bRAG langchain
1.0.0
If this project helps you, consider buying me a coffee ☕. Your support helps me keep contributing to the open-source community!
Die offizielle Plattform von bRAGAI wird bald gestartet. Tragen Sie sich auf die Warteliste ein, um zu den Early Adopters zu gehören!
Dieses Repository enthält eine umfassende Untersuchung der Retrieval-Augmented Generation (RAG) für verschiedene Anwendungen. Jedes Notebook bietet eine detaillierte, praktische Anleitung zum Einrichten und Experimentieren mit RAG, von der Einführungsstufe bis hin zu fortgeschrittenen Implementierungen, einschließlich Mehrfachabfragen und benutzerdefinierten RAG-Builds.
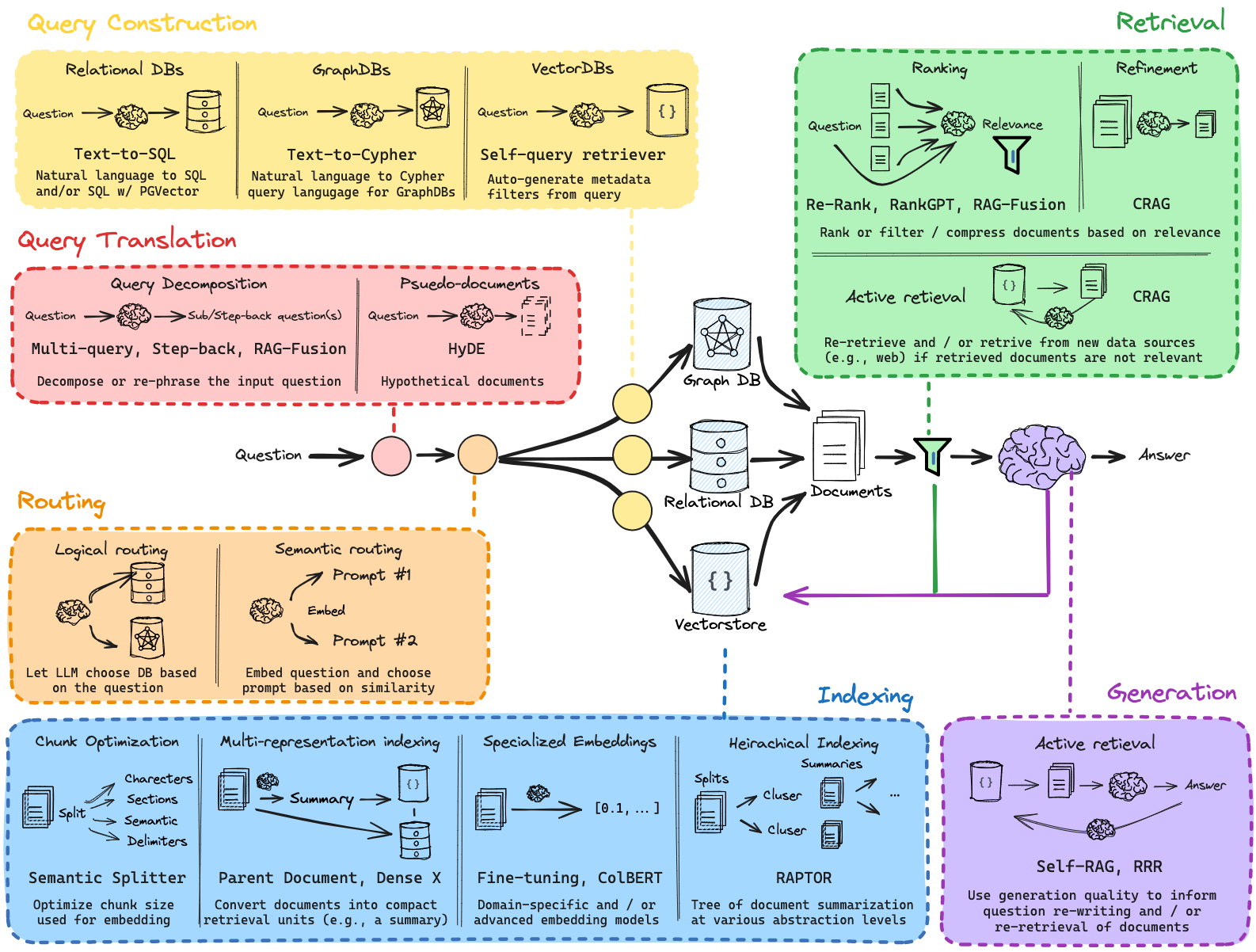
Wenn Sie direkt loslegen möchten, sehen Sie sich die Datei full_basic_rag.ipynb an -> diese Datei enthält einen Standard-Startercode für einen vollständig anpassbaren RAG-Chatbot.
