Von Buqian Zheng(buqianz) und Yongkang Huang(yongkan1)
Poster
Wir haben Corgy implementiert, ein Deep-Learning-Framework in Swift und Metal. Corgy kann sowohl in macOS- als auch in iOS-Anwendungen eingebettet werden und zum einfachen Aufbau trainierter neuronaler Netze und deren Auswertung verwendet werden. Wir haben auf verschiedenen Geräten mit unterschiedlichen GPUs eine mehr als 60-fache Geschwindigkeitssteigerung erreicht.

Das Metal 2-Framework ist eine von Apple bereitgestellte Schnittstelle, die einen nahezu direkten Zugriff auf die Grafikverarbeitungseinheit (GPU) auf iPhone/iPad und Mac ermöglicht. Neben der Grafik enthält Metal 2 eine Reihe von Bibliotheken, die eine hervorragende Parallelisierungsunterstützung für die erforderlichen linearen Algebraoperationen und Signalverarbeitungsfunktionen bieten und auf verschiedenen Arten von Apple-Geräten ausgeführt werden können. Diese Bibliotheken ermöglichten es uns, gut implementierte GPU-beschleunigte Deep-Learning-Modelle auf iOS-Geräten zu erstellen, die auf dem trainierten Modell anderer Frameworks basieren. 1
Im Allgemeinen ist die Inferenzphase eines trainierten neuronalen Netzwerks sehr rechenintensiv, insbesondere für Modelle, die über eine beträchtlich große Anzahl von Schichten verfügen oder in den Szenarien angewendet werden, die zur Verarbeitung hochauflösender Bilder erforderlich sind. Es ist erwähnenswert, dass eine enorme Menge an Matrixberechnungen (z. B. Faltungsschicht) erforderlich ist, um parallelisierte Operationen zur Optimierung der Leistung anzuwenden.
Die erste Herausforderung, mit der wir konfrontiert waren, bestand darin, eine gute Abstraktion einer Anwendungsprogrammierschnittstelle zu entwerfen, die ausdrucksstark und einfach zu verwenden ist, eine geringe Lernkurve aufweist und für unsere Benutzer einfach zu verwenden ist.
Während des gesamten Entwicklungsprozesses haben wir unser Bestes gegeben, um die öffentliche API so einfach wie möglich zu halten und gleichzeitig über alle erforderlichen Eigenschaften zu verfügen, um alle erforderlichen Komponenten zu erstellen, indem wir den von Swift bereitgestellten funktionalen Programmiermechanismus nutzen. Wir haben auch unnötige Hardware-Abstraktionen von Metal bewusst ausgeblendet, um die Lernkurve zu vereinfachen.
Obwohl die trainierten Modelle der verschiedenen Netzwerke leicht im Internet erhältlich sind, erschwerte die Heterogenität zwischen ihnen, die durch die unterschiedliche Implementierung unter Verwendung verschiedener Arten von Tools verursacht wurde, die Arbeit, einen universellen Modellimporteur zu erstellen.
Einige der Berechnungen sind aufgrund ihrer Konzeption leicht zu verstehen, erfordern jedoch sorgfältige Überlegungen, wenn Sie durch Abstrahieren eine effektive Implementierung erstellen möchten. Faltung ist ein repräsentatives Beispiel.
Die intrinsische Eigenschaft der Faltungsoperation hat keine gute Lokalität, die Vanilla-Implementierung ist schwer zu verstehen und bei komplizierten for-Schleifen ineffektiv. Außerdem müssen wir die von Metal 2 bereitgestellte Abstraktion berücksichtigen und eine bequeme Möglichkeit schaffen, notwendige Informationen und Datenstrukturen zwischen Host und Gerät auszutauschen, wobei wir die Datendarstellung und das Speicherlayout sorgfältig berücksichtigen.
