Xpersona
1.0.0


Dies ist der Quellcode des Artikels:
Xpersona : Bewertung eines mehrsprachigen personalisierten Chatbots . [PDF]
Das Papier wurde bei NLP4ConvAI auf der EMNLP 2021 (Honorable Mention Paper) vorgestellt. Dieser Code wurde mit PyTorch geschrieben. Wenn Sie in Ihrer Arbeit Quellcodes oder Datensätze aus diesem Toolkit verwenden, zitieren Sie bitte die folgenden Dokumente:
Xpersona
@inproceedings{lin2021 Xpersona ,
title={ Xpersona : Evaluierung eines mehrsprachigen personalisierten Chatbots},
Autor={Lin, Zhaojiang und Liu, Zihan und Winata, Genta Indra und Cahyawijaya, Samuel und Madotto, Andrea und Bang, Yejin und Ishii, Etsuko und Fung, Pascale},
booktitle={Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI},
Seiten={102--112},
Jahr={2021}
}
Englischer PersonaChat
@article{zhang2018personalizing,
title={Personalisierung von Dialogagenten: Ich habe einen Hund, haben Sie auch Haustiere?},
Autor={Zhang, Saizheng und Dinan, Emily und Urbanek, Jack und Szlam, Arthur und Kiela, Douwe und Weston, Jason},
journal={arXiv preprint arXiv:1801.07243},
Jahr={2018}
}

Xpersona Datensatz ist eine Erweiterung des Persona-Chat-Datensatzes. Konkret erweitern wir ConvAI2 auf die anderen sechs Sprachen: Chinesisch, Französisch, Indonesisch, Italienisch, Koreanisch und Japanisch.
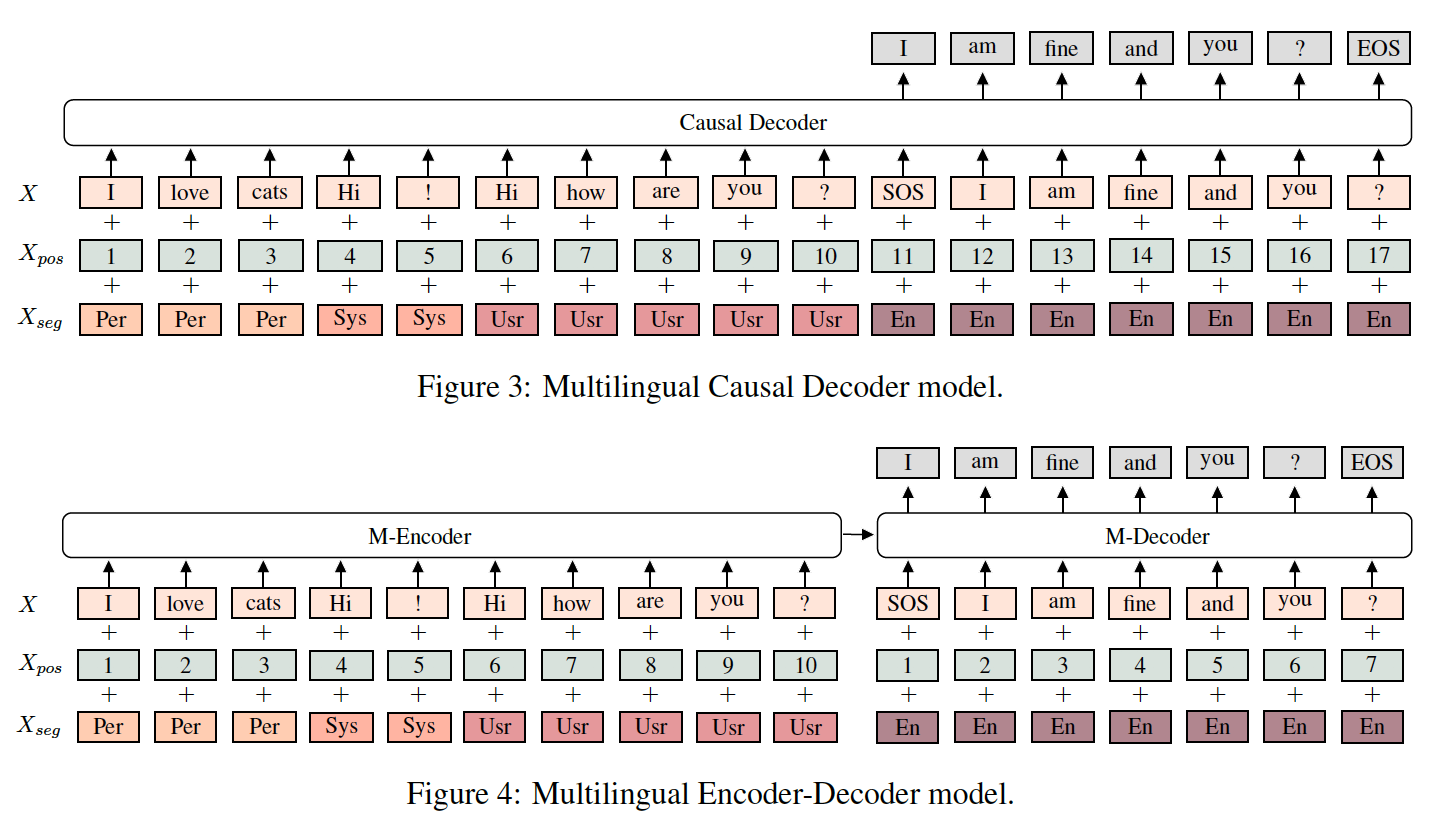
In dieser Arbeit stellten wir mehrsprachige und sprachenübergreifend trainierte Basislinien zur Verfügung. Weitere Einzelheiten finden Sie im mehrsprachigen und mehrsprachigen Ordner.
Dieses Repository wird mithilfe der Huggingface- Codebasis implementiert.


