Megatron LM
NVIDIA Megatron Core 0.9.0
Dieses Repository besteht aus zwei wesentlichen Komponenten: Megatron-LM und Megatron-Core . Megatron-LM dient als forschungsorientiertes Framework, das Megatron-Core für das Training großer Sprachmodelle (LLM) nutzt. Megatron-Core hingegen ist eine Bibliothek GPU-optimierter Trainingstechniken, die formelle Produktunterstützung einschließlich versionierter APIs und regelmäßiger Releases bietet. Sie können Megatron-Core zusammen mit Megatron-LM oder Nvidia NeMo Framework für eine durchgängige und cloudnative Lösung verwenden. Alternativ können Sie die Bausteine von Megatron-Core in Ihr bevorzugtes Trainingsgerüst integrieren.
Megatron (1, 2 und 3) wurde erstmals 2019 eingeführt und löste eine Innovationswelle in der KI-Community aus, die es Forschern und Entwicklern ermöglichte, die Grundlagen dieser Bibliothek für weitere LLM-Fortschritte zu nutzen. Heutzutage wurden viele der beliebtesten LLM-Entwickler-Frameworks von der Open-Source-Bibliothek Megatron-LM inspiriert und direkt unter Nutzung dieser entwickelt, was eine Welle von Gründungsmodellen und KI-Startups anspornte. Zu den beliebtesten LLM-Frameworks, die auf Megatron-LM basieren, gehören Colossal-AI, HuggingFace Accelerate und NVIDIA NeMo Framework. Eine Liste der Projekte, die Megatron direkt genutzt haben, finden Sie hier.
Megatron-Core ist eine Open-Source-Bibliothek auf PyTorch-Basis, die GPU-optimierte Techniken und modernste Optimierungen auf Systemebene enthält. Es abstrahiert sie in zusammensetzbare und modulare APIs und bietet Entwicklern und Modellforschern die volle Flexibilität, benutzerdefinierte Transformatoren im großen Maßstab auf der beschleunigten Recheninfrastruktur von NVIDIA zu trainieren. Diese Bibliothek ist mit allen NVIDIA Tensor Core-GPUs kompatibel, einschließlich FP8-Beschleunigungsunterstützung für NVIDIA Hopper-Architekturen.
Megatron-Core bietet Kernbausteine wie Aufmerksamkeitsmechanismen, Transformatorblöcke und -schichten, Normalisierungsschichten und Einbettungstechniken. Zusätzliche Funktionen wie Aktivierungsneuberechnung und verteiltes Checkpointing sind ebenfalls nativ in die Bibliothek integriert. Die Bausteine und Funktionen sind alle GPU-optimiert und können mit fortschrittlichen Parallelisierungsstrategien für optimale Trainingsgeschwindigkeit und Stabilität auf der NVIDIA Accelerated Computing Infrastructure erstellt werden. Eine weitere Schlüsselkomponente der Megatron-Core-Bibliothek umfasst fortgeschrittene Modellparallelitätstechniken (Tensor-, Sequenz-, Pipeline-, Kontext- und MoE-Expertenparallelität).
Megatron-Core kann mit NVIDIA NeMo verwendet werden, einer KI-Plattform der Enterprise-Klasse. Alternativ können Sie Megatron-Core hier mit der nativen PyTorch-Trainingsschleife erkunden. Besuchen Sie die Megatron-Core-Dokumentation, um mehr zu erfahren.
Unsere Codebasis ist in der Lage, große Sprachmodelle (dh Modelle mit Hunderten Milliarden Parametern) sowohl mit Modell- als auch mit Datenparallelität effizient zu trainieren. Um zu demonstrieren, wie unsere Software mit mehreren GPUs und Modellgrößen skaliert, betrachten wir GPT-Modelle mit einem Bereich von 2 Milliarden Parametern bis 462 Milliarden Parametern. Alle Modelle verwenden eine Vokabulargröße von 131.072 und eine Sequenzlänge von 4096. Wir variieren die versteckte Größe, die Anzahl der Aufmerksamkeitsköpfe und die Anzahl der Ebenen, um eine bestimmte Modellgröße zu erhalten. Mit zunehmender Modellgröße erhöhen wir auch geringfügig die Chargengröße. Unsere Experimente nutzen bis zu 6144 H100-GPUs. Wir führen eine feinkörnige Überlappung von datenparalleler ( --overlap-grad-reduce --overlap-param-gather ), tensorparalleler ( --tp-comm-overlap ) und Pipeline-paralleler Kommunikation (standardmäßig aktiviert) durch Berechnung zur Verbesserung der Skalierbarkeit. Die gemeldeten Durchsätze werden für End-to-End-Schulungen gemessen und umfassen alle Vorgänge, einschließlich Datenladen, Optimierungsschritte, Kommunikation und sogar Protokollierung. Beachten Sie, dass wir diese Modelle nicht auf Konvergenz trainiert haben.