Während der Entwicklungsphase achten wir gewissenhaft darauf, dass unser Code normal auf macOS und iOS läuft, ohne Kompromisse bei der Leistung auf beiden Plattformen einzugehen. Wir haben uns nach besten Kräften bemüht, die Codebibliothek so zu pflegen, dass sie auf beiden Plattformen kompiliert und ausgeführt werden kann. Wir sind darauf bedacht, den von den verschiedenen Zielen gemeinsam genutzten Code zu maximieren und den Code so weit wie möglich wiederzuverwenden.
Da eine vollständig implementierte Komponente der neuronalen Netzwerkschicht Unterstützung mit einer angemessenen Menge an Parametern bieten sollte, die die Komponente ausreichend nutzbar machen, ist die Komplexität der Komponenten tatsächlich recht beeindruckend. Beispielsweise sollte die Faltungsschicht die Parameter unterstützen, die Polsterung, Dilatationsschritt usw. umfassen, und alle sollten sorgfältig berücksichtigt werden, wenn die Parallelisierung durchgeführt wird, um eine angemessene Leistung zu erzielen. Wir haben einige einfache Netzwerke aufgebaut, um den Regressionstest durchzuführen. Testfälle werden in anderen Frameworks (hauptsächlich PyTorch und Keras) erstellt, um sicherzustellen, dass die gesamte Implementierung korrekt funktioniert.
Swift wurde erstmals im Juli 2010 entwickelt und 2014 veröffentlicht und als Open Source bereitgestellt. Obwohl seit der Veröffentlichung fast vier Jahre vergangen sind, ist das Fehlen einer wirkungsvollen Bibliothek immer noch ein nicht zu vernachlässigendes Problem. Irgendein Grund hat diese Situation verursacht, die dominierende Rolle von Apple und die schnelle iterative Natur von Swift könnten der Grund für dieses Phänomen sein. Einige Bibliotheken, die für uns von entscheidender Bedeutung sind, sind entweder nicht leistungsstark oder funktional genug für unsere Anforderungen oder werden von den einzelnen Entwicklern, die sie erfunden haben, nicht gut gepflegt. Wir haben ziemlich viel Zeit damit verbracht, eine gut funktionierende Tensorklasse Variable für unsere Anforderungen zu implementieren.
Dies ist auch ein weiterer Grund, der die Entwicklung eines universellen Modellparsers behindert, da die Datei- und String-Verarbeitungsfunktion nur über sehr begrenzte Möglichkeiten verfügt.
Darüber hinaus sind die Entwicklungs- und Debugging-Tools im Wesentlichen auf Xcode beschränkt, es gibt jedoch auch andere, allgemeinere Optionen. Für uns ist Xcode immer noch das De-facto-Standardtool für unsere Entwicklung.
Für die Leistungsoptimierung für mobile Geräte stellt Apple keine detaillierten Hardwarespezifikationen für seinen SoC bereit. Der Marketingname wird in den Medien häufig verwendet und es ist schwer abzuleiten, welche genauen Auswirkungen eine bestimmte Hardwarefunktion und die Feinabstimmung der Leistung auf die Implementierung haben .
Wir verwenden die Programmiersprache Swift, insbesondere Swift 4.2, die bisher neueste Version; Metal 2-Framework und einige Bibliotheksfunktionen, die von Metal Performance Shader bereitgestellt werden (Grundsätzlich lineare Algebrafunktionen). Obwohl Apple im Frühjahr 2017 das CoreML SDK auf den Markt gebracht hat, das eine gewisse Unterstützung für Faltungs-Neuronale Netzwerke beinhaltet, verwenden wir sie in Corgy nicht, um die unschätzbar wertvollen Erfahrungen bei der Entwicklung einer parallelisierten Implementierung der Netzwerkschichten zu sammeln und prägnante und intuitive APIs mit guter Benutzerfreundlichkeit und reibungsloser Lernkurve bereitzustellen damit die Benutzer ein Modell mühelos von anderen Frameworks migrieren können.
