obfuscated gradients
v1.0.0
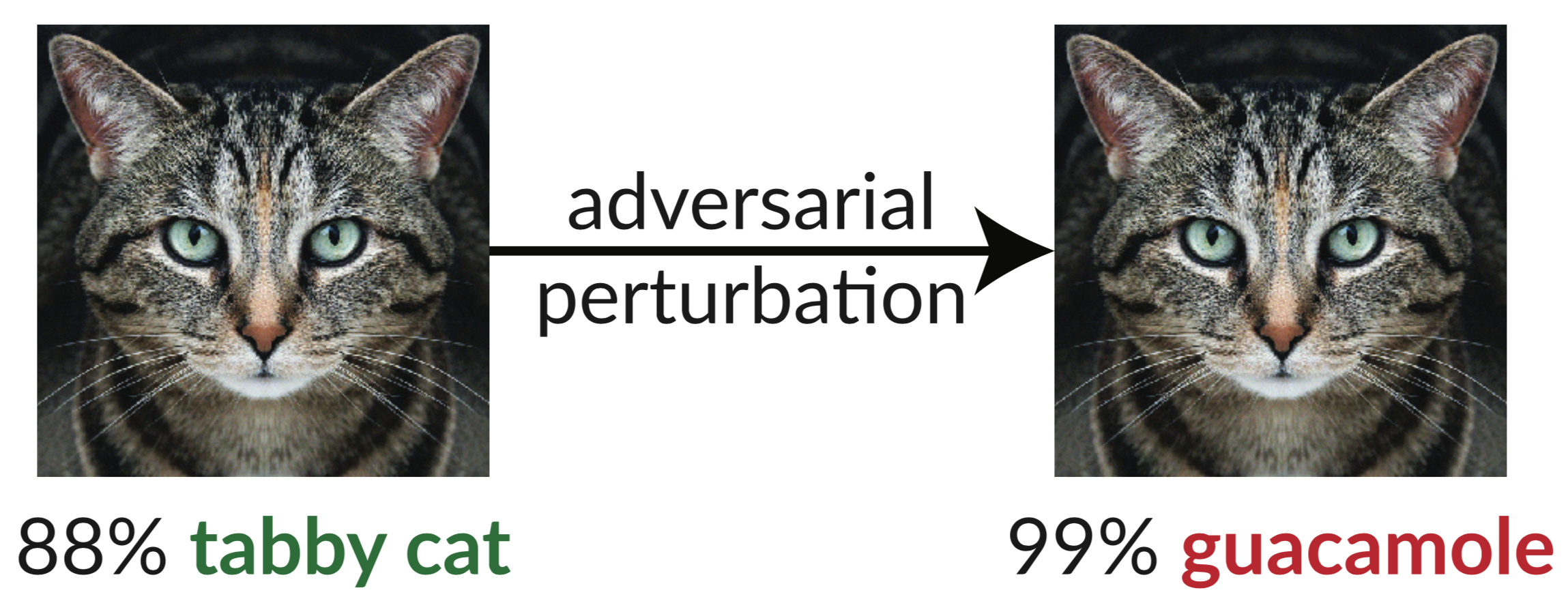
Oben ist ein kontroverses Beispiel: Das leicht verstörte Bild der Katze täuscht einen InceptionV3-Klassifikator vor, sie als „Guacamole“ zu klassifizieren. Solche „Täuschungsbilder“ lassen sich mithilfe des Gradientenabstiegs leicht synthetisieren (Szegedy et al. 2013).
In unserem aktuellen Artikel bewerten wir die Robustheit von neun Artikeln, die beim ICLR 2018 als nicht zertifizierte White-Box-sichere Verteidigung gegen gegnerische Beispiele akzeptiert wurden. Wir stellen fest, dass sieben der neun Abwehrmechanismen eine begrenzte Steigerung der Robustheit bieten und durch verbesserte Angriffstechniken, die wir entwickeln, durchbrochen werden können.
Unten finden Sie Tabelle 1 aus unserem Artikel, in der wir die Robustheit jeder akzeptierten Verteidigung gegenüber den gegnerischen Beispielen zeigen, die wir konstruieren können:
| Verteidigung | Datensatz | Distanz | Genauigkeit |
|---|---|---|---|
| Buckman et al. (2018) | CIFAR | 0,031 (linf) | 0%* |
| Ma et al. (2018) | CIFAR | 0,031 (linf) | 5 % |
| Guo et al. (2018) | ImageNet | 0,05 (l2) | 0%* |
| Dhillon et al. (2018) | CIFAR | 0,031 (linf) | 0% |
| Xie et al. (2018) | ImageNet | 0,031 (linf) | 0%* |
| Lied et al. (2018) | CIFAR | 0,031 (linf) | 9 %* |
| Samangouei et al. (2018) | MNIST | 0,005 (l2) | 55 %** |
| Madry et al. (2018) | CIFAR | 0,031 (linf) | 47 % |
| Na et al. (2018) | CIFAR | 0,015 (linf) | 15 % |
(Mit * gekennzeichnete Verteidigungen schlagen auch die Kombination von gegnerischem Training vor; wir berichten hier nur über die Verteidigung. Die vollständigen Zahlen finden Sie in unserem Artikel, Abschnitt 5. Das Grundprinzip hinter der mit ** gekennzeichneten Verteidigung weist eine Genauigkeit von 0 % auf; in der Praxis verursachen Defizite in der Verteidigung theoretisch die Ursache (Einzelheiten dazu finden Sie in Abschnitt 5.4.2.)
