prometeo
1.0.0

Dabei handelt es sich um Prometeo, ein experimentelles Modellierungstool für eingebettetes Hochleistungsrechnen. prometeo stellt eine domänenspezifische Sprache (DSL) bereit, die auf einer Teilmenge der Python-Sprache basiert und es ermöglicht, wissenschaftliche Computerprogramme bequem in einer Hochsprache (Python selbst) zu schreiben, die problemlos in eigenständigen Hochleistungs-C-Code transpiliert werden kann einsetzbar auf eingebetteten Geräten.
Die Dokumentation von prometeo finden Sie unter „Read the Docs“ unter https://prometeo.readthedocs.io/en/latest/index.html.
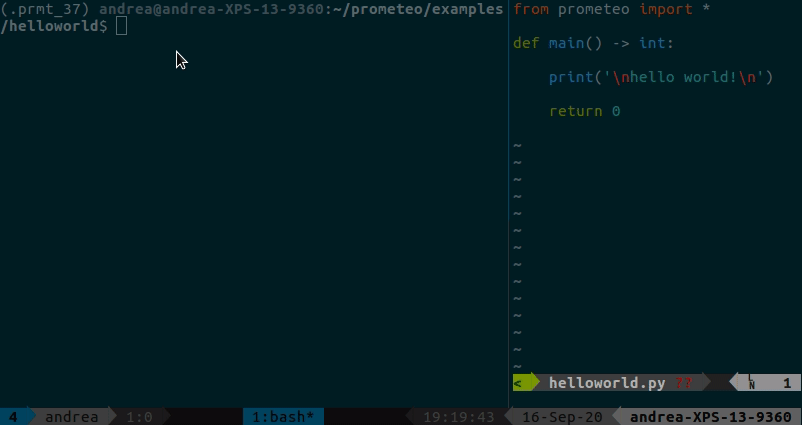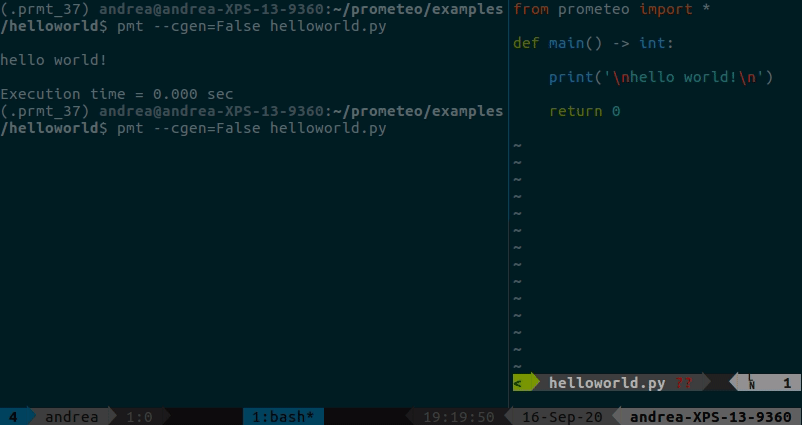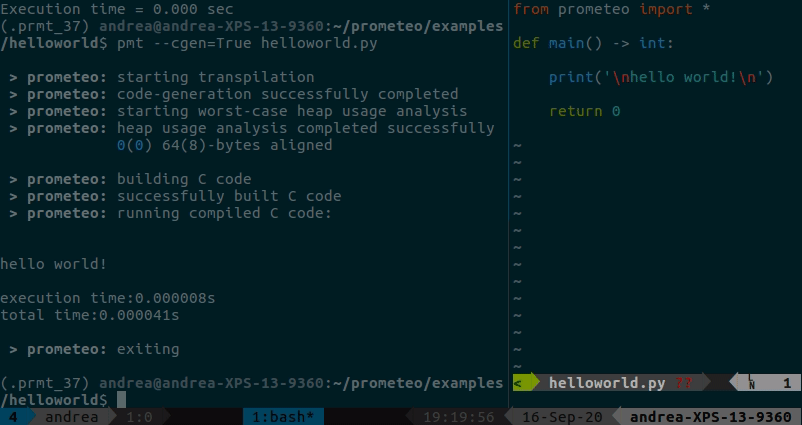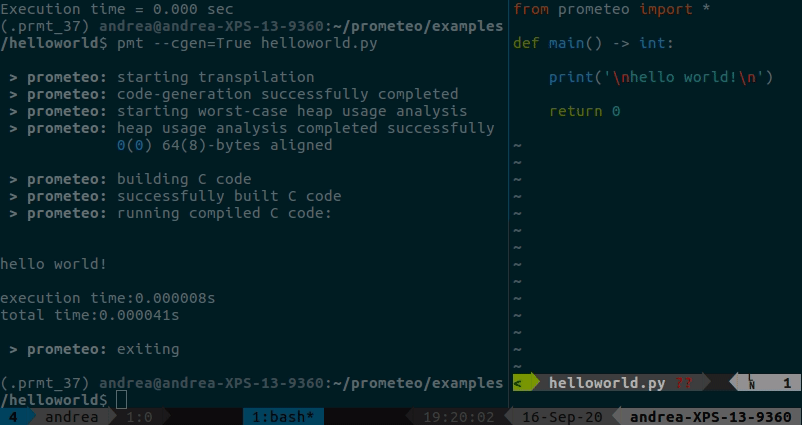
Ein einfaches Hallo-Welt-Beispiel, das zeigt, wie man entweder ein triviales Prometeo-Programm aus Python ausführt oder es nach C transpiliert, es erstellt und ausführt, finden Sie hier. Die Ausgabe zeigt das Ergebnis der Heap-Nutzungsanalyse und die Ausführungszeit (in diesem Fall gibt es nicht viel zu sehen :p).
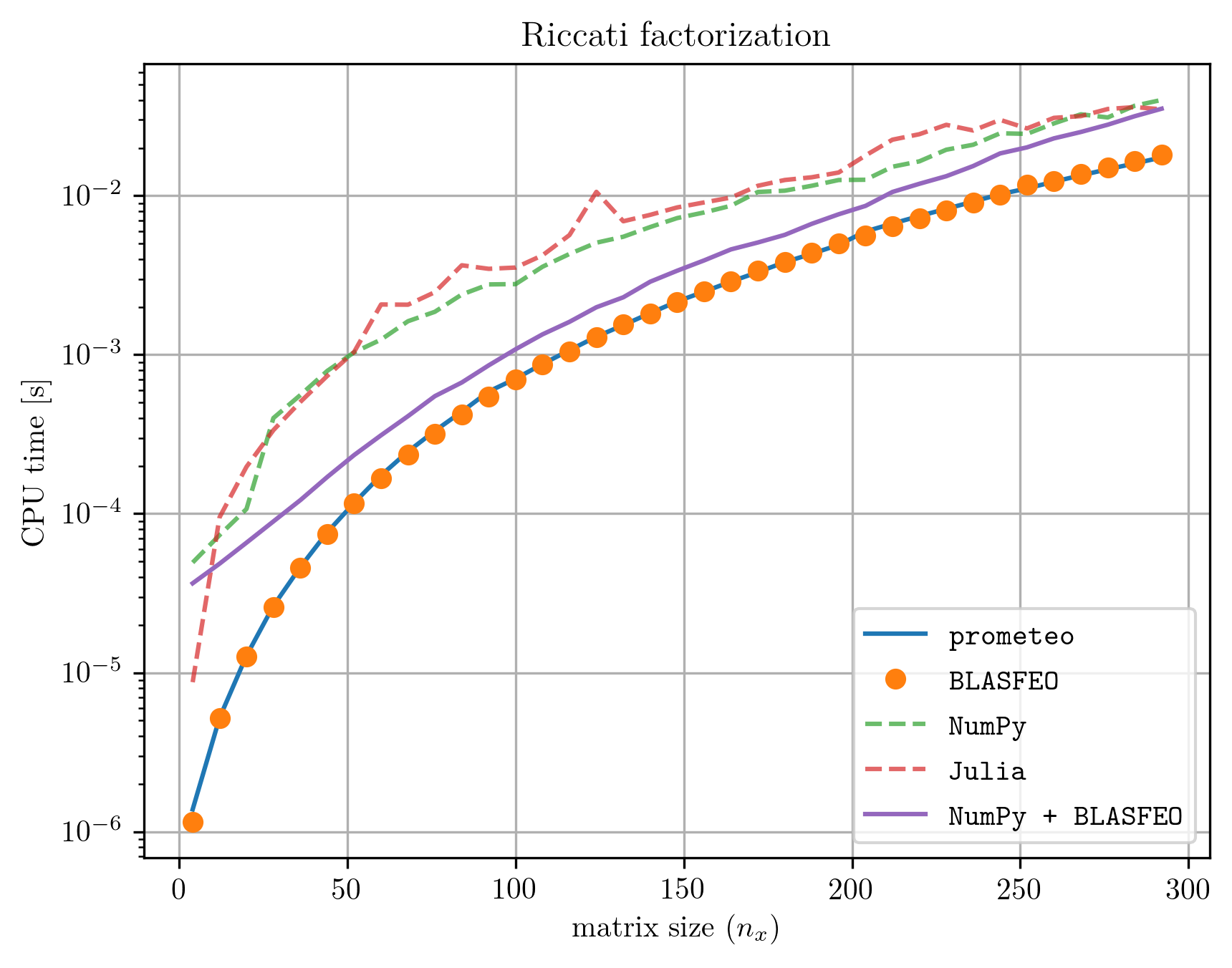