Unsere Zielmaschinen sind alle Geräte mit macOS und iOS, wie zum Beispiel iMac, MacBook, iPhone und iPad. Insbesondere das Gerät mit der Plattform, die die MPS-Bibliothek für lineare Algebra unterstützt (d. h. nach iOS 10.0 und macOS 10.13), was bedeutet, dass das iPhone nach dem iPhone 5, das iPad nach dem iPad (4. Generation) und der iPod Touch (6. Generation) auf den Markt kam. werden als iOS-Plattform unterstützt. Die Mac-Produktlinie wird noch umfassender abgedeckt, einschließlich iMac, die nach Ende 2009 oder neuer hergestellt wurden, aller MacBook-Serien, die nach Mitte 2010 auf den Markt kamen, und iMac Pro.
Die parallele Abstraktion von Metal 2 ist CUDA sehr ähnlich: Bei der Weiterleitung des Computerdurchlaufs an die GPU schreiben Programmierer zunächst Kernelfunktionen, die von jedem Thread ausgeführt werden, und geben dann die Anzahl der Thread-Gruppen (auch bekannt als Block in CUDA) im Raster an Anzahl der Threads in jeder Thread-Gruppe, Metal führt Kernel über dieses Raster aus, der Kernel ist in einem C++14-Dialekt namens Metal-Shading-Sprache implementiert. Innerhalb jeder Thread-Gruppe gibt es eine kleinere Einheit namens SIMD-Gruppe, d. h. eine Reihe von Threads, die dieselben SIMD-Anweisungen teilen. Bei unserer Implementierung besteht jedoch keine Notwendigkeit, dies zu berücksichtigen.
Metal stellt eine API namens MTLCommandBuffer bereit, die codierte Befehle speichert, die von der GPU festgeschrieben und ausgeführt werden. Jedes Mal, wenn wir eine von der GPU auszuführende Aufgabe starten möchten, werden die vorkompilierten Kernelfunktionen in GPU-Anweisungen codiert, in die Metal-Shading-Pipeline eingebettet und an MTLCommandBuffer gesendet. In dieser Phase wird auch der Metal-Puffer festgelegt, der zum Speichern der Berechnungsparameter verwendet wird, die an das Gerät übergeben werden müssen. Dann wäre der vom Befehlspuffer verarbeitete Befehl mit der angegebenen Anzahl von Thread-Gruppen und Threads pro Gruppe vollständig codiert und für die Übertragung an das Gerät bereit. Die GPU plant die Aufgabe und benachrichtigt den CPU-Thread, der die Arbeit übermittelt, nachdem die Ausführung abgeschlossen ist.
Die Kernelfunktion wird von MTLComputeCommandEncoder codiert und die Aufgabe wird für alle unterstützten Plattformen erstellt.
In unserer Implementierung haben wir weitgehend eine intuitive Methode genutzt, um das Element in GPU-Threads abzubilden: Ordnen Sie jedes Element im Ausgabetensor der aktuellen Ebene einem GPU-Thread zu: Jeder Thread berechnet und aktualisiert genau ein Element der Ausgabe, und die Eingabe erfolgt schreibgeschützt, sodass wir uns nicht um die Synchronisierung zwischen Threads kümmern müssen. Bei dieser Zuordnung lesen Threads mit kontinuierlichen IDs möglicherweise Eingabedaten von verschiedenen Speicherorten, schreiben jedoch immer in kontinuierliche Speicherorte. Es kommt also nicht zu Streuoperationen, wenn eine SIMD-Gruppe in den Speicher schreibt.
Wir haben eine Tensorklasse Variable als Grundlage für die gesamte Implementierung entworfen. Wir haben die Operation der linearen Algebra verwendet und in der Klasse Variable gekapselt, anstatt einen zusätzlichen Kernel zu schreiben, um tief in die Operation einzutauchen, die nicht unser Hauptaugenmerk ist, um die Komplexität der Implementierung zu reduzieren Und wir sparen Zeit, um uns auf die Beschleunigung der Netzwerkschichten zu konzentrieren.