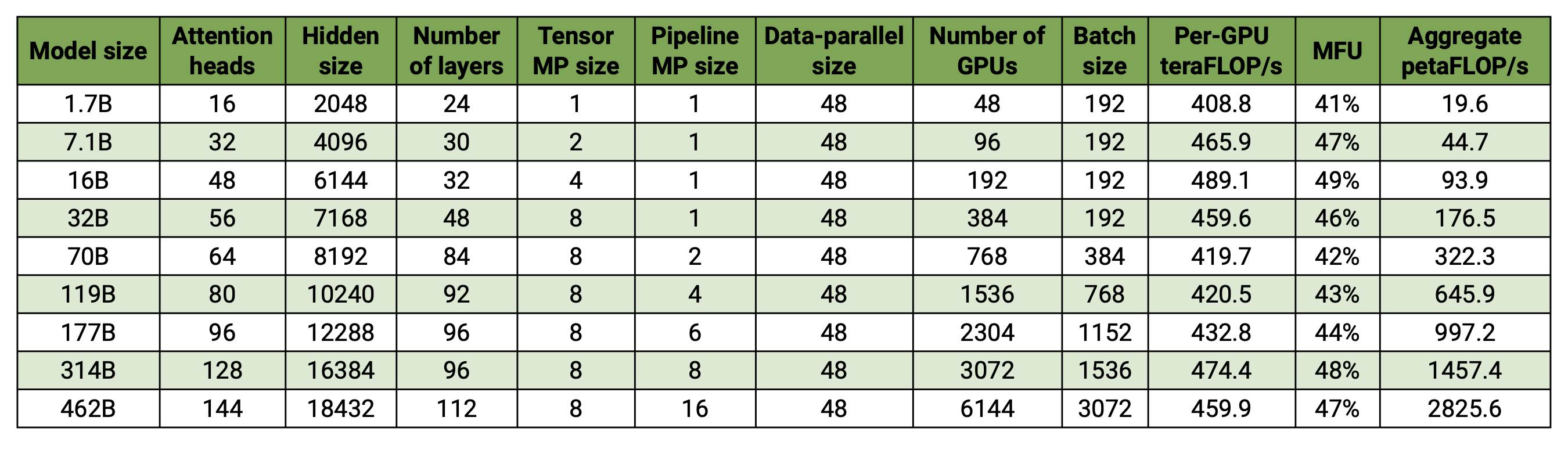
Unsere schwach skalierten Ergebnisse zeigen eine superlineare Skalierung (MFU steigt von 41 % für das kleinste betrachtete Modell auf 47–48 % für die größten Modelle); Dies liegt daran, dass größere GEMMs eine höhere Rechenintensität aufweisen und daher effizienter auszuführen sind.
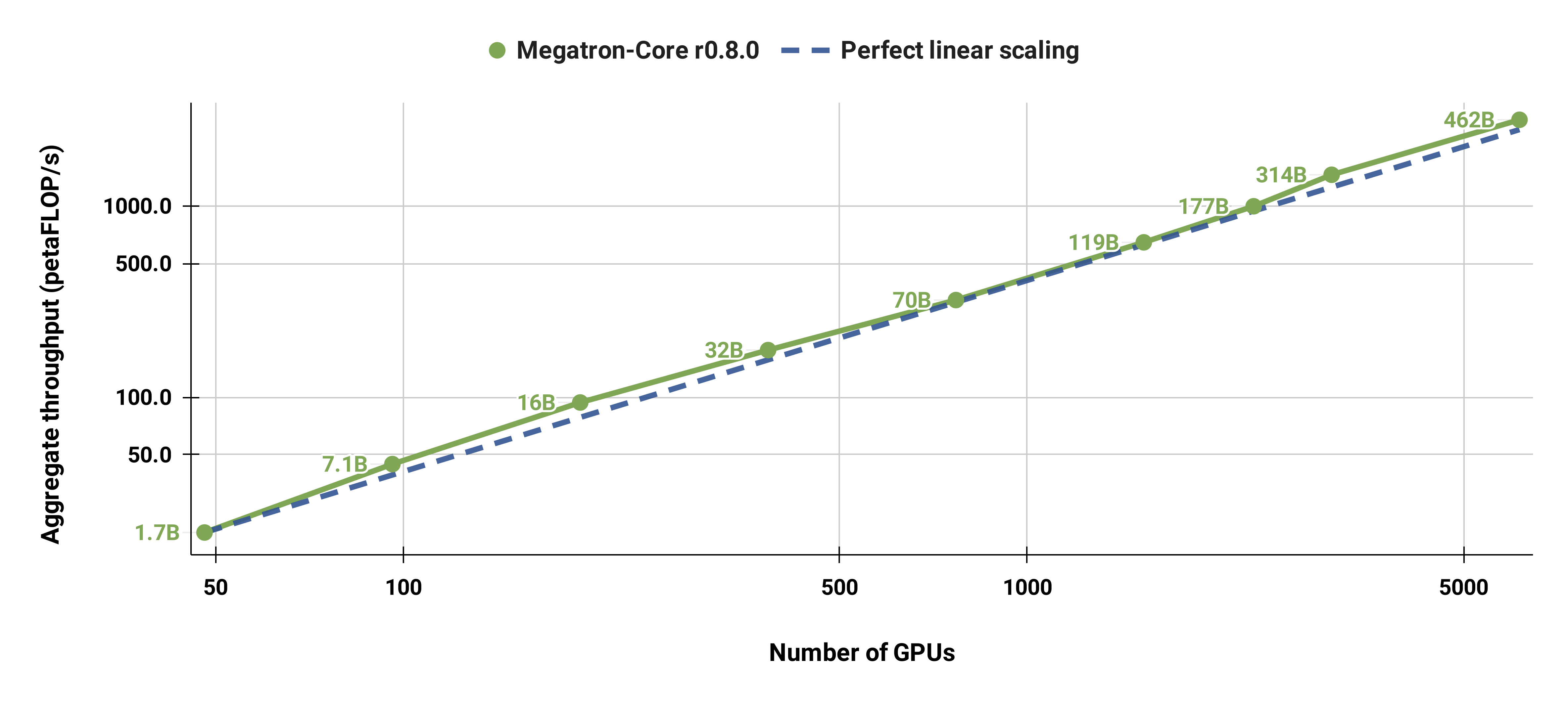
Wir haben auch das Standard-GPT-3-Modell (unsere Version verfügt aufgrund des größeren Vokabulars über etwas mehr als 175 Milliarden Parameter) stark von 96 H100-GPUs auf 4608 GPUs skaliert und dabei durchgehend die gleiche Stapelgröße von 1152 Sequenzen verwendet. Die Kommunikation wird in größerem Maßstab stärker exponiert, was zu einer Reduzierung der MFU von 47 % auf 42 % führt.
Wir empfehlen dringend, die neueste Version des PyTorch-Containers von NGC mit DGX-Knoten zu verwenden. Wenn Sie dies aus irgendeinem Grund nicht verwenden können, verwenden Sie die neuesten Versionen von Pytorch, Cuda, NCCL und NVIDIA APEX. Für die Datenvorverarbeitung ist NLTK erforderlich, dies ist jedoch nicht für Schulungen, Auswertungen oder nachgelagerte Aufgaben erforderlich.