Die einzige Verteidigung, die wir beobachten und die die Robustheit gegenüber gegnerischen Beispielen innerhalb des vorgeschlagenen Bedrohungsmodells deutlich erhöht, ist „Towards Deep Learning Models Resistance to Adversarial Attacks“ (Madry et al. 2018), und wir konnten diese Verteidigung nicht besiegen, ohne das Bedrohungsmodell zu verlassen . Selbst damals hat sich gezeigt, dass diese Technik schwierig auf den ImageNet-Maßstab zu skalieren ist (Kurakin et al. 2016). Der Rest der Arbeiten (außer dem Artikel von Na et al., der eine begrenzte Robustheit bietet) stützt sich entweder versehentlich oder absichtlich auf das, was wir als verschleierte Gradienten bezeichnen. Standardangriffe wenden einen Gradientenabstieg an, um den Verlust des Netzwerks auf einem bestimmten Bild zu maximieren und ein gegnerisches Beispiel auf einem neuronalen Netzwerk zu erzeugen. Für den Erfolg solcher Optimierungsverfahren ist ein brauchbares Gradientensignal erforderlich. Wenn eine Verteidigung Gradienten verschleiert, unterbricht sie dieses Gradientensignal und führt dazu, dass optimierungsbasierte Methoden fehlschlagen.
Wir identifizieren drei Möglichkeiten, wie Abwehrmechanismen verschleierte Gradienten verursachen, und konstruieren Angriffe, um jeden dieser Fälle zu umgehen. Unsere Angriffe sind im Allgemeinen auf jede Verteidigung anwendbar, die absichtlich oder unabsichtlich eine nicht differenzierbare Operation einschließt oder auf andere Weise verhindert, dass ein Gradientensignal durch das Netzwerk fließt. Wir hoffen, dass zukünftige Arbeiten unsere Ansätze nutzen können, um eine gründlichere Sicherheitsbewertung durchzuführen.
Abstrakt:
Wir identifizieren verschleierte Gradienten, eine Art Gradientenmaskierung, als ein Phänomen, das zu einem falschen Sicherheitsgefühl bei der Abwehr gegnerischer Beispiele führt. Während Abwehrmaßnahmen, die verschleierte Farbverläufe verursachen, scheinbar iterative optimierungsbasierte Angriffe abwehren, stellen wir fest, dass Abwehrmaßnahmen, die auf diesem Effekt basieren, umgangen werden können. Wir beschreiben charakteristische Verhaltensweisen von Abwehrmechanismen, die diesen Effekt zeigen, und entwickeln für jede der drei Arten von verschleierten Gradienten, die wir entdecken, Angriffstechniken, um ihn zu überwinden. In einer Fallstudie, in der nicht zertifizierte White-Box-sichere Abwehrmaßnahmen auf der ICLR 2018 untersucht wurden, stellen wir fest, dass verschleierte Farbverläufe häufig vorkommen, wobei 7 von 9 Abwehrmaßnahmen auf verschleierten Farbverläufen basieren. Unsere neuen Angriffe umgehen erfolgreich 6 vollständig und 1 teilweise im ursprünglichen Bedrohungsmodell, das in jedem Artikel berücksichtigt wird.
Weitere Informationen finden Sie in unserem Artikel.
Dieses Repository enthält unsere Instanziierungen der in unserem Artikel beschriebenen allgemeinen Angriffstechniken, mit denen sieben der ICLR-2018-Abwehrmaßnahmen durchbrochen werden. Für einige der Verteidigungsmaßnahmen war der Quellcode noch nicht veröffentlicht (zu der Zeit, als wir diese Arbeit machten), also mussten wir sie neu implementieren.
@inproceedings{obfuscated-gradients, Autor = {Anish Athalye und Nicholas Carlini und David Wagner}, Titel = {Verschleierte Farbverläufe geben ein falsches Sicherheitsgefühl: Umgehung von Verteidigungsmaßnahmen gegen gegnerische Beispiele}, Buchtitel = {Proceedings of the 35th International Conference on Machine Lernen, {ICML} 2018}, Jahr = {2018}, Monat = Juli, URL = {https://arxiv.org/abs/1802.00420},
} 