Da Prometeo-Programme in reinen C-Code transpilieren, der die leistungsstarke lineare Algebra-Bibliothek BLASFEO aufruft (Veröffentlichung: https://arxiv.org/abs/1704.02457, Code: https://github.com/giaf/blasfeo), kann die Ausführungszeit kürzer sein mit handgeschriebenem Hochleistungscode vergleichbar sein. Die folgende Abbildung zeigt einen Vergleich der CPU-Zeit, die erforderlich ist, um eine Riccati-Faktorisierung mit hochoptimiertem handgeschriebenem C-Code mit Aufrufen von BLASFEO durchzuführen, und denen, die mit prometeo-transpiliertem Code aus diesem Beispiel erhalten wurden. Zum Vergleich werden auch die mit NumPy und Julia erhaltenen Rechenzeiten hinzugefügt. Beachten Sie jedoch, dass diese beiden letzten Implementierungen der Riccati-Faktorisierung nicht so einfach einzubetten sind wie der von prometeo generierte C-Code und die handcodierte C-Implementierung. Alle Benchmarks wurden auf einem Dell XPS-9360 mit einer i7-7560U-CPU mit 2,30 GHz ausgeführt (um Frequenzschwankungen aufgrund thermischer Drosselung zu vermeiden).
Darüber hinaus kann prometeo modernste Python-Compiler wie Nuitka weit übertreffen. Die folgende Tabelle zeigt die CPU-Zeiten, die bei einem Fibonacci-Benchmark ermittelt wurden.
| Parser/Compiler | CPU-Zeit [s] |
|---|---|