Stellen Sie sicher, dass Sie Ihre Dateien in einer virtuellen Umgebung ausführen (siehe Abschnitt „ Get Started “).
Die folgenden Notizbücher finden Sie im Verzeichnis tutorial_notebooks/ .
Dieses Einführungsnotizbuch bietet einen Überblick über die RAG-Architektur und ihren grundlegenden Aufbau. Das Notizbuch geht durch:
Aufbauend auf den Grundlagen werden in diesem Notizbuch Techniken zur Mehrfachabfrage in der RAG-Pipeline vorgestellt und Folgendes untersucht:
Dieses Notebook befasst sich eingehender mit der Anpassung einer RAG-Pipeline. Es umfasst:
In Fortsetzung der vorherigen Anpassung werden in diesem Notizbuch folgende Themen behandelt:
Dieses abschließende Notebook fasst die RAG-Systemkomponenten zusammen, wobei der Schwerpunkt auf Skalierbarkeit und Optimierung liegt:
Voraussetzungen: Python 3.11.7 (bevorzugt)
Klonen Sie das Repository :
git clone https://github.com/bRAGAI/bRAG-langchain.git
cd bRAG-langchain
Erstellen Sie eine virtuelle Umgebung
python -m venv venv
source venv/bin/activate
Abhängigkeiten installieren : Stellen Sie sicher, dass Sie die in der Datei requirements.txt aufgeführten erforderlichen Pakete installieren.
pip install -r requirements.txt
Führen Sie die Notebooks aus : Beginnen Sie mit [1]_rag_setup_overview.ipynb um sich mit dem Einrichtungsprozess vertraut zu machen. Gehen Sie nacheinander die anderen Notebooks durch, um fortgeschrittenere RAG-Konzepte zu erstellen und damit zu experimentieren.
Umgebungsvariablen einrichten :
Duplizieren Sie die Datei .env.example im Stammverzeichnis, nennen Sie sie .env und fügen Sie die folgenden Schlüssel hinzu (ersetzen Sie sie durch Ihre tatsächlichen Schlüssel):
#LLM Modal
OPENAI_API_KEY="your-api-key"
#LangSmith
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
LANGCHAIN_API_KEY="your-api-key"
LANGCHAIN_PROJECT="your-project-name"
#Pinecone Vector Database
PINECONE_INDEX_NAME="your-project-index"
PINECONE_API_HOST="your-host-url"
PINECONE_API_KEY="your-api-key"
Notizbuchreihenfolge : Um das Projekt strukturiert zu verfolgen:
Beginnen Sie mit [1]_rag_setup_overview.ipynb
Fahren Sie mit [2]_rag_with_multi_query.ipynb fort
Gehen Sie dann durch [3]_rag_routing_and_query_construction.ipynb
Fahren Sie mit [4]_rag_indexing_and_advanced_retrieval.ipynb fort
Beenden Sie mit [5]_rag_retrieval_and_reranking.ipynb
Nachdem Sie die Umgebung eingerichtet und die Notebooks nacheinander ausgeführt haben, können Sie:
Experimentieren Sie mit Retrieval-Augmented Generation : Verwenden Sie das grundlegende Setup in [1]_rag_setup_overview.ipynb um die Grundlagen von RAG zu verstehen.
Implementieren Sie Multi-Querying : Erfahren Sie, wie Sie die Antwortrelevanz durch die Einführung von Multi-Querying-Techniken in [2]_rag_with_multi_query.ipynb verbessern können.
The notebooks and visual diagrams were inspired by Lance Martin's LangChain Tutorial.


