, aufrichtig. Trotz sorgfältiger Bemühungen kann es zu Ungenauigkeiten in unseren Zitaten oder Referenzen kommen. Wenn Sie Fehler oder Auslassungen entdecken, melden Sie bitte ein Problem oder senden Sie eine Pull-Anfrage, um uns bei der Verbesserung zu helfen. Danke schön!
Die Daten und der Code in diesem Repository wurden größtenteils für das folgende Dokument entwickelt oder daraus abgeleitet. Wenn Sie Datensätze von DialogStudio verwenden, bitten wir Sie, sowohl die Originalarbeit als auch unsere eigene Arbeit zu zitieren (von der EACL 2024 Findings als Langarbeit akzeptiert).
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
Wir freuen uns über Beiträge aus der Community! Begleiten Sie uns bei unserer gemeinsamen Mission, den Bereich der Konversations-KI voranzutreiben!