| Python 3.7 (CPython) | 11.787 |
| Nuitka | 10.039 |
| PyPy | 1,78 |
| prometeo | 0,657 |
prometeo kann über PyPI mit pip install prometeo-dsl installiert werden. Beachten Sie, dass prometeo in großem Umfang Typhinweise nutzt, um Python-Code mit statischen Typisierungsinformationen auszustatten. Die erforderliche Mindestversion von Python ist 3.6.
Wenn Sie prometeo zum Erstellen der Quellen auf Ihrem lokalen Computer installieren möchten, können Sie wie folgt vorgehen:
git submodule update --init aus, um die Submodule zu klonen.make install_shared unter <prometeo_root>/prometeo/cpmt aus, um die gemeinsam genutzte Bibliothek zu kompilieren und zu installieren, die dem C-Backend zugeordnet ist. Beachten Sie, dass der Standardinstallationspfad <prometeo_root>/prometeo/cpmt/install ist.virtualenv --python=<path_to_python3.6> <path_to_new_virtualenv> einrichten.pip install -e . von <prometeo_root> um das Python-Paket zu installieren. Schließlich können Sie die Beispiele in <root>/examples mit pmt <example_name>.py --cgen=<True/False> ausführen, wobei das Flag --cgen bestimmt, ob der Code vom Python-Interpreter oder vom C-Code ausgeführt wird generiert, kompiliert und ausgeführt.
