LaTeX OCR
1.0.0
Das Ziel dieses Projekts besteht darin, ein lernbasiertes System zu erstellen, das ein Bild einer mathematischen Formel aufnimmt und entsprechenden LaTeX-Code zurückgibt.
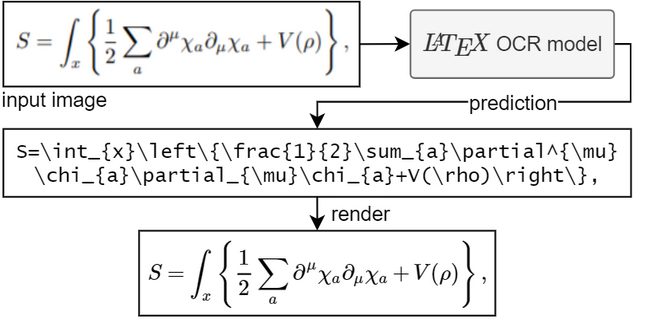
Zum Ausführen des Modells benötigen Sie Python 3.7+
Wenn Sie PyTorch nicht installiert haben. Befolgen Sie die Anweisungen hier.
Installieren Sie das Paket pix2tex :
pip install "pix2tex[gui]"
Modellprüfpunkte werden automatisch heruntergeladen.
Es gibt drei Möglichkeiten, eine Vorhersage aus einem Bild zu erhalten.
Sie können das Befehlszeilentool verwenden, indem Sie pix2tex aufrufen. Hier können Sie bereits vorhandene Bilder von der Festplatte und Bilder in Ihrer Zwischenablage analysieren.
Dank @katie-lim können Sie eine schöne Benutzeroberfläche verwenden, um schnell die Modellvorhersage zu erhalten. Rufen Sie einfach die GUI mit latexocr auf. Von hier aus können Sie einen Screenshot machen und der vorhergesagte Latexcode wird mit MathJax gerendert und in Ihre Zwischenablage kopiert.
Unter Linux ist es möglich, die GUI mit gnome-screenshot (das mehrere Monitore unterstützt) zu verwenden, wenn gnome-screenshot zuvor installiert wurde. Für Wayland werden grim und slurp verwendet, wenn beide verfügbar sind. Beachten Sie, dass gnome-screenshot nicht mit wlroots-basierten Wayland-Compositoren kompatibel ist. Da gnome-screenshot bevorzugt wird, wenn verfügbar, müssen Sie in diesem Fall möglicherweise die Umgebungsvariable SCREENSHOT_TOOL auf grim setzen (andere verfügbare Werte sind gnome-screenshot und pil ).
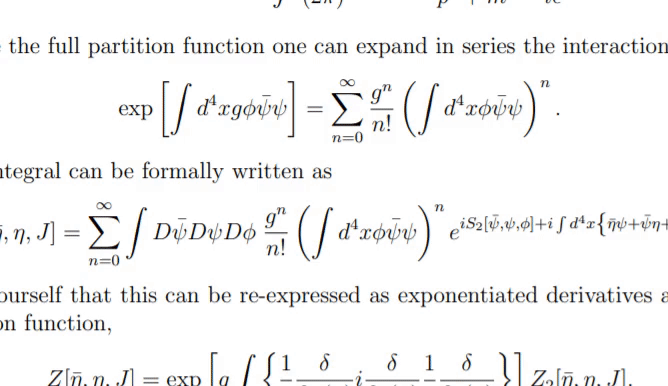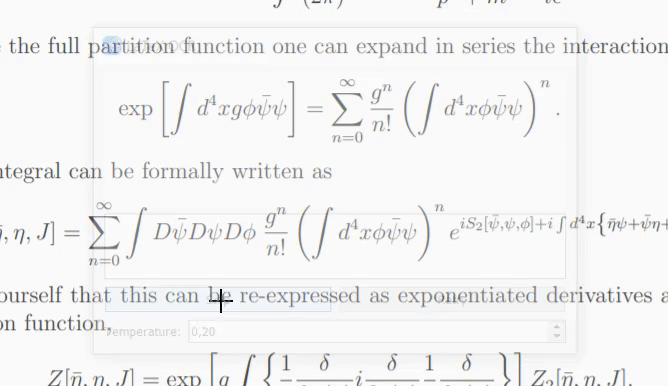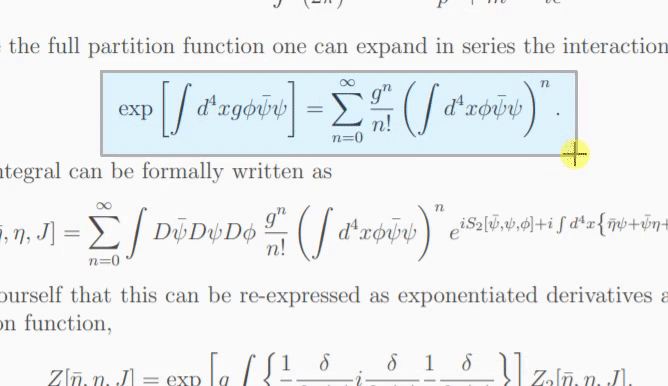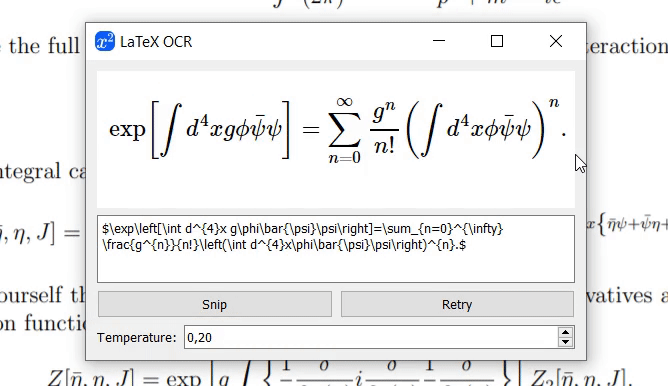
