mini searcher
1.0.0
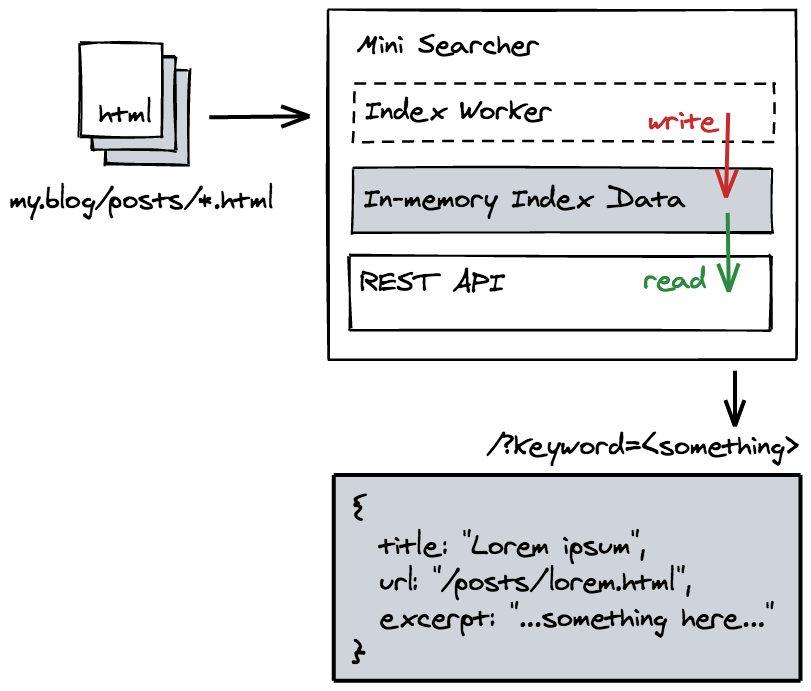
Der Mini Site Searcher ist ein einfacher Site-Indexer und eine Suchmaschine, die den Inhalt Ihrer Website automatisch crawlt und zwischenspeichert und über eine REST-API eine Suchfunktion bereitstellt.
Es kann verwendet werden, um die Suchfunktion für statische Website-Blogs bereitzustellen oder um eine durchsuchbare persönliche Wissensdatenbank aufzubauen ...
Zuerst müssen Sie eine .env Datei erstellen, um zu beschreiben, wie Sie den Crawler einrichten möchten.
Wenn wir beispielsweise mit der folgenden Konfiguration einen Indexer für eine Website unter https://my.blog einrichten möchten, beginnt der Crawler mit der Suche auf der Seite https://my.blog/index.html und findet alle Link, dessen URL /posts enthält, daher sollte der CSS-Selektor dafür a[href*=/posts] sein. Und wenn der Crawler jedem Link folgt, erhält er den Textinhalt aller <article class="main-content"> -Tags.
BASE_URL="https://my.blog"
ENTRY_POINT="https://my.blog/index.html"
LINK_SEARCH_PATTERN="a[href*='/posts']"
MAIN_CONTENT_PATTERN="article.main-content"
Führen Sie dann den Server aus:
cargo run
Nach dem Start wird der Crawler aktiv und es kann eine Weile dauern, bis die Indizierung abgeschlossen ist. Eine REST-API wird auch am Standardport 3366 oder was auch immer in Ihrer PORT Umgebungsvariablen bereitgestellt wird. Um zu suchen, stellen Sie eine GET Anfrage wie diese:
GET /?keyword=<something>
Das Programm besteht aus zwei Komponenten: