segment anything
1.0.0
Bitte schauen Sie sich unsere neue Version zu Segment Anything Model 2 (SAM 2) an.
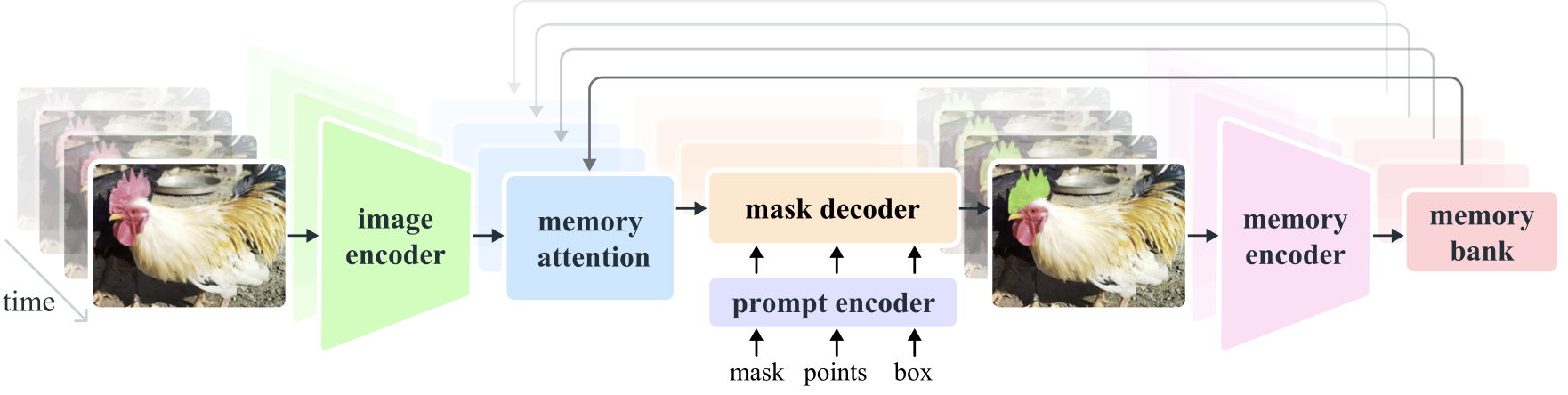
Segment Anything Model 2 (SAM 2) ist ein grundlegendes Modell zur Lösung einer aufforderungsgerechten visuellen Segmentierung in Bildern und Videos. Wir erweitern SAM auf Video, indem wir Bilder als Video mit einem einzelnen Frame betrachten. Das Modelldesign ist eine einfache Transformatorarchitektur mit Streaming-Speicher für die Echtzeit-Videoverarbeitung. Wir bauen eine Model-in-the-Loop-Daten-Engine auf, die Modelle und Daten durch Benutzerinteraktion verbessert, um unseren SA-V-Datensatz zu sammeln, den bislang größten Videosegmentierungsdatensatz. SAM 2, das auf unseren Daten trainiert wurde, bietet eine starke Leistung in einem breiten Spektrum von Aufgaben und visuellen Bereichen.
Meta-KI-Forschung, FAIR
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
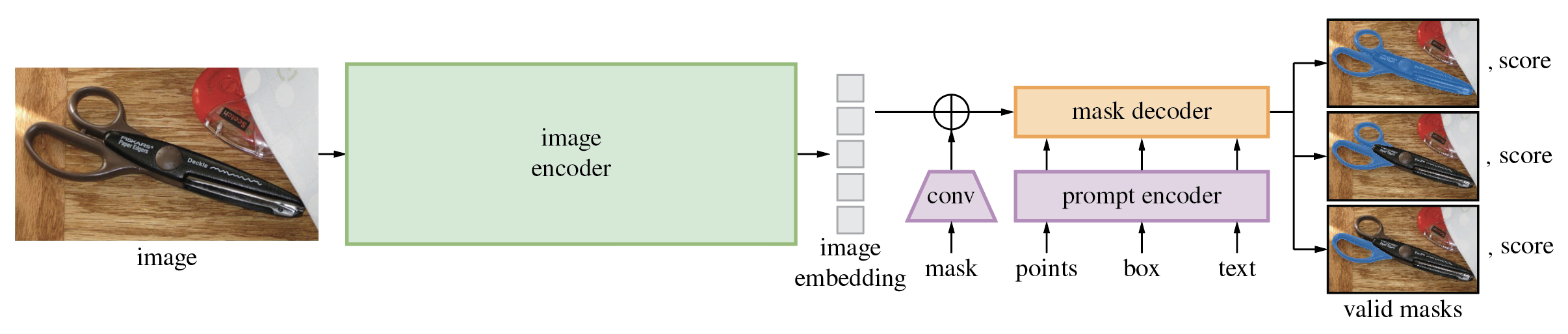
Das Segment Anything Model (SAM) erzeugt aus Eingabeaufforderungen wie Punkten oder Kästchen hochwertige Objektmasken und kann zur Generierung von Masken für alle Objekte in einem Bild verwendet werden. Es wurde anhand eines Datensatzes von 11 Millionen Bildern und 1,1 Milliarden Masken trainiert und weist bei einer Vielzahl von Segmentierungsaufgaben eine starke Zero-Shot-Leistung auf.