Der Python-Code ( examples/simple_example/simple_example.py )
from prometeo import *
n : dims = 10
def main () -> int :
A : pmat = pmat ( n , n )
for i in range ( 10 ):
for j in range ( 10 ):
A [ i , j ] = 1.0
B : pmat = pmat ( n , n )
for i in range ( 10 ):
B [ 0 , i ] = 2.0
C : pmat = pmat ( n , n )
C = A * B
pmat_print ( C )
return 0 kann mit dem Standard-Python-Interpreter ausgeführt werden (Version >3.6 erforderlich) und führt die beschriebenen linearen Algebra-Operationen mit dem Befehl pmt simple_example.py --cgen=False aus. Gleichzeitig kann der Code von prometeo geparst und sein abstrakter Syntaxbaum (AST) analysiert werden, um den folgenden leistungsstarken C-Code zu generieren:
#include "stdlib.h"
#include "simple_example.h"
void * ___c_pmt_8_heap ;
void * ___c_pmt_64_heap ;
void * ___c_pmt_8_heap_head ;
void * ___c_pmt_64_heap_head ;
#include "prometeo.h"
int main () {
___c_pmt_8_heap = malloc ( 10000 );
___c_pmt_8_heap_head = ___c_pmt_8_heap ;
char * pmem_ptr = ( char * ) ___c_pmt_8_heap ;
align_char_to ( 8 , & pmem_ptr );
___c_pmt_8_heap = pmem_ptr ;
___c_pmt_64_heap = malloc ( 1000000 );
___c_pmt_64_heap_head = ___c_pmt_64_heap ;
pmem_ptr = ( char * ) ___c_pmt_64_heap ;
align_char_to ( 64 , & pmem_ptr );
___c_pmt_64_heap = pmem_ptr ;
void * callee_pmt_8_heap = ___c_pmt_8_heap ;
void * callee_pmt_64_heap = ___c_pmt_64_heap ;
struct pmat * A = c_pmt_create_pmat ( n , n );
for ( int i = 0 ; i < 10 ; i ++ ) {
for ( int j = 0 ; j < 10 ; j ++ ) {
c_pmt_pmat_set_el ( A , i , j , 1.0 );
}
}
struct pmat * B = c_pmt_create_pmat ( n , n );
for ( int i = 0 ; i < 10 ; i ++ ) {
c_pmt_pmat_set_el ( B , 0 , i , 2.0 );
}
struct pmat * C = c_pmt_create_pmat ( n , n );
c_pmt_pmat_fill ( C , 0.0 );
c_pmt_gemm_nn ( A , B , C , C );
c_pmt_pmat_print ( C );
___c_pmt_8_heap = callee_pmt_8_heap ;
___c_pmt_64_heap = callee_pmt_64_heap ;
free ( ___c_pmt_8_heap_head );
free ( ___c_pmt_64_heap_head );
return 0 ;
} das auf dem leistungsstarken linearen Algebra-Paket BLASFEO basiert. Der generierte Code kann problemlos kompiliert und ausgeführt werden, wenn pmt simple_example.py --cgen=True ausgeführt wird.
Obwohl die Übersetzung eines in einer Sprache geschriebenen Programms in eine andere mit einem vergleichbaren Abstraktionsniveau erheblich einfacher sein kann als die Übersetzung in eine Sprache mit einem ganz anderen Abstraktionsniveau (insbesondere, wenn die Zielsprache ein viel niedrigeres Niveau hat), ist die Übersetzung von Python-Programmen in C-Programme möglich Da es immer noch eine beträchtliche Abstraktionslücke gibt, ist es im Allgemeinen keine leichte Aufgabe. Grob gesagt liegt die Herausforderung in der Notwendigkeit, Funktionen, die von der Quellsprache nativ unterstützt werden, in der Zielsprache erneut zu implementieren. Insbesondere bei der Übersetzung von Python nach C ergibt sich die Schwierigkeit sowohl aus dem unterschiedlichen Abstraktionsniveau der beiden Sprachen als auch aus der Tatsache, dass Quell- und Zielsprache von zwei sehr unterschiedlichen Typen sind: Python ist ein interpretiertes , ducktypisiertes und Müll -Sammelsprache und C ist eine kompilierte und statisch typisierte Sprache.