Mit den folgenden Docker-Befehlen können Sie eine Instanz des PyTorch-Containers starten und Megatron, Ihren Datensatz und Prüfpunkte bereitstellen:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
Wir haben vorab trainierte BERT-345M- und GPT-345M-Kontrollpunkte zur Evaluierung oder Feinabstimmung nachgelagerter Aufgaben bereitgestellt. Um auf diese Prüfpunkte zuzugreifen, registrieren Sie sich zunächst für die NVIDIA GPU Cloud (NGC) Registry CLI und richten Sie sie ein. Weitere Dokumentation zum Herunterladen von Modellen finden Sie in der NGC-Dokumentation.
Alternativ können Sie die Checkpoints auch direkt herunterladen:
BERT-345M-uncased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
Zur Ausführung der Modelle sind Vokabeldateien erforderlich. Die BERT WordPiece-Vokabeldatei kann aus den vorab trainierten BERT-Modellen von Google extrahiert werden: uncased, cased. Die GPT-Vokabeldatei und die Zusammenführungstabelle können direkt heruntergeladen werden.
Nach der Installation gibt es mehrere mögliche Arbeitsabläufe. Das umfassendste ist:
Die Schritte 1 und 2 können jedoch durch die Verwendung eines der oben genannten vortrainierten Modelle ersetzt werden.
Wir haben im examples mehrere Skripte für das Vortraining von BERT und GPT sowie Skripte für Zero-Shot- und fein abgestimmte Downstream-Aufgaben bereitgestellt, einschließlich MNLI-, RACE-, WikiText103- und LAMBADA-Auswertung. Es gibt auch ein Skript für die interaktive GPT-Textgenerierung.
Die Trainingsdaten erfordern eine Vorverarbeitung. Platzieren Sie Ihre Trainingsdaten zunächst in einem losen JSON-Format, wobei ein JSON ein Textbeispiel pro Zeile enthält. Zum Beispiel:
{"src": "www.nvidia.com", "text": "The quick brown fox", "type": "Eng", "id": "0", "title": "First Part"}
{"src": "Das Internet", "text": "jumps over the lazy dog", "type": "Eng", "id": "42", "title": "Second Part"}
Der Name des text des JSON kann mithilfe des Flags --json-key in preprocess_data.py geändert werden. Die anderen Metadaten sind optional und werden im Training nicht verwendet.
Der lose JSON wird dann für das Training in ein Binärformat verarbeitet. Um den JSON in das MMAP-Format zu konvertieren, verwenden Sie preprocess_data.py . Ein Beispielskript zum Vorbereiten von Daten für das BERT-Training ist:
python tools/preprocess_data.py
--input my-corpus.json
--output-prefix my-bert
--vocab-file bert-vocab.txt
--tokenizer-type BertWordPieceLowerCase
--split-sets
Die Ausgabe besteht aus zwei Dateien mit den Namen my-bert_text_sentence.bin und my-bert_text_sentence.idx . Der im späteren BERT-Training angegebene --data-path ist der vollständige Pfad und der neue Dateiname, jedoch ohne die Dateierweiterung.
Verwenden Sie für T5 die gleiche Vorverarbeitung wie BERT und benennen Sie sie möglicherweise um in:
--output-prefix my-t5
Für die GPT-Datenvorverarbeitung sind einige geringfügige Änderungen erforderlich, nämlich das Hinzufügen einer Zusammenführungstabelle, eines Dokumentende-Tokens, das Entfernen der Satzaufteilung und eine Änderung des Tokenizer-Typs:
python tools/preprocess_data.py
--input my-corpus.json
--output-prefix my-gpt2
--vocab-file gpt2-vocab.json
--tokenizer-type GPT2BPETokenizer
--merge-file gpt2-merges.txt
--append-eod
Hier heißen die Ausgabedateien my-gpt2_text_document.bin und my-gpt2_text_document.idx . Verwenden Sie wie zuvor im GPT-Training den längeren Namen ohne die Erweiterung als --data-path .
Weitere Befehlszeilenargumente sind in der Quelldatei preprocess_data.py beschrieben.
Das Skript examples/bert/train_bert_340m_distributed.sh führt das BERT-Vortraining für einzelne GPU-345M-Parameter aus. Das Debuggen ist die Hauptanwendung für das Training mit einer einzelnen GPU, da die Codebasis und die Befehlszeilenargumente für stark verteiltes Training optimiert sind. Die meisten Argumente sind ziemlich selbsterklärend. Standardmäßig nimmt die Lernrate linear über die Trainingsiterationen ab, beginnend bei --lr bis zu einem Minimum, das durch --min-lr über --lr-decay-iters Iterationen festgelegt wird. Der Anteil der zum Aufwärmen verwendeten Trainingsiterationen wird durch --lr-warmup-fraction festgelegt. Obwohl es sich hierbei um ein einzelnes GPU-Training handelt, handelt es sich bei der durch --micro-batch-size angegebenen Stapelgröße um eine einzelne Vorwärts-Rückwärts-Pfad-Stapelgröße und der Code führt Gradientenakkumulationsschritte aus, bis er global-batch-size erreicht, die der Stapelgröße entspricht pro Iteration. Die Daten werden in einem Verhältnis von 949:50:1 für Trainings-/Validierungs-/Testsätze aufgeteilt (Standard ist 969:30:1). Diese Partitionierung erfolgt im laufenden Betrieb, ist jedoch über alle Läufe hinweg konsistent mit demselben zufälligen Startwert (standardmäßig 1234 oder manuell mit --seed angegeben). Wir verwenden train-iters als angeforderte Trainingsiterationen. Alternativ kann man --train-samples angeben, was die Gesamtzahl der zu trainierenden Samples angibt. Wenn diese Option vorhanden ist, muss anstelle von --lr-decay-iters die Bereitstellung --lr-decay-samples erfolgen.
Die Optionen für Protokollierung, Prüfpunktspeicherung und Auswertungsintervall werden angegeben. Beachten Sie, dass der --data-path jetzt das zusätzliche Suffix _text_sentence enthält, das bei der Vorverarbeitung hinzugefügt wurde, jedoch nicht die Dateierweiterungen.