Der Code erfordert python>=3.8 sowie pytorch>=1.7 und torchvision>=0.8 . Bitte befolgen Sie die Anweisungen hier, um sowohl PyTorch- als auch TorchVision-Abhängigkeiten zu installieren. Es wird dringend empfohlen, sowohl PyTorch als auch TorchVision mit CUDA-Unterstützung zu installieren.
Installieren Sie Segment Anything:
pip install git+https://github.com/facebookresearch/segment-anything.git
oder das Repository lokal klonen und mit installieren
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
Die folgenden optionalen Abhängigkeiten sind für die Maskennachbearbeitung, das Speichern von Masken im COCO-Format, die Beispielnotizbücher und den Export des Modells im ONNX-Format erforderlich. Zum Ausführen der Beispiel-Notebooks ist außerdem jupyter erforderlich.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
Laden Sie zunächst einen Modellprüfpunkt herunter. Dann kann das Modell in nur wenigen Zeilen verwendet werden, um Masken aus einer bestimmten Eingabeaufforderung abzurufen:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
oder Masken für ein ganzes Bild generieren:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
Zusätzlich können Masken für Bilder über die Befehlszeile generiert werden:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
Weitere Einzelheiten finden Sie in den Beispielnotizbüchern zur Verwendung von SAM mit Eingabeaufforderungen und zur automatischen Generierung von Masken.


Der leichte Maskendecoder von SAM kann in das ONNX-Format exportiert werden, sodass er in jeder Umgebung ausgeführt werden kann, die ONNX-Laufzeit unterstützt, z. B. im Browser, wie in der Demo gezeigt. Exportieren Sie das Modell mit
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
Einzelheiten zur Kombination der Bildvorverarbeitung über das SAM-Backbone mit der Maskenvorhersage mithilfe des ONNX-Modells finden Sie im Beispielnotizbuch. Es wird empfohlen, für den ONNX-Export die neueste stabile Version von PyTorch zu verwenden.
Der Ordner demo/ enthält eine einfache einseitige React-App, die zeigt, wie eine Maskenvorhersage mit dem exportierten ONNX-Modell in einem Webbrowser mit Multithreading ausgeführt wird. Weitere Informationen finden Sie demo/README.md .
Es stehen drei Modellvarianten des Modells mit unterschiedlichen Rückgratgrößen zur Verfügung. Diese Modelle können durch Ausführen instanziiert werden
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
Klicken Sie auf die untenstehenden Links, um den Prüfpunkt für den entsprechenden Modelltyp herunterzuladen.
default oder vit_h : ViT-H SAM-Modell.vit_l : ViT-L SAM-Modell.vit_b : ViT-B SAM-Modell. Hier finden Sie eine Übersicht über die Daten. Der Datensatz kann hier heruntergeladen werden. Durch das Herunterladen der Datensätze erklären Sie sich damit einverstanden, dass Sie die Bedingungen der SA-1B Dataset Research License gelesen und akzeptiert haben.
Wir speichern Masken pro Bild als JSON-Datei. Es kann als Wörterbuch in Python im folgenden Format geladen werden.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}Bild-IDs finden Sie in sa_images_ids.txt, das ebenfalls über den obigen Link heruntergeladen werden kann.
So dekodieren Sie eine Maske im COCO RLE-Format in Binärformat:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
Weitere Anweisungen zum Bearbeiten von im RLE-Format gespeicherten Masken finden Sie hier.
Das Modell ist unter der Apache 2.0-Lizenz lizenziert.
Siehe Beiträge und Verhaltenskodex.
Das Segment Anything-Projekt wurde durch die Hilfe vieler Mitwirkender ermöglicht (alphabetisch):
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, Mallika Malhotra, William Ngan, Omkar Parkhi, Nikhil Raina, Dirk Rowe, Neil Sejoor, Vanessa Stark, Bala Varadarajan, Bram Wasti, Zachary Winstrom
Wenn Sie SAM oder SA-1B in Ihrer Recherche verwenden, verwenden Sie bitte den folgenden BibTeX-Eintrag.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