Die Aufgabe, Python nach C zu transpilieren, wird noch anspruchsvoller, wenn wir die Einschränkung hinzufügen, dass der generierte C-Code effizient (auch für kleine bis mittlere Berechnungen) und auf eingebetteter Hardware einsetzbar sein muss. Tatsächlich implizieren diese beiden Anforderungen direkt, dass der generierte Code Folgendes nicht nutzen kann: i) hochentwickelte Laufzeitbibliotheken, z. B. die Python-Laufzeitbibliothek, die im Allgemeinen auf eingebetteter Hardware nicht verfügbar sind, ii) dynamische Speicherzuweisung, die die Ausführung langsam und unzuverlässig machen würde (Ausnahme: Speicher, der in einer Setup-Phase zugewiesen wird und dessen Größe a priori bekannt ist).
Da die Source-to-Source-Codetransformation oder Transpilation und insbesondere die Transpilation von Python-Code in C-Code kein unerforschtes Gebiet ist, erwähnen wir im Folgenden einige bestehende Projekte, die sich damit befassen. Dabei machen wir deutlich, wo und wie sie eine der beiden oben genannten Anforderungen, nämlich (Kleinmaßstabs-)Effizienz und Einbettbarkeit, nicht erfüllen.
Es gibt mehrere Softwarepakete, die sich in verschiedenen Formen mit der Python-zu-C-Übersetzung befassen.
Im Kontext des Hochleistungsrechnens ist Numba ein in Python geschriebener Just-in-Time-Compiler für numerische Funktionen. Ziel ist es daher, ordnungsgemäß annotierte Python-Funktionen und nicht ganze Programme in leistungsstarken LLVM-Code umzuwandeln, sodass ihre Ausführung beschleunigt werden kann. Numba verwendet eine interne Darstellung des zu übersetzenden Codes und führt eine (möglicherweise teilweise) Typinferenz auf die beteiligten Variablen durch, um LLVM-Code zu generieren, der entweder von Python oder von C/C++ aus aufgerufen werden kann. In einigen Fällen, insbesondere in Fällen, in denen eine vollständige Typinferenz erfolgreich durchgeführt werden kann, kann Code generiert werden, der nicht auf der C-API basiert (mithilfe des Nopython -Flags). Der ausgegebene LLVM-Code würde jedoch für BLAS- und LAPACK-Vorgänge weiterhin auf Numpy basieren.
Nuitka ist ein Source-to-Source-Compiler, der jedes Python-Konstrukt in C-Code übersetzen kann, der mit der libpython -Bibliothek verknüpft ist, und daher in der Lage ist, eine große Klasse von Python-Programmen zu transpilieren. Dabei stützt es sich auf die Tatsache, dass eine der am häufigsten verwendeten Implementierungen der Python-Sprache, nämlich CPython , in C geschrieben ist. Tatsächlich generiert Nuitka C-Code, der Aufrufe an CPython enthält, die normalerweise von ausgeführt würden der Python-Parser. Trotz seines attraktiven und allgemeinen Transpilationsansatzes kann es aufgrund seiner intrinsischen Abhängigkeit von libpython nicht einfach auf eingebetteter Hardware bereitgestellt werden. Da es Python-Konstrukte ziemlich genau auf ihre CPython- Implementierung abbildet, ist gleichzeitig mit einer Reihe von Leistungsproblemen zu rechnen, wenn es um Hochleistungsrechnen im kleinen bis mittleren Maßstab geht. Dies liegt insbesondere daran, dass auch Vorgänge im Zusammenhang mit Typprüfung, Speicherzuweisung und Garbage Collection, die die Ausführung verlangsamen können, vom transpilierten Programm ausgeführt werden.
Cython ist eine Programmiersprache, deren Ziel es ist, das Schreiben von C-Erweiterungen für die Python-Sprache zu erleichtern. Insbesondere kann es (optional) statisch typisierten Python-ähnlichen Code in C-Code übersetzen, der auf CPython basiert. Ähnlich wie bei den Überlegungen zu Nuitka macht dies es zu einem leistungsstarken Werkzeug, wann immer es möglich ist, sich auf libpython zu verlassen (und wenn sein Overhead vernachlässigbar ist, d. h. wenn es um ausreichend große Berechnungen geht), aber nicht in dem hier interessierenden Kontext.