Weitere Befehlszeilenargumente sind in der Quelldatei arguments.py beschrieben.
Um train_bert_340m_distributed.sh auszuführen, nehmen Sie alle gewünschten Änderungen vor, einschließlich der Festlegung der Umgebungsvariablen für CHECKPOINT_PATH , VOCAB_FILE und DATA_PATH . Stellen Sie sicher, dass diese Variablen auf ihre Pfade im Container festgelegt sind. Starten Sie dann den Container mit Megatron und den erforderlichen Pfaden (wie im Setup erläutert) und führen Sie das Beispielskript aus.
Das Skript examples/gpt3/train_gpt3_175b_distributed.sh führt das GPT-Vortraining für einzelne GPU-345M-Parameter aus. Wie oben erwähnt, ist das Training mit einer einzelnen GPU in erster Linie für Debugging-Zwecke gedacht, da der Code für verteiltes Training optimiert ist.
Es folgt weitgehend dem gleichen Format wie das vorherige BERT-Skript mit einigen bemerkenswerten Unterschieden: Das verwendete Tokenisierungsschema ist BPE (das eine Zusammenführungstabelle und eine json -Vokabulardatei erfordert) anstelle von WordPiece, die Modellarchitektur ermöglicht längere Sequenzen (beachten Sie, dass die Die Einbettung der maximalen Position muss größer oder gleich der maximalen Sequenzlänge sein) und der --lr-decay-style wurde auf Kosinuszerfall eingestellt. Beachten Sie, dass der --data-path jetzt das zusätzliche Suffix _text_document enthält, das bei der Vorverarbeitung hinzugefügt wurde, jedoch nicht die Dateierweiterungen.
Weitere Befehlszeilenargumente sind in der Quelldatei arguments.py beschrieben.
train_gpt3_175b_distributed.sh kann auf die gleiche Weise wie für BERT beschrieben gestartet werden. Legen Sie die Umgebungsvariablen fest und nehmen Sie weitere Änderungen vor, starten Sie den Container mit den entsprechenden Mounts und führen Sie das Skript aus. Weitere Details finden Sie in examples/gpt3/README.md
Das Skript examples/t5/train_t5_220m_distributed.sh “ ist BERT und GPT sehr ähnlich und führt ein einzelnes GPU-„Basis“-T5-Vortraining (~220 MB Parameter) aus. Der Hauptunterschied zu BERT und GPT besteht in der Hinzufügung der folgenden Argumente zur Anpassung an die T5-Architektur:
--kv-channels legt die innere Dimension der „Schlüssel“- und „Wert“-Matrizen aller Aufmerksamkeitsmechanismen im Modell fest. Für BERT und GPT ist dies standardmäßig die versteckte Größe geteilt durch die Anzahl der Aufmerksamkeitsköpfe, kann aber für T5 konfiguriert werden.
--ffn-hidden-size legt die verborgene Größe in den Feed-Forward-Netzwerken innerhalb einer Transformatorschicht fest. Für BERT und GPT ist dies standardmäßig das Vierfache der versteckten Größe des Transformators, kann aber für T5 konfiguriert werden.
--encoder-seq-length und --decoder-seq-length legen die Sequenzlänge für Encoder und Decoder getrennt fest.
Alle anderen Argumente bleiben wie beim BERT- und GPT-Vortraining bestehen. Führen Sie dieses Beispiel mit denselben Schritten aus, die oben für die anderen Skripts beschrieben wurden.
Weitere Details finden Sie in examples/t5/README.md
Die pretrain_{bert,gpt,t5}_distributed.sh Skripte verwenden den PyTorch Distributed Launcher für verteiltes Training. Daher kann ein Training mit mehreren Knoten durch die richtige Einstellung von Umgebungsvariablen erreicht werden. Weitere Beschreibungen dieser Umgebungsvariablen finden Sie in der offiziellen PyTorch-Dokumentation. Standardmäßig wird beim Training mit mehreren Knoten das verteilte Nccl-Backend verwendet. Ein einfacher Satz zusätzlicher Argumente und die Verwendung des verteilten PyTorch-Moduls mit dem elastischen torchrun -Launcher (entspricht python -m torch.distributed.run ) sind die einzigen zusätzlichen Anforderungen für die Einführung verteilten Trainings. Weitere Informationen finden Sie in pretrain_{bert,gpt,t5}_distributed.sh .
Wir verwenden zwei Arten von Parallelität: Daten- und Modellparallelität. Unsere Implementierung der Datenparallelität erfolgt in megatron/core/distributed und unterstützt die Überlappung der Gradientenreduzierung mit dem Rückwärtsdurchlauf, wenn die Befehlszeilenoption --overlap-grad-reduce verwendet wird.
Zweitens haben wir einen einfachen und effizienten zweidimensionalen modellparallelen Ansatz entwickelt. Um die erste Dimension, die Tensormodellparallelität (Aufteilung der Ausführung eines einzelnen Transformatormoduls auf mehrere GPUs, siehe Abschnitt 3 unseres Artikels), zu verwenden, fügen Sie das Flag --tensor-model-parallel-size hinzu, um die Anzahl der GPUs anzugeben, unter denen gearbeitet werden soll Teilen Sie das Modell zusammen mit den Argumenten auf, die wie oben erwähnt an den verteilten Launcher übergeben werden. Um die zweite Dimension, die Sequenzparallelität, zu verwenden, geben Sie --sequence-parallel an. Dies erfordert auch die Aktivierung der Tensormodellparallelität, da sie sich auf dieselben GPUs aufteilt (weitere Einzelheiten finden Sie in Abschnitt 4.2.2 unseres Dokuments).
Um die Parallelität des Pipeline-Modells zu nutzen (Sharding der Transformatormodule in Stufen mit einer gleichen Anzahl von Transformatormodulen auf jeder Stufe und anschließende Pipeline-Ausführung durch Aufteilen des Stapels in kleinere Mikrobatches, siehe Abschnitt 2.2 unseres Artikels), verwenden Sie das --pipeline-model-parallel-size Flag, um die Anzahl der Stufen anzugeben, in die das Modell aufgeteilt werden soll (z. B. würde die Aufteilung eines Modells mit 24 Transformatorschichten auf 4 Stufen bedeuten, dass jede Stufe jeweils 6 Transformatorschichten erhält).