1. Ändern Sie die Faltung in eine Riesenmatrixmultiplikation
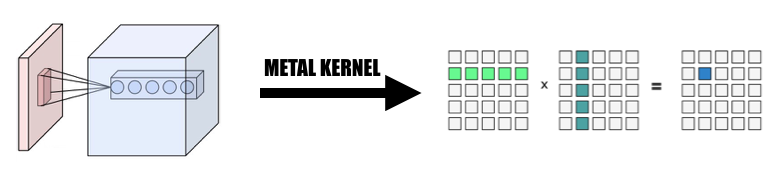
Wir sammeln die Daten aus der Eingabe auf parallele Weise, um eine Riesenmatrix sowohl der Eingabevariablen als auch der Gewichtung zu bilden. Wir speichern das Gewicht jeder Faltungsschicht zwischen, um eine Neuberechnung zu vermeiden. Die Auffüllung der Faltungsschicht wird während der Parallelisierungstransformation während der Berechnung generiert. Anschließend rufen wir MPSMatrixMultiply für die Riesenmatrix auf und transformieren die Daten aus der Riesenmatrix zurück in die von uns erstellte normale Tensorklasse. Die Methode wird in Unterrichtsfolien beschrieben.
2. Das Design und die Implementierung der Variablenklasse
Die Variablenklasse ist die Grundlage unserer Implementierung als Tensordarstellung. Wir haben die MPSMatrixMultiplication für die Variable gekapselt (definieren Sie das Unicode-Multiplikationszeichen (×) als Infix-Operator, um es elegant darzustellen :-)).
Die zugrunde liegende Datenstruktur der Variablen ist ein UnsafemutableBufferPointer , der auf den Datentyp verweist. Der Einfachheit halber haben wir den 32-Bit-Float gewählt. Die Variable -Klasse verwaltete zwei Datengrößen, die count enthielt die tatsächlich gespeicherte Elementnummer, die actualCount ist die Größe aller Elemente, die mit getpagesize() auf die Seitengröße der Plattform aufgerundet wurde.
Wir behalten diese beiden Werte bei, um sicherzustellen, dass makeBuffer(bytesNoCopy:) den Puffer direkt in der angegebenen VM-Region erstellt, und um eine redundante Neuzuweisung zu vermeiden, die den Overhead reduziert. Wenn der an Metal zu übergebende Speicher nicht seitenausgerichtet ist, kann Metal diesen Speicher nicht als Eingabe- oder Ausgabepuffer verwenden. Wir müssen die Methode makeBuffer(bytes:) verwenden, die einen neuen Puffer erstellt und Daten aus dem Eingabespeicherort kopiert. Daher müssen wir immer mehr Speicher zuweisen als nötig, um sicherzustellen, dass alle Speicher in Variable seitenausgerichtet sind. Wir benötigen also zwei Werte, um zu verfolgen, wie groß dieser Speicherblock genau ist und wie viel wir verwenden sollten.
3. Anzahl der Elemente, die von einem einzelnen Thread verarbeitet werden
Wir haben versucht, einen Thread mehreren Elementen zuzuordnen, von 2 bis 16 Elementen pro Thread. Die Leistung ist fast gleich, aber unser Projekt wird viel komplexer, daher haben wir diesen Ansatz verworfen.
Alle unten genannten CPU-Versionen sind naiver Single-Threaded-CPU-Code ohne SIMD-Optimierung. Es wird eine Compileroptimierung auf der Ebene -Ofast angewendet.
Die Leistung unserer Implementierung ist gut, nicht nicht gut genug.
Als Benchmark-Plattform haben wir ein iPhone 6s und ein 15-Zoll MacBook Pro verwendet. Die Hardware ist unten angegeben:
MacBook Pro (Retina 15 Zoll, Mitte 2015)
iPhone 6S
Im Vergleich zur naiven CPU-Versionsimplementierung ohne Parallelität ist unsere GPU-Version mehr als 60-mal schneller .
