aug pe
1.0.0
? Papier • Daten (Yelp/OpenReview/PubMed) • Projektseite
Dieses Repository implementiert den Augmented Private Evolution (Aug-PE)-Algorithmus und nutzt den Inferenz-API-Zugriff auf große Sprachmodelle (LLMs), um differenziell privaten (DP) synthetischen Text zu generieren, ohne dass ein Modelltraining erforderlich ist. Wir vergleichen DP-SGD-Feinabstimmung und Aug-PE:

Unter
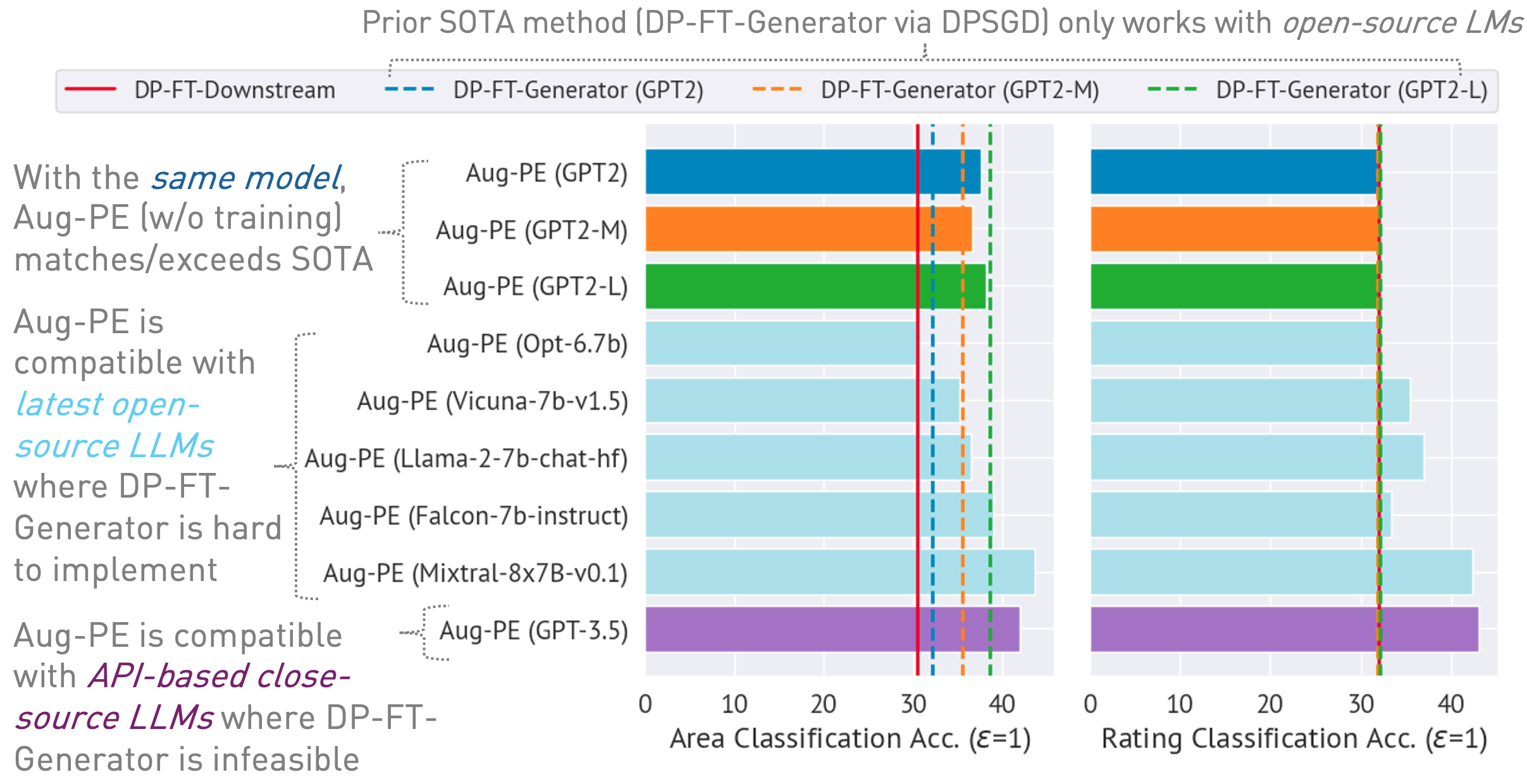
03/13/2024 : Projektseite ist verfügbar, die den Algorithmus und seine Ergebnisse beschreibt.03/11/2024 : Code und ArXiv-Papier sind verfügbar. conda env create -f environment.yml
conda activate augpe
Datensätze befinden sich unter data/{dataset} wobei dataset yelp , openreview und pubmed ist.