Wir haben Beispiele für die Verwendung dieser beiden unterschiedlichen Formen der Modellparallelität in den Beispielskripten, die auf distributed_with_mp.sh enden.
Abgesehen von diesen geringfügigen Änderungen ist das verteilte Training identisch mit dem Training auf einer einzelnen GPU.
Der verschachtelte Pipeline-Zeitplan (weitere Details in Abschnitt 2.2.2 unseres Artikels) kann mit dem Argument --num-layers-per-virtual-pipeline-stage aktiviert werden, das die Anzahl der Transformatorschichten in einer virtuellen Stufe steuert (standardmäßig). Mit dem nicht verschachtelten Zeitplan führt jede GPU eine einzelne virtuelle Stufe mit NUM_LAYERS / PIPELINE_MP_SIZE -Transformerschichten aus. Die Gesamtzahl der Schichten im Transformatormodell sollte durch diesen Argumentwert teilbar sein. Darüber hinaus sollte die Anzahl der Mikrobatches in der Pipeline (berechnet als GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) bei Verwendung dieses Zeitplans durch PIPELINE_MP_SIZE teilbar sein (diese Bedingung wird in einer Behauptung im Code überprüft). Der verschachtelte Zeitplan wird für Pipelines mit zwei Stufen ( PIPELINE_MP_SIZE=2 ) nicht unterstützt.
Um die GPU-Speichernutzung beim Training eines großen Modells zu reduzieren, unterstützen wir verschiedene Formen des Aktivierungs-Checkpointings und der Neuberechnung. Anstatt alle Aktivierungen im Speicher zu speichern, um sie beim Backprop zu verwenden, wie es traditionell bei Deep-Learning-Modellen der Fall war, werden nur Aktivierungen an bestimmten „Kontrollpunkten“ im Modell im Speicher beibehalten (oder gespeichert), und die anderen Aktivierungen werden neu berechnet -the-fly, wenn es für den Backprop benötigt wird. Beachten Sie, dass sich diese Art des Checkpointings, das Aktivierungs -Checkpointing, stark vom Checkpointing von Modellparametern und Optimiererstatus unterscheidet, das an anderer Stelle erwähnt wird.
Wir unterstützen zwei Ebenen der Neuberechnungsgranularität: selective und full . Die selektive Neuberechnung ist die Standardeinstellung und wird in fast allen Fällen empfohlen. Dieser Modus behält die Aktivierungen im Speicher, die weniger Speicherplatz beanspruchen und deren Neuberechnung teurer ist, und berechnet die Aktivierungen neu, die mehr Speicherplatz beanspruchen, deren Neuberechnung jedoch relativ kostengünstig ist. Weitere Informationen finden Sie in unserem Papier. Sie sollten feststellen, dass dieser Modus die Leistung maximiert und gleichzeitig den zum Speichern von Aktivierungen erforderlichen Speicher minimiert. Um die Neuberechnung der selektiven Aktivierung zu aktivieren, verwenden Sie einfach --recompute-activations .
In Fällen, in denen der Speicher sehr begrenzt ist, speichert die full Neuberechnung nur die Eingaben in eine Transformatorschicht oder eine Gruppe oder einen Block von Transformatorschichten und berechnet alles andere neu. Um die Neuberechnung der vollständigen Aktivierung zu aktivieren, verwenden Sie --recompute-granularity full . Bei Verwendung der Neuberechnung der full Aktivierung gibt es zwei Methoden: uniform und block , ausgewählt mit dem Argument --recompute-method .
Die uniform Methode unterteilt die Transformatorschichten gleichmäßig in Schichtgruppen (jede Gruppe hat die Größe --recompute-num-layers ) und speichert die Eingabeaktivierungen jeder Gruppe im Speicher. Die Basisgruppengröße beträgt 1 und in diesem Fall wird die Eingabeaktivierung jeder Transformatorschicht gespeichert. Wenn der GPU-Speicher nicht ausreicht, verringert die Erhöhung der Anzahl der Schichten pro Gruppe die Speichernutzung, sodass ein größeres Modell trainiert werden kann. Wenn beispielsweise --recompute-num-layers auf 4 gesetzt ist, wird nur die Eingabeaktivierung jeder Gruppe von 4 Transformatorschichten gespeichert.
Die block berechnet die Eingabeaktivierungen einer bestimmten Anzahl (angegeben durch --recompute-num-layers ) einzelner Transformatorschichten pro Pipeline-Stufe neu und speichert die Eingabeaktivierungen der verbleibenden Schichten in der Pipeline-Stufe. Die Reduzierung --recompute-num-layers führt dazu, dass die Eingabeaktivierungen auf mehr Transformer-Ebenen gespeichert werden, was die im Backprop erforderliche Neuberechnung der Aktivierung reduziert und so die Trainingsleistung verbessert und gleichzeitig die Speichernutzung erhöht. Wenn wir beispielsweise 5 Schichten für die Neuberechnung von 8 Schichten pro Pipeline-Stufe angeben, werden im Backprop-Schritt nur die Eingabeaktivierungen der ersten 5 Transformatorschichten neu berechnet, während die Eingabeaktivierungen für die letzten 3 Schichten gespeichert werden. --recompute-num-layers kann schrittweise erhöht werden, bis der erforderliche Speicherplatz gerade klein genug ist, um in den verfügbaren Speicher zu passen, wodurch sowohl der Speicher maximal genutzt als auch die Leistung maximiert wird.
Verwendung: --use-distributed-optimizer . Kompatibel mit allen Modellen und Datentypen.