Obwohl Python nicht als Quellsprache verwendet wird, sollten wir schließlich erwähnen, dass auch Julia just-in-time (und teilweise vorzeitig) in LLVM-Code kompiliert wird. Der ausgegebene LLVM-Code basiert jedoch auf der Julia- Laufzeitbibliothek, sodass ähnliche Überlegungen gelten wie für Cython und Nuitka .
Die Transpilierung von Programmen, die mit einer eingeschränkten Teilmenge der Python-Sprache geschrieben wurden, in C-Programme erfolgt mit dem Transpiler von prometeo . Dieses Quelle-zu-Quelle-Transformationstool analysiert abstrakte Syntaxbäume (AST), die mit den zu transpilierenden Quelldateien verknüpft sind, um leistungsstarken und einbettbaren C-Code auszugeben. Dazu müssen dem Python-Code besondere Regeln auferlegt werden. Dies ermöglicht die ansonsten äußerst anspruchsvolle Aufgabe, eine interpretierte, hochstufige Entensprache in eine kompilierte, statisch typisierte, niedrige Stufe zu transpilieren. Dabei definieren wir, was manchmal als eingebettetes DSL bezeichnet wird, in dem Sinne, dass die resultierende Sprache die Syntax einer Hostsprache (Python selbst) verwendet und im Fall von prometeo auch vom Standard-Python-Interpreter ausgeführt werden kann .
from prometeo import *
nx : dims = 2
nu : dims = 2
nxu : dims = nx + nu
N : dims = 5
def main () -> int :
# number of repetitions for timing
nrep : int = 10000
A : pmat = pmat ( nx , nx )
A [ 0 , 0 ] = 0.8
A [ 0 , 1 ] = 0.1
A [ 1 , 0 ] = 0.3
A [ 1 , 1 ] = 0.8
B : pmat = pmat ( nx , nu )
B [ 0 , 0 ] = 1.0
B [ 1 , 1 ] = 1.0
Q : pmat = pmat ( nx , nx )
Q [ 0 , 0 ] = 1.0
Q [ 1 , 1 ] = 1.0
R : pmat = pmat ( nu , nu )
R [ 0 , 0 ] = 1.0
R [ 1 , 1 ] = 1.0
A : pmat = pmat ( nx , nx )
B : pmat = pmat ( nx , nu )
Q : pmat = pmat ( nx , nx )
R : pmat = pmat ( nu , nu )
RSQ : pmat = pmat ( nxu , nxu )
Lxx : pmat = pmat ( nx , nx )
M : pmat = pmat ( nxu , nxu )
w_nxu_nx : pmat = pmat ( nxu , nx )
BAt : pmat = pmat ( nxu , nx )
BA : pmat = pmat ( nx , nxu )
pmat_hcat ( B , A , BA )
pmat_tran ( BA , BAt )
RSQ [ 0 : nu , 0 : nu ] = R
RSQ [ nu : nu + nx , nu : nu + nx ] = Q
# array-type Riccati factorization
for i in range ( nrep ):
pmt_potrf ( Q , Lxx )
M [ nu : nu + nx , nu : nu + nx ] = Lxx
for i in range ( 1 , N ):
pmt_trmm_rlnn ( Lxx , BAt , w_nxu_nx )
pmt_syrk_ln ( w_nxu_nx , w_nxu_nx , RSQ , M )
pmt_potrf ( M , M )
Lxx [ 0 : nx , 0 : nx ] = M [ nu : nu + nx , nu : nu + nx ]
return 0 Ebenso kann der obige Code ( example/riccati/riccati_array.py ) vom Standard-Python-Interpreter mit dem Befehl pmt riccati_array.py --cgen=False ausgeführt werden, und prometeo kann C-Code stattdessen mit pmt riccati_array.py --cgen=True generieren, kompilieren und ausführen pmt riccati_array.py --cgen=True .