Laden Sie Yelp train.csv (1.21G) und PubMed train.csv (117 MB) über diesen Link herunter oder führen Sie Folgendes aus:
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvBeschreibung des Datensatzes:
Berechnen Sie Einbettungen für private Daten vorab (Zeile 1 im Aug-PE-Algorithmus):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp Hinweis: Die Berechnung von Einbettungen für OpenReview und PubMed geht relativ schnell. Aufgrund der großen Datensatzgröße von Yelp (1,9 Millionen Trainingsbeispiele) kann der Vorgang jedoch etwa 40 Minuten dauern.
Berechnen Sie den DP-Geräuschpegel für Ihren Datensatz in notebook/dp_budget.ipynb unter Berücksichtigung des Datenschutzbudgets
Konfigurieren Sie für die Visualisierung mit Wandb den --wandb_key und --project mit Ihrem Schlüssel und Projektnamen in dpsda/arg_utils.py .
Nutzen Sie Open-Source-LLMs von Hugging Face, um synthetische Daten zu generieren:
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedEinige wichtige Hyperparameter:
noise : DP-Rauschen.epoch : Wir verwenden 10 Epochen für die DP-Einstellung. Für die Nicht-DP-Einstellung verwenden wir 20 Epochen für Yelp und 10 Epochen für andere Datensätze.model_type : Modell auf Huggingface, wie zum Beispiel [„gpt2“, „gpt2-medium“, „gpt2-large“, „meta-llama/Llama-2-7b-chat-hf“, „tiiuae/falcon-7b-instruct“ , „facebook/opt-6.7b“, „lmsys/vicuna-7b-v1.5“, „mistralai/Mixtral-8x7B-Instruct-v0.1“].num_seed_samples : Anzahl der synthetischen Proben.lookahead_degree : Anzahl der Variationen für die Schätzung der Einbettung synthetischer Proben (Zeile 5 im Aug-PE-Algorithmus). Der Standardwert ist 0 (selbst einbettend).L : Bezogen auf die Anzahl der Variationen zur Generierung synthetischer Kandidatenproben (Zeile 18 im Aug-PE-Algorithmus)feat_ext : Einbettungsmodell in Huggingface-Satztransformatoren.select_syn_mode : Wählen Sie synthetische Proben gemäß Histogrammstimmen oder Wahrscheinlichkeit aus. Standard ist rank (Zeile 19 im Aug-PE-Algorithmus)temperature : Temperatur für die LLM-Erzeugung.Optimieren Sie das Downstream-Modell mit synthetischem DP-Text und bewerten Sie die Genauigkeit des Modells anhand realer Testdaten:
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance Messen Sie den Einbettungsverteilungsabstand:
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distanceFür einen schlanken Prozess, der alle Generierungs- und Auswertungsschritte vereint:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset Wir verwenden ein Closed-Source-Modell über die Azure OpenAI API. Bitte legen Sie Ihren Schlüssel und Endpunkt in apis/azure_api.py fest
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} Hier könnte engine gpt-35-turbo in Azure sein.
Führen Sie das folgende Skript aus, um synthetische Daten zu generieren, diese in der nachgelagerten Aufgabe auszuwerten und den Einbettungsverteilungsabstand zwischen realen und synthetischen Daten zu berechnen:
bash scripts/gpt-3.5-turbo/{dataset}.shWir verwenden textlängenbezogene Eingabeaufforderungen für GPT-3.5, um die Länge des generierten Textes zu steuern. Wir führen hier mehrere zusätzliche Hyperparameter ein:
dynamic_len wird verwendet, um den dynamischen Längenmechanismus zu aktivieren.word_var_scale : Gaußsche Rauschvarianz, die zur Bestimmung des target_word verwendet wird.max_token_word_scale : maximale Anzahl von Token pro Wort. Wir legen den max_token für die LLM-Generierung basierend auf target_word (in der Eingabeaufforderung angegeben) und max_token_word_scale fest. Verwenden Sie das Notebook, um den Textlängenverteilungsunterschied zwischen realen und synthetischen Daten zu berechnen: notebook/text_lens_distribution.ipynb
Wenn Sie unsere Arbeit hilfreich finden, denken Sie bitte darüber nach, sie wie folgt zu zitieren:
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}Wenn Sie Fragen zum Code oder zum Papier haben, senden Sie bitte eine E-Mail an Chulin ([email protected]) oder eröffnen Sie ein Problem.