Der verteilte Optimierer ist eine Technik zur Speichereinsparung, bei der der Optimiererstatus gleichmäßig über die parallelen Datenränge verteilt wird (im Gegensatz zur herkömmlichen Methode der Replikation des Optimiererstatus über parallele Datenränge). Wie in ZeRO: Memory Optimizations Toward Training Trillion Parameter Models beschrieben, verteilt unsere Implementierung alle Optimiererzustände, die sich nicht mit dem Modellzustand überschneiden. Wenn beispielsweise fp16-Modellparameter verwendet werden, verwaltet der verteilte Optimierer seine eigene separate Kopie der fp32-Hauptparameter und -Abschlüsse, die über DP-Ränge verteilt sind. Bei der Verwendung von bf16-Modellparametern sind jedoch die fp32-Hauptparameter des verteilten Optimierers dieselben wie die fp32-Werte des Modells, sodass die Parameter in diesem Fall nicht verteilt werden (obwohl die fp32-Hauptparameter weiterhin verteilt sind, da sie vom bf16 getrennt sind). Modellparameter).
Die theoretischen Speichereinsparungen variieren je nach der Kombination aus Parametertyp und Grad-Typ des Modells. In unserer Implementierung beträgt die theoretische Anzahl von Bytes pro Parameter (wobei „d“ die parallele Datengröße ist):
| Nicht verteiltes Optimum | Verteiltes Optimum | |
|---|---|---|
| fp16 param, fp16 absolventen | 20 | 4 + 16/T |
| bf16 param, fp32 absolventen | 18 | 6 + 12/T |
| fp32-Parameter, fp32-Absolventen | 16 | 8 + 8/d |
Wie bei der regulären Datenparallelität kann die Überlappung der Gradientenreduzierung (in diesem Fall eine Reduzierung-Streuung) mit dem Rückwärtsdurchlauf mithilfe des Flags --overlap-grad-reduce erleichtert werden. Darüber hinaus kann die Überlappung des Parameters all-gather mit dem Vorwärtsdurchlauf überlappt werden, indem --overlap-param-gather verwendet wird.
Verwendung: --use-flash-attn . Stützkopfmaße höchstens 128.
FlashAttention ist ein schneller und speichereffizienter Algorithmus zur Berechnung der genauen Aufmerksamkeit. Es beschleunigt das Modelltraining und reduziert den Speicherbedarf.
So installieren Sie FlashAttention:
pip install flash-attn In examples/gpt3/train_gpt3_175b_distributed.sh haben wir ein Beispiel dafür bereitgestellt, wie Megatron konfiguriert wird, um GPT-3 mit 175 Milliarden Parametern auf 1024 GPUs zu trainieren. Das Skript ist für Slurm mit dem Pyxis-Plugin konzipiert, kann aber problemlos an jeden anderen Scheduler übernommen werden. Es verwendet 8-Wege-Tensor-Parallelität und 16-Wege-Pipeline-Parallelität. Mit den Optionen global-batch-size 1536 und rampup-batch-size 16 16 5859375 beginnt das Training mit der globalen Batch-Größe 16 und erhöht die globale Batch-Größe linear auf 1536 über 5.859.375 Proben mit inkrementellen Schritten 16. Der Trainingsdatensatz kann einer von beiden sein ein einzelner Satz oder mehrere Datensätze kombiniert mit einem Satz von Gewichten.
Bei einer vollständigen globalen Batchgröße von 1536 auf 1024 A100-GPUs dauert jede Iteration etwa 32 Sekunden, was zu 138 TeraFLOPs pro GPU führt, was 44 % der theoretischen Spitzen-FLOPs entspricht.
Retro (Borgeaud et al., 2022) ist ein autoregressives Nur-Decoder-Sprachmodell (LM), das mit Retrieval-Augmentation vorab trainiert wurde. Retro verfügt über praktische Skalierbarkeit, um ein groß angelegtes Vortraining von Grund auf durch den Abruf von Billionen von Token zu unterstützen. Vortraining mit Abruf bietet einen effizienteren Speichermechanismus für Faktenwissen im Vergleich zur impliziten Speicherung von Faktenwissen innerhalb der Netzwerkparameter, wodurch die Modellparameter erheblich reduziert werden und gleichzeitig eine geringere Verwirrung als bei Standard-GPT erzielt wird. Retro bietet außerdem die Flexibilität, das in LMs gespeicherte Wissen zu aktualisieren (Wang et al., 2023a), indem die Abrufdatenbank aktualisiert wird, ohne die LMs erneut zu trainieren.
InstructRetro (Wang et al., 2023b) vergrößert die Größe von Retro weiter auf 48B und bietet den größten vorab trainierten LLM mit Retrieval (Stand Dezember 2023). Das erhaltene Basismodell Retro 48B übertrifft das GPT-Gegenstück in puncto Ratlosigkeit bei weitem. Mit der Befehlsoptimierung auf Retro zeigt InstructRetro bei Downstream-Aufgaben in der Zero-Shot-Einstellung eine deutliche Verbesserung gegenüber dem befehlsoptimierten GPT. Konkret beträgt die durchschnittliche Verbesserung von InstructRetro 7 % gegenüber seinem GPT-Pendant bei 8 kurzen QS-Aufgaben und 10 % gegenüber GPT bei 4 anspruchsvollen langen QS-Aufgaben. Wir finden auch, dass man den Encoder aus der InstructRetro-Architektur entfernen und das InstructRetro-Decoder-Backbone direkt als GPT verwenden und dabei vergleichbare Ergebnisse erzielen kann.
In diesem Repo stellen wir eine End-to-End-Reproduktionsanleitung zur Implementierung von Retro und InstructRetro bereit
Eine detaillierte Übersicht finden Sie unter tools/retro/README.md.
Weitere Informationen finden Sie unter „examples/mamba“.
Wir stellen mehrere Befehlszeilenargumente bereit, die in den unten aufgeführten Skripten detailliert beschrieben werden, um verschiedene Zero-Shot- und fein abgestimmte Downstream-Aufgaben zu bewältigen. Sie können Ihr Modell jedoch nach Bedarf auch von einem vorab trainierten Kontrollpunkt auf anderen Korpora aus verfeinern. Fügen Sie dazu einfach das Flag --finetune hinzu und passen Sie die Eingabedateien und Trainingsparameter im ursprünglichen Trainingsskript an. Der Iterationszähler wird auf Null zurückgesetzt und der Optimierer und der interne Status werden neu initialisiert. Wenn die Feinabstimmung aus irgendeinem Grund unterbrochen wird, entfernen Sie unbedingt das Flag --finetune , bevor Sie fortfahren, da das Training sonst erneut von vorne beginnt.
