local chat
v0.11.0
Chatten Sie mit generativen Sprachmodellen lokal auf Ihrem Computer, ohne dass eine Einrichtung erforderlich ist. LocalChat ist ein einfacher, leicht einzurichtender und Open-Source-lokaler KI-Chat, der auf llama.cpp aufbaut. Es erfordert keine technischen Kenntnisse und ermöglicht Benutzern, ChatGPT-ähnliches Verhalten auf ihren eigenen Computern zu erleben – vollständig DSGVO-konform und ohne Angst vor versehentlichem Informationsverlust. Laden Sie LocalChat für macOS, Windows oder Linux hier herunter.
Inhaltsverzeichnis
Übersicht | Begründung | Systemanforderungen | Schnellstart | Dokumentation
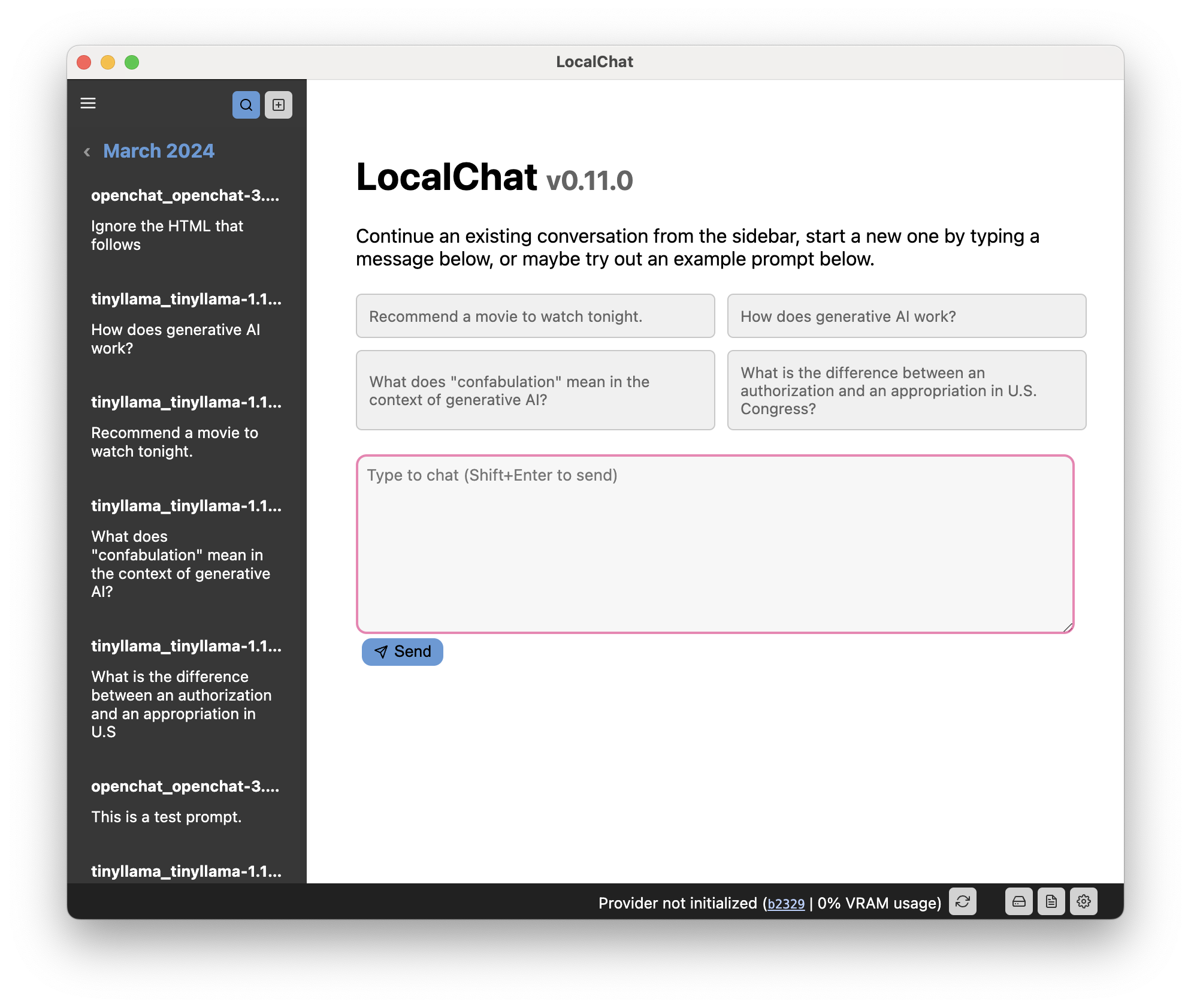
LocalChat bietet eine chatähnliche Schnittstelle für die Interaktion mit generativen Large Language Models (LLMs) . Es sieht aus und fühlt sich an wie jede Chat-Konversation, findet jedoch lokal auf Ihrem Computer statt. Es werden niemals Daten an einen Cloud-Server übertragen.
