Study Bot
1.0.0
Study-Bot ist ein Open-Source-Projekt, das von Edumakers von Tecnológico de Monterrey entwickelt wurde. Es soll sehbehinderten Studierenden dabei helfen, ihr akademisches Kursmaterial zu überprüfen. Es handelt sich um einen KI-gestützten Lernbegleiter, der verschiedene Technologien umfasst, darunter Whisper, GPT-3.5-turbo-16k, Elevenlabs Text-to-Speech und OpenCV. Zu Testzwecken wurde Beispielkursmaterial mit ChatGPT generiert.
Study-Bot kann: die Frage des Benutzers anhören, das Quellmaterial des Themas analysieren, das er studieren möchte, das physische Lehrmaterial, das er in der Hand hält, anhand seiner Farbe oder ArUco-Markierung erkennen, eine Antwort generieren und diese laut vorlesen Benutzer als zugängliche ausführbare Anwendung. Zu Entwicklungs- und Testzwecken kann es über den Python- Interpreter als CLI -Programm oder mit einer GUI ausgeführt werden.
Einige gute nächste Schritte könnten darin bestehen, dieses System in eine fortschrittlichere Benutzeroberfläche für die Verteilung als Desktop-Anwendung einzubetten, ein Computer-Vision-Modell zu erstellen, das das physische Lehrmaterial erkennen kann, ohne von Farben oder ArUco-Markierungen abhängig zu sein, sowie einige Leistungsverbesserungen und neue interaktive Funktionen.
Es wird empfohlen, Python 3.9.9 zu verwenden, damit die whisper -Bibliothek problemlos verwendet werden kann. Um zu vermeiden, dass Sie Ihre aktuelle Python- Installation entfernen müssen, möchten Sie möglicherweise eine virtuelle Umgebung verwenden, um diese spezielle Version von Python zu verwenden. Führen Sie den folgenden Befehl aus, um die erforderlichen Abhängigkeiten zu installieren:
pip install -r requirements.txt Bevor das Projekt durchgeführt werden kann, müssen noch einige zusätzliche Schritte unternommen werden, beispielsweise die Beschaffung eigener API-Schlüssel für die hier verwendeten KI-Dienste. Weitere Informationen finden Sie im Documentation . Dort finden Sie eine umfassende Anleitung zur Verwendung dieses Projekts.
Study-Bot setzt auf folgende bestehende Dienste und Technologien:
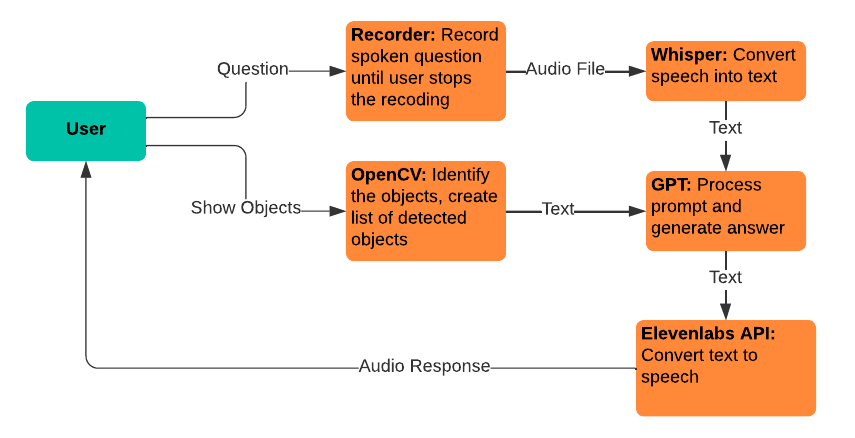
Flüstern: Wird für die Konvertierung von Sprache in Text verwendet, sodass Benutzer ihre Fragen sprechen können, um sie in das GPT-Modell einzuspeisen.
gpt-3.5-turbo-16k: Wird zur Fragenverarbeitung und Antwortgenerierung verwendet. Die 16K-Version des Modells wurde aufgrund ihrer Kontextfenstergröße von 16.385 Token ausgewählt, die für die Verarbeitung einer großen Menge an Quellmaterial erforderlich ist.
Elevenlabs Text-to-Speech: Wird für die Text-in-Sprache-Konvertierung verwendet, sodass Benutzer die vom GPT-Modell generierten Antworten hören können.
OpenCV: Wird zur Identifizierung physischer Objekte verwendet, um das GPT-3.5-16k-Modell bei der Beantwortung von Fragen mit dem zusätzlichen Kontext dessen zu unterstützen, was der Benutzer hält.
Nutzen Sie dieses Projekt als Referenz für Ihr eigenes Projekt oder forken Sie es, um eigene Beiträge zu leisten. GitHub-Probleme zu Funktionsanfragen und Fehlerberichten sind willkommen und werden besonders geschätzt, wenn sie Feedback von sehbehinderten Benutzern enthalten.