Da die Auswertung wesentlich weniger Speicher erfordert als das Training, kann es vorteilhaft sein, ein parallel trainiertes Modell zusammenzuführen, um es in nachgelagerten Aufgaben auf weniger GPUs zu verwenden. Das folgende Skript erreicht dies. Dieses Beispiel liest ein GPT-Modell mit 4-Wege-Tensor und 4-Wege-Pipeline-Modellparallelität ein und schreibt ein Modell mit 2-Wege-Tensor und 2-Wege-Pipeline-Modellparallelität aus.
Python tools/checkpoint/convert.py
--model-type GPT
--load-dir checkpoints/gpt3_tp4_pp4
--save-dir checkpoints/gpt3_tp2_pp2
--target-tensor-parallel-size 2
--target-pipeline-parallel-size 2
Im Folgenden werden mehrere nachgelagerte Aufgaben sowohl für GPT- als auch für BERT-Modelle beschrieben. Sie können im verteilten und modellparallelen Modus mit denselben Änderungen ausgeführt werden, die in den Trainingsskripten verwendet werden.
Wir haben einen einfachen REST-Server zur Textgenerierung in tools/run_text_generation_server.py eingebunden. Sie führen es ähnlich aus, als würden Sie einen vorab trainierten Job starten, indem Sie einen geeigneten vorab trainierten Prüfpunkt angeben. Es gibt auch einige optionale Parameter: temperature , top-k und top-p . Weitere Informationen finden Sie unter --help oder in der Quelldatei. Ein Beispiel für die Ausführung des Servers finden Sie unter „examples/inference/run_text_generation_server_345M.sh“.
Sobald der Server läuft, können Sie ihn mit tools/text_generation_cli.py abfragen. Es benötigt ein Argument, nämlich den Host, auf dem der Server läuft.
tools/text_generation_cli.py localhost:5000
Sie können auch CURL oder andere Tools verwenden, um den Server direkt abzufragen:
curl 'http://localhost:5000/api' -X 'PUT' -H 'Content-Type: application/json; charset=UTF-8' -d '{"prompts":["Hello world"], "tokens_to_generate":1}'
Weitere API-Optionen finden Sie unter megatron/inference/text_generation_server.py.
Wir fügen ein Beispiel in examples/academic_paper_scripts/detxoify_lm/ ein, um Sprachmodelle zu entgiften, indem wir die generative Kraft von Sprachmodellen nutzen.
Unter „examples/academic_paper_scripts/detxoify_lm/README.md“ finden Sie Schritt-für-Schritt-Anleitungen zur Durchführung domänenadaptiver Schulungen und zur Entgiftung von LM mithilfe eines selbst generierten Korpus.
Wir fügen Beispielskripte für die GPT-Analyse, die WikiText-Analyse und die LAMBADA-Lückentextgenauigkeit hinzu.
Für einen gleichmäßigen Vergleich mit früheren Arbeiten bewerten wir die Ratlosigkeit anhand des WikiText-103-Testdatensatzes auf Wortebene und berechnen die Ratlosigkeit angesichts der Änderung der Token bei Verwendung unseres Unterwort-Tokenizers entsprechend.
Wir verwenden den folgenden Befehl, um die WikiText-103-Auswertung für ein 345M-Parametermodell auszuführen.
TASK="WIKITEXT103"
VALID_DATA=<Wikitext-Pfad>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=checkpoints/gpt2_345m
COMMON_TASK_ARGS="--num-layers 24
--hidden-size 1024
--num-attention-heads 16
--seq-length 1024
--max-position-embeddings 1024
--fp16
--vocab-file $VOCAB_FILE"
Python-Aufgaben/main.py
--task $TASK
$COMMON_TASK_ARGS
--valid-data $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--merge-file $MERGE_FILE
--load $CHECKPOINT_PATH
--micro-batch-size 8
--log-interval 10
--no-load-optim
--no-load-rng
Zur Berechnung der LAMBADA-Lückentextgenauigkeit (die Genauigkeit der Vorhersage des letzten Tokens angesichts der vorhergehenden Tokens) verwenden wir eine detokenisierte, verarbeitete Version des LAMBADA-Datensatzes.
Wir verwenden den folgenden Befehl, um die LAMBADA-Auswertung für ein 345M-Parametermodell auszuführen. Beachten Sie, dass das Flag --strict-lambada verwendet werden sollte, um den Abgleich ganzer Wörter zu erfordern. Stellen Sie sicher, dass lambada Teil des Dateipfads ist.
TASK="LAMBADA"
VALID_DATA=<Lambada-Pfad>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=checkpoints/gpt2_345m
COMMON_TASK_ARGS=<identisch mit denen in WikiText Perplexity Evaluation oben>
Python-Aufgaben/main.py
--task $TASK
$COMMON_TASK_ARGS
--valid-data $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--strict-lambada
--merge-file $MERGE_FILE
--load $CHECKPOINT_PATH
--micro-batch-size 8
--log-interval 10
--no-load-optim
--no-load-rng
Weitere Kommandozeilenargumente sind in der Quelldatei main.py beschrieben
Das folgende Skript optimiert das BERT-Modell für die Auswertung des RACE-Datensatzes. Die Verzeichnisse TRAIN_DATA und VALID_DATA enthalten den RACE-Datensatz als separate .txt Dateien. Beachten Sie, dass bei RACE die Batchgröße die Anzahl der auszuwertenden RACE-Abfragen ist. Da jede RACE-Abfrage über vier Stichproben verfügt, beträgt die durch das Modell weitergeleitete effektive Stapelgröße das Vierfache der in der Befehlszeile angegebenen Stapelgröße.