Wenn das Modell nicht sicher ist, was im Bild enthalten ist, gibt es möglicherweise jedes Mal eine andere Vorhersage aus, wenn Sie auf „Wiederholen“ klicken. Mit dem temperature können Sie dieses Verhalten steuern (niedrige Temperatur führt zum gleichen Ergebnis).
Sie können eine API verwenden. Dies hat zusätzliche Abhängigkeiten. Über pip install -U "pix2tex[api]" installieren und ausführen
python -m pix2tex.api.run
um eine Streamlit-Demo zu starten, die eine Verbindung zur API an Port 8502 herstellt. Für die API ist auch ein Docker-Image verfügbar: https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
Um auch den Streamlit-Demolauf durchzuführen
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
und navigieren Sie zu http://localhost:8501/
Verwendung innerhalb von Python
from PIL import Imagefrom pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))Das Modell funktioniert am besten mit Bildern kleinerer Auflösung. Deshalb habe ich einen Vorverarbeitungsschritt hinzugefügt, bei dem ein anderes neuronales Netzwerk die optimale Auflösung des Eingabebildes vorhersagt. Dieses Modell passt die Größe des benutzerdefinierten Bilds automatisch so an, dass es den Trainingsdaten am besten ähnelt, und erhöht so die Leistung von Bildern, die in freier Wildbahn gefunden werden. Trotzdem ist es nicht perfekt und möglicherweise nicht in der Lage, große Bilder optimal zu verarbeiten. Zoomen Sie also nicht ganz hinein, bevor Sie ein Bild aufnehmen.
Überprüfen Sie das Ergebnis immer sorgfältig. Sie können versuchen, die Vorhersage mit einer anderen Auflösung zu wiederholen, wenn die Antwort falsch war.
Möchten Sie das Paket nutzen?