Um nach C transpilieren zu können, wird nur eine Teilmenge der Python-Sprache unterstützt. Allerdings werden nicht C-ähnliche Funktionen wie Funktionsüberladung und Klassen vom Transpiler von prometeo unterstützt. Das angepasste Riccati-Beispiel ( examples/riccati/riccati_mass_spring_2.py ) unten zeigt, wie Klassen erstellt und verwendet werden können.
from prometeo import *
nm : dims = 4
nx : dims = 2 * nm
sizes : dimv = [[ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ]]
nu : dims = nm
nxu : dims = nx + nu
N : dims = 5
class qp_data :
A : List = plist ( pmat , sizes )
B : List = plist ( pmat , sizes )
Q : List = plist ( pmat , sizes )
R : List = plist ( pmat , sizes )
P : List = plist ( pmat , sizes )
fact : List = plist ( pmat , sizes )
def factorize ( self ) -> None :
M : pmat = pmat ( nxu , nxu )
Mxx : pmat = pmat ( nx , nx )
L : pmat = pmat ( nxu , nxu )
Q : pmat = pmat ( nx , nx )
R : pmat = pmat ( nu , nu )
BA : pmat = pmat ( nx , nxu )
BAtP : pmat = pmat ( nxu , nx )
pmat_copy ( self . Q [ N - 1 ], self . P [ N - 1 ])
pmat_hcat ( self . B [ N - 1 ], self . A [ N - 1 ], BA )
pmat_copy ( self . Q [ N - 1 ], Q )
pmat_copy ( self . R [ N - 1 ], R )
for i in range ( 1 , N ):
pmat_fill ( BAtP , 0.0 )
pmt_gemm_tn ( BA , self . P [ N - i ], BAtP , BAtP )
pmat_fill ( M , 0.0 )
M [ 0 : nu , 0 : nu ] = R
M [ nu : nu + nx , nu : nu + nx ] = Q
pmt_gemm_nn ( BAtP , BA , M , M )
pmat_fill ( L , 0.0 )
pmt_potrf ( M , L )
Mxx [ 0 : nx , 0 : nx ] = L [ nu : nu + nx , nu : nu + nx ]
# pmat_fill(self.P[N-i-1], 0.0)
pmt_gemm_nt ( Mxx , Mxx , self . P [ N - i - 1 ], self . P [ N - i - 1 ])
# pmat_print(self.P[N-i-1])
return
def main () -> int :
A : pmat = pmat ( nx , nx )
Ac11 : pmat = pmat ( nm , nm )
Ac12 : pmat = pmat ( nm , nm )
for i in range ( nm ):
Ac12 [ i , i ] = 1.0
Ac21 : pmat = pmat ( nm , nm )
for i in range ( nm ):
Ac21 [ i , i ] = - 2.0
for i in range ( nm - 1 ):
Ac21 [ i + 1 , i ] = 1.0
Ac21 [ i , i + 1 ] = 1.0
Ac22 : pmat = pmat ( nm , nm )
for i in range ( nm ):
for j in range ( nm ):
A [ i , j ] = Ac11 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ i , nm + j ] = Ac12 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ nm + i , j ] = Ac21 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ nm + i , nm + j ] = Ac22 [ i , j ]
tmp : float = 0.0
for i in range ( nx ):
tmp = A [ i , i ]
tmp = tmp + 1.0
A [ i , i ] = tmp
B : pmat = pmat ( nx , nu )
for i in range ( nu ):
B [ nm + i , i ] = 1.0
Q : pmat = pmat ( nx , nx )
for i in range ( nx ):
Q [ i , i ] = 1.0
R : pmat = pmat ( nu , nu )
for i in range ( nu ):
R [ i , i ] = 1.0
qp : qp_data = qp_data ()
for i in range ( N ):
qp . A [ i ] = A
for i in range ( N ):
qp . B [ i ] = B
for i in range ( N ):
qp . Q [ i ] = Q
for i in range ( N ):
qp . R [ i ] = R
qp . factorize ()
return 0Haftungsausschluss: prometeo befindet sich noch in einem sehr frühen Stadium und derzeit werden nur wenige lineare Algebra-Operationen und Python-Konstrukte unterstützt.