Es gibt bereits mehrere äußerst leistungsfähige generative Sprachmodelle, die fast wie ChatGPT aussehen und sich anfühlen. Der Hauptunterschied besteht darin, dass diese Modelle lokal ausgeführt werden und ein offenes Gewicht haben.
Wichtig
Wie Sie wahrscheinlich bereits wissen, fühlt sich das Chatten mit einem LLM möglicherweise sehr natürlich an, aber die Modelle bleiben probabilistisch: Sie generieren das nächste wahrscheinliche Wort basierend auf dem, was sonst noch in der Eingabeaufforderung enthalten ist. LLMs haben kein Gespür für Zeit, Kausalität, Kontext und das, was Linguisten Pragmatik nennen. Daher neigen sie dazu, Ereignisse zu erfinden, die nie stattgefunden haben, Fakten aus völlig unterschiedlichen Ereignissen zu verwechseln oder direkte Lügen zu erzählen (sogenannte „Halluzinationen“). Gleiches gilt für Code oder Berechnungen, die diese Modelle ausgeben können. Dazu wird gesagt:
Seien Sie vorsichtig und verwenden Sie dieses Modell auf eigene Gefahr. Denken Sie daran, dass es sich um ein Spielzeug und nicht um etwas Verlässliches handelt.
Als ChatGPT im November 2022 startete, war ich äußerst aufgeregt – aber gleichzeitig auch vorsichtig. Obwohl ich von den Fähigkeiten von GPT-3 sehr beeindruckt war, war ich mir schmerzlich der Tatsache bewusst, dass das Modell proprietär war und es, selbst wenn dies nicht der Fall wäre, unmöglich wäre, es lokal auszuführen. Als datenschutzbewusster europäischer Bürger gefällt mir der Gedanke nicht, von einem milliardenschweren Konzern abhängig zu sein, der jederzeit den Zugang sperren kann.
Aus diesem Grund konnte ich nicht wirklich mit GPT herumspielen und beschloss, auf das Unvermeidliche zu warten: die Entwicklung kleinerer und besserer Tools. Mittlerweile gibt es mehrere Modelle, die alle Anforderungen erfüllen: Sie laufen lokal und ähneln ChatGPT. Durch die Quantisierung (die grundsätzlich die Auflösung mit einigen Qualitätsverlusten reduziert) sind sie sogar auf älterer Hardware lauffähig.
Wenn Sie jedoch keine Erfahrung mit LLMs haben, wird es schwierig sein, diese durchzuführen .
Der Grund, warum diese App existiert, ist (a) dass ich sie selbst implementieren wollte, um zu sehen, wie sie ergonomisch funktioniert, und (b) ich eine sehr einfache Ebene für die Interaktion mit diesen Dingen bereitstellen wollte, ohne mir Gedanken über die Einrichtung von PyTorch machen zu müssen Transformatoren vor Ort.
Sie installieren lediglich die App, laden ein Modell herunter und schon kann es losgehen.
Für die Ausführung dieser App ist ein einigermaßen aktueller Computer erforderlich. Allerdings ist diese App auf LLMs angewiesen, die bekanntermaßen stromhungrig sind. Daher bestimmt Ihre Computerhardware, welche Modelle Sie ausführen können.
Die „normalen“ Modelle benötigen wahrscheinlich eine dedizierte Grafikkarte mit etwa 6 bis 18 GB Videospeicher, es sei denn, Sie sind bereit, mehr als eine Sekunde pro Wort zu warten.
Viele Modelle liegen heutzutage in quantisierter Form vor, wodurch die größeren Modelle auch für ältere oder leistungsschwächere Hardware verfügbar sind. Die Quantisierung reduziert manchmal die Systemanforderungen selbst zu großer Modelle erheblich, ohne dass es zu großen Qualitätsverlusten kommt (Ihre Laufleistung kann jedoch von Modell zu Modell variieren).
Wichtig
Da es sich um ein großes Sprachmodell handelt, wird die Generierung von Antworten einige Zeit in Anspruch nehmen. Wenn Sie also keine dedizierte GPU in Ihrem Computer haben, haben Sie bitte etwas Geduld oder probieren Sie ein kleineres Modell aus.
Tipp
Die vollständige Dokumentation finden Sie auf der Website der App.
Die Benutzeroberfläche ist in drei Hauptkomponenten unterteilt:
Dieser Code ist über GNU GPL 3.0 lizenziert. Lesen Sie mehr in der LIZENZ-Datei.