Da das MNIST-Modell zu klein ist, spiegelt sein Ergebnis möglicherweise nicht die genaue Beschleunigung wider. Und da wir keine gut implementierte Single-Threaded-Version haben, können wir keine genaue Beschleunigungszahl angeben. Da die CPU-Version zu langsam ist, ist die Geschwindigkeitssteigerung bei Tiny YOLO zu groß, um es zu glauben.
Netzwerkattribut des Experiments:
MNIST:
YOLO:
Messergebnis:
| iPhone 6s | MNIST | Winziger YOLO |
|---|---|---|
| CPU | 1500 ms | 753s |
| GPU | 0,025 s | 0,5s |
| beschleunigen | ~60x | ~1500x |
| MacBook Pro | MNIST | Winziger YOLO |
|---|---|---|
| CPU | 650 ms | 729er |
| GPU | 10 ms | 0,028 s |
| beschleunigen | ~65x | ~26000x |
Basierend auf dem obigen Benchmark können wir sehen, dass mit zunehmender Problemgröße
Warum sagen wir, dass unsere Beschleunigung nicht gut genug ist? Denn im Vergleich zur offiziellen Apple-Implementierung von MPSCNNConvolution sind wir nur etwa ein Drittel so schnell, was bedeutet, dass noch viel Optimierungsspielraum vorhanden ist. Dieser Vergleich basiert auf einer Open-Source-Implementierung von YOLO auf dem iPhone unter Verwendung der offiziellen MPSCNNConvolution die ~5 Bilder pro Sekunde erkennen kann, während unsere Implementierung nur ~2 Bilder pro Sekunde erreichen kann.
Und aufgrund der begrenzten Zeit konnten wir keine bessere Basisversion und CPU-parallelisierte Version für den Benchmark erstellen, wodurch die Geschwindigkeitssteigerung zu groß wird.
Es lohnt sich auch, den Leistungsgewinn bei verschiedenen Problemgrößen anzugeben. Wie wir sehen können, hat MNIST nur 0,1 Millionen Gewichtungen, während Tiny YOLO 17 Millionen hat. Tiny YOLO ist viel komplexer als MNIST, aber die Laufzeit der GPU-Version ließ sich nicht so stark skalieren. Das liegt wiederum am Amdahlschen Gesetz. Bei jedem Start einer GPU-Aufgabe müssen die entsprechenden GPU-Befehle in den Befehlspuffer codiert werden. Dieser Prozess ist von Natur aus seriell. Wenn die Problemgröße klein ist, trägt dieser Prozess viel zur Gesamtlaufzeit bei, sodass durch die Parallelisierung der Inferenzphase des neuronalen Netzwerks in MINST möglicherweise nicht die gleiche Geschwindigkeit erreicht wird wie in Tiny YOLO, wo der Laufzeitaufwand vernachlässigbar ist.
Was hat Ihre Beschleunigung eingeschränkt?
if s und for s, die zu Divergenzen führen können, was zu einer schlechten SIMD-Auslastung führt.Tiefergehende Analyse: Aufschlüsselung der Ausführungszeit der verschiedenen Phasen.
Nehmen wir als Beispiel Tiny YOLO: In einem Beispiellauf mit einer Gesamtlaufzeit von 227 ms auf einem MacBook verbrauchten die Faltungsschichten 207 ms, also 92 % der Gesamtlaufzeit. Die Pooling-Schichten benötigten 14 ms (6 %) und ReLU 6 ms (2 %). Wenn wir die Leistung weiter verbessern wollen, sollten wir laut Amdahls Gesetz auf jeden Fall weiter an der Faltungsschicht arbeiten.
Insgesamt glauben wir, dass unsere Wahl des Metal-Frameworks zur Beschleunigung neuronaler Netzwerke auf iOS- und macOS-Geräten sinnvoll ist, insbesondere für iOS-Geräte. Da es selbst mit SIMD-Anweisungen weniger Kerne hat, ist es weniger wahrscheinlich, dass eine gut abgestimmte CPU-Version eine ähnliche Leistung wie die GPU-Version erzielt.
Beide Teammitglieder leisten die gleiche Arbeit.
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