Ich versuche gerade eine Dokumentation zusammenzustellen.
Besuchen Sie hier: https://pix2tex.readthedocs.io/
Installieren Sie ein paar Abhängigkeiten pip install "pix2tex[train]" .
Zuerst müssen wir die Bilder mit ihren Grundwahrheitsbezeichnungen kombinieren. Ich habe eine Datensatzklasse geschrieben (die noch verbessert werden muss), die die relativen Pfade zu den Bildern mit dem LaTeX-Code speichert, mit dem sie gerendert wurden. Um den Datensatz zu generieren, führen Sie die Pickle-Datei aus
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
Um Ihren eigenen Tokenizer zu verwenden, übergeben Sie ihn über --tokenizer (siehe unten).
Meine generierten Trainingsdaten finden Sie auch auf Google Drive (formulae.zip – Bilder, math.txt – Beschriftungen). Wiederholen Sie den Schritt für die Validierungs- und Testdaten. Alle verwenden dieselbe Etikettentextdatei.
Bearbeiten Sie den Eintrag data (und valdata ) in der Konfigurationsdatei in die neu generierte .pkl Datei. Ändern Sie andere Hyperparameter, wenn Sie möchten. Eine Vorlage finden Sie unter pix2tex/model/settings/config.yaml .
Nun zum eigentlichen Trainingslauf
python -m pix2tex.train --config path_to_config_file
Wenn Sie Ihre eigenen Daten verwenden möchten, könnten Sie daran interessiert sein, Ihren eigenen Tokenizer mit zu erstellen
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
Vergessen Sie nicht, den Pfad zum Tokenizer in der Konfigurationsdatei zu aktualisieren und num_tokens auf Ihre Vokabulargröße festzulegen.
Das Modell besteht aus einem ViT-Encoder [1] mit einem ResNet-Backbone und einem Transformer-Decoder [2].
| BLEU-Score | normierter Bearbeitungsabstand | Token-Genauigkeit |
|---|---|---|
| 0,88 | 0,10 | 0,60 |
Wir benötigen gepaarte Daten, damit das Netzwerk lernen kann. Glücklicherweise gibt es im Internet jede Menge LaTeX-Code, z. B. Wikipedia, arXiv. Wir verwenden auch die Formeln aus dem Datensatz im2latex-100k [3]. Alles davon finden Sie hier
Um die Mathematik in vielen verschiedenen Schriftarten darzustellen, verwenden wir XeLaTeX, generieren ein PDF und konvertieren es schließlich in ein PNG. Für den letzten Schritt müssen wir einige Tools von Drittanbietern verwenden:
XeLaTeX
ImageMagick mit Ghostscript. (zum Konvertieren von PDF in PNG)
Node.js zum Ausführen von KaTeX (zur Normalisierung von Latex-Code)
Python 3.7+ und Abhängigkeiten (angegeben in setup.py )
Lateinische moderne Mathematik, GFSNeohellenicMath.otf, Asana Math, XITS Math, Cambria Math
Fügen Sie weitere Bewertungsmetriken hinzu
Erstellen Sie eine GUI
Strahlsuche hinzufügen
Unterstützung handschriftlicher Formeln (irgendwie erledigt, siehe Schulungs-Colab-Notizbuch)
Modellgröße reduzieren (Destillation)
Finden Sie optimale Hyperparameter
Modellstruktur optimieren
Beheben Sie das Daten-Scraping und scrapen Sie mehr Daten
Verfolgen Sie das Modell (#2)
Beiträge jeglicher Art sind willkommen.
Code übernommen und geändert von lucidrains, rwightman, im2markup, arxiv_leaks, pkra: Mathjax, harupy: snipping tool
[1] Ein Bild sagt mehr als 16x16 Worte
[2] Aufmerksamkeit ist alles, was Sie brauchen
[3] Bild-zu-Markup-Generierung mit grober bis feiner Aufmerksamkeit