TRAIN_DATA="data/RACE/train/middle"
VALID_DATA="data/RACE/dev/middle
data/RACE/dev/high"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=checkpoints/bert_345m
CHECKPOINT_PATH=checkpoints/bert_345m_race
COMMON_TASK_ARGS="--num-layers 24
--hidden-size 1024
--num-attention-heads 16
--seq-length 512
--max-position-embeddings 512
--fp16
--vocab-file $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--train-data $TRAIN_DATA
--valid-data $VALID_DATA
--pretrained-checkpoint $PRETRAINED_CHECKPOINT
--save-interval 10000
--save $CHECKPOINT_PATH
--log-interval 100
--eval-interval 1000
--eval-iters 10
--weight-decay 1.0e-1"
Python-Aufgaben/main.py
--task RACE
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--epochs 3
--micro-batch-size 4
--lr 1.0e-5
--lr-warmup-fraktion 0,06
Das folgende Skript optimiert das BERT-Modell für die Auswertung mit dem MultiNLI-Satzpaarkorpus. Da die Matching-Aufgaben recht ähnlich sind, kann das Skript schnell angepasst werden, um auch mit dem Quora Question Pairs (QQP)-Datensatz zu arbeiten.
Train_data = "data/klue_data/mnli/train.tsv"
Valid_data = "data/klue_data/mnli/dev_matched.tsv
Data/GLUE_DATA/MNLI/DEV_MISMATTED.TSV "
Voraber_checkpoint = Checkpoints/Bert_345m
Vocab_file = Bert-vocab.txt
Checkpoint_path = checkpoints/bert_345m_mnli
Common_task_args = <Gleich wie in der obigen Rassenbewertung>
Common_task_args_ext = <Gleich wie in der obigen Rassenbewertung>
Python -Aufgaben/main.py
-Dasking mnli
$ Common_task_args
$ Common_task_args_ext
-Tokenizer-Typ BertwordpiecelowerCase
--epochs 5
-Micro-Batch-Größe 8
--LR 5.0E-5
--LR-WARMUP-FRAKTION 0.065
Die LLAMA-2-Modelsfamilie ist ein Open-Source-Satz von vorbereiteten und feindlichen Modellen (für CHAT), die in einer Vielzahl von Benchmarks starke Ergebnisse erzielt haben. Zum Zeitpunkt der Veröffentlichung erzielten LLAMA-2-Modelle zu den besten Ergebnissen für Open-Source-Modelle und waren mit dem GPT-3.5-Modell mit geschlossenem Source konkurrenzfähig (siehe https://arxiv.org/pdf/2307.09288.pdf).
Die Lama-2-Checkpoints können zur Inferenz und Finetuning in Megatron geladen werden. Siehe Dokumentation hier.
Megatron-Core (MCORE) GPTModel Familie unterstützt erweiterte Quantisierungsalgorithmen und Hochleistungs-Inferenz durch Tensorrt-Llm.
Siehe Megatron -Modelloptimierung und Bereitstellung für Beispiele von llama2 und nemotron3 .
Wir hosten keine Datensätze für GPT- oder Bert -Training, deten wir jedoch ihre Sammlung so aus, dass unsere Ergebnisse reproduziert werden können.
Wir empfehlen dem von Google Research angegebenen Wikipedia-Datenextraktionsprozess: "Die empfohlene Vorverarbeitung besteht darin, den neuesten Dump herunterzuladen, den Text mit Wikiextractor.py zu extrahieren und dann die erforderliche Reinigung anzuwenden, um ihn in einfache Text umzuwandeln."
Wir empfehlen, das Argument --json bei der Verwendung von Wikiextractor zu verwenden, das die Wikipedia -Daten in das Loose JSON -Format (ein JSON -Objekt pro Zeile) einleitet, wodurch es auf dem Dateisystem verwaltbarer und auch von unserer Codebasis leicht verbraucht werden kann. Wir empfehlen, diesen JSON -Datensatz mit der NLTK -Interpunktionsstandardisierung weiterzubereiten. Verwenden Sie für das Bert-Training das Flag --split-sentences -Flag zum preprocess_data.py wie oben beschrieben, um Satzpausen in den produzierten Index aufzunehmen. Wenn Sie Wikipedia-Daten für das GPT-Training verwenden möchten, sollten Sie es immer noch mit NLTK/SPACY/FTFY reinigen, aber nicht das Flag --split-sentences Flag verwenden.
Wir verwenden die öffentlich verfügbare OpenWebtext -Bibliothek von JCPeterson und Eukaryote31s Arbeiten zum Herunterladen von URLs. Anschließend filtern, reinigen und deduplizieren wir alle heruntergeladenen Inhalte gemäß der in unserem OpenWebtext -Verzeichnis beschriebenen Prozeduren. Für Reddit -URLs, die bis Oktober 2018 den Inhalten entsprechen, kamen wir mit ca. 37 GB Inhalt an.
Megatron -Training kann bitweise reproduzierbar sein; So aktivieren Sie diesen Modus --deterministic-mode . Dies bedeutet, dass dieselbe Trainingskonfiguration, die zweimal in derselben HW- und SW -Umgebung ausgeführt wird, identische Modellkontrollpunkte, Verluste und Genauigkeitsmetrikwerte erzeugen (Iterationszeitmetriken können variieren).
Derzeit gibt es drei bekannte Megatron -Optimierungen, die die Reproduzierbarkeit brechen und gleichzeitig fast identische Trainingsläufe erzeugen:
NCCL_ALGO angegeben), ist wichtig. Wir haben Folgendes getestet: ^NVLS , Tree , Ring , CollnetDirect , CollnetChain . Der Code gibt die Verwendung von ^NVLS zu, wodurch NCCL die Auswahl von Nicht-NVLS-Algorithmen ermöglicht. Seine Wahl scheint stabil zu sein.--use-flash-attn .NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 festlegen.Darüber hinaus wurde Determinisim nur in NGC -Pytorch -Behältern bis und neuer als 23,12 verifiziert. Wenn Sie unter anderen Umständen den Nichtdeterminismus im Megatron -Training beobachten, öffnen Sie bitte ein Problem.
Im Folgenden finden Sie einige Projekte, bei denen wir Megatron direkt verwendet haben:


