disclosure backend static
1.0.0
Das disclosure-backend-static -Repo ist das Backend, das Open Disclosure California unterstützt.
Es wurde in aller Eile im Vorfeld der Wahlen 2016 entwickelt und basiert daher auf der „Get it done“-Philosophie. Zu diesem Zeitpunkt hatten wir bereits eine API entworfen und (den größten Teil) ein Frontend erstellt; Dieses Repo wurde erstellt, um diese so schnell wie möglich umzusetzen.
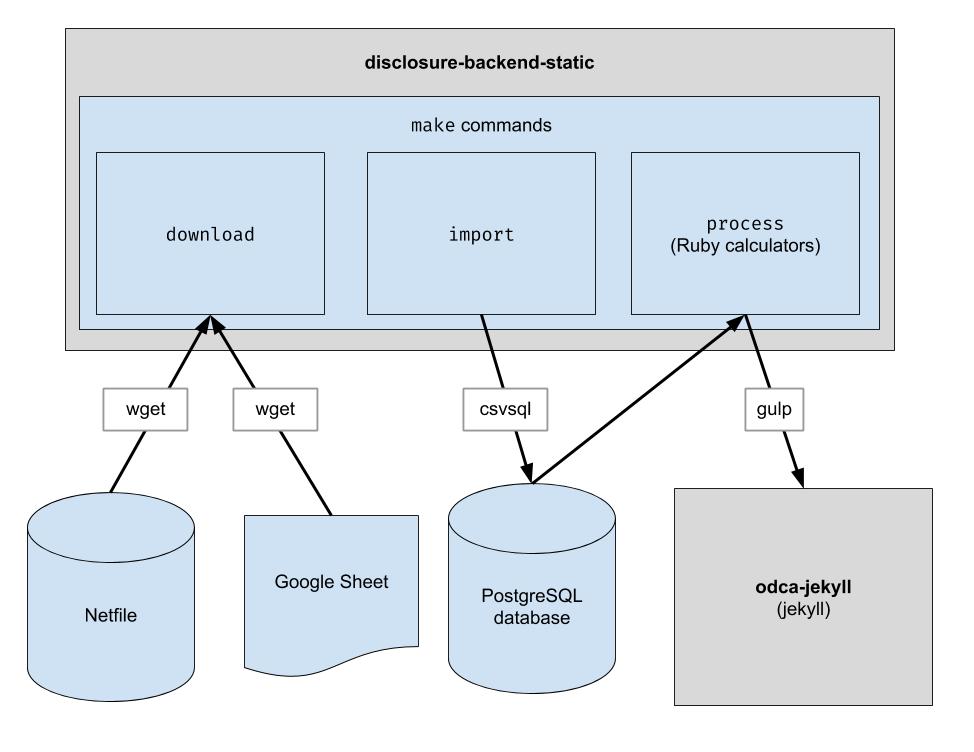
Dieses Projekt implementiert eine grundlegende ETL-Pipeline, um die Netfile-Daten von Oakland herunterzuladen, die von Menschen kuratierten CSV-Daten für Oakland herunterzuladen und die beiden zu kombinieren. Die Ausgabe ist ein Verzeichnis mit JSON-Dateien, die die vorhandene API-Struktur nachahmen, sodass keine Änderungen am Client-Code erforderlich sind.
.ruby-version ) Hinweis: Sie müssen diese Befehle nicht ausführen, um im Frontend zu entwickeln. Sie müssen lediglich das Repository neben dem Frontend-Repository klonen.
Wenn Sie planen, den Backend-Code zu ändern, befolgen Sie diese Schritte, um alle erforderlichen Entwicklungsabhängigkeiten einzurichten, einschließlich einer neuen PostgreSQL-Datenbank und Python 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip anstelle von pip um sicherzustellen, dass Python 3 verwendet wird: python3 -m pip install ...
pip Ihres Systems auf Python 3 verweist, können Sie pip direkt verwenden: pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
Dieses Repository ist für die Arbeit in einem Container unter Codespaces eingerichtet. Mit anderen Worten: Sie können eine bereits eingerichtete Umgebung starten, ohne die Installationsschritte ausführen zu müssen, die zum Einrichten einer lokalen Umgebung erforderlich sind. Dies kann als Möglichkeit zur Fehlerbehebung bei Code verwendet werden, bevor er in die Produktionspipeline übernommen wird. Die folgenden Informationen können für den Einstieg in die Verwendung von Codespaces hilfreich sein:
Code und dann im Dropdown-Menü auf die Registerkarte Codespaces ./workspace angezeigt wird, die Ihnen bekannt vorkommt, wenn Sie bereits mit VS Code gearbeitet habenmake downloadpsql in das Terminal eingeben, um eine Verbindung zum Server herzustellenmake import füllt die Postgres-Datenbankgit push ausführenDieses Repository ist auch für die Ausführung in einem Docker-Container konfiguriert. Dies ähnelt Codespaces, außer dass Sie jede beliebige IDE und lokale Einrichtung verwenden können, die Sie bevorzugen. So beginnen Sie mit der Verwendung von Docker mit VSCode:
Laden Sie die Rohdatendateien herunter. Sie müssen dies nur ab und zu ausführen, um die neuesten Daten zu erhalten.
$ make download
Importieren Sie die Daten zur einfacheren Verarbeitung in die Datenbank. Sie müssen dies erst ausführen, nachdem Sie neue Daten heruntergeladen haben.
$ make import
Führen Sie die Taschenrechner aus. Alles wird in den Ordner „build“ ausgegeben.
$ make process
Optional können Sie die Build-Ausgaben in Algolia neu indizieren. (Für die Neuindizierung sind die Umgebungsvariablen ALGOLIASEARCH_APPLICATION_ID und ALGOLIASEARCH_API_KEY erforderlich.)
$ make reindex
Wenn Sie die statischen JSON-Dateien über einen lokalen Webserver bereitstellen möchten:
$ make run
Wenn make import ausgeführt wird, werden mehrere Postgres-Tabellen zum Importieren der heruntergeladenen Daten erstellt. Das Schema dieser Tabellen ist explizit im Verzeichnis dbschema definiert und muss möglicherweise in Zukunft aktualisiert werden, um zukünftige Daten aufzunehmen. Spalten, die Zeichenfolgendaten enthalten, sind möglicherweise nicht groß genug für zukünftige Daten. Wenn beispielsweise eine Namensspalte Namen mit maximal 20 Zeichen akzeptiert und wir in Zukunft Daten haben, bei denen der Name 21 Zeichen lang ist, schlägt der Datenimport fehl. In diesem Fall müssen wir die entsprechende Schemadatei in dbschema aktualisieren, um mehr Zeichen zu unterstützen. Nehmen Sie einfach die Änderung vor und führen Sie make import erneut aus, um zu überprüfen, ob der Vorgang erfolgreich ist.
Dieses Repository wird zum Generieren von Datendateien verwendet, die von der Website verwendet werden. Nachdem make process ausgeführt wurde, wird ein build -Verzeichnis generiert, das die Datendateien enthält. Dieses Verzeichnis wird in das Repository eingecheckt und später beim Generieren der Website ausgecheckt. Nachdem Sie Codeänderungen vorgenommen haben, ist es wichtig, das generierte build -Verzeichnis mit dem build -Verzeichnis zu vergleichen, das vor den Codeänderungen generiert wurde, und zu überprüfen, ob die Änderungen aufgrund der Codeänderungen den Erwartungen entsprechen.
Da ein strikter Vergleich aller Inhalte des build -Verzeichnisses immer Änderungen einschließt, die unabhängig von Codeänderungen auftreten, muss jeder Entwickler über diese erwarteten Änderungen Bescheid wissen, um diese Prüfung durchführen zu können. Um dies zu vermeiden, generiert eine bestimmte Datei, bin/create-digests.py , Digests für JSON-Daten im build -Verzeichnis, nachdem diese erwarteten Änderungen ausgeschlossen wurden. Um nach Änderungen zu suchen, die diese erwarteten Änderungen ausschließen, suchen Sie einfach nach einer Änderung in der Datei build/digests.json .
Derzeit sind dies die erwarteten Änderungen, die unabhängig von Codeänderungen auftreten:
Die erwarteten Änderungen werden ausgeschlossen, bevor Digests für Daten im build -Verzeichnis generiert werden. Die Logik hierfür finden Sie in der Funktion clean_data , die sich in der Datei bin/create-digests.py befindet. Nachdem der Code so geändert wurde, dass eine erwartete Änderung nicht mehr vorhanden ist, kann der Ausschluss dieser Änderung aus clean_data entfernt werden. Beispielsweise ist die Rundung von Gleitkommazahlen aufgrund von Unterschieden in der Umgebung nicht bei jeder Ausführung make process gleich. Wenn der Code so korrigiert ist, dass die Rundung von Gleitkommazahlen dieselbe ist, solange sich die Daten nicht geändert haben, kann der Aufruf round_float in clean_data entfernt werden.
Es wurde ein zusätzliches Skript erstellt, um einen Bericht zu erstellen, der den Vergleich der Gesamtergebnisse der Kandidaten ermöglicht. Das Skript heißt bin/report-candidates.py und generiert build/candidates.csv und build/candidates.xlsx . Die Berichte enthalten eine Liste aller Kandidaten und auf mehrere Arten berechnete Gesamtsummen, die in der Summe die gleiche Zahl ergeben sollten.
Um sicherzustellen, dass Datenbankschemaänderungen in Pull-Requests sichtbar sind, wird das vollständige Postgres-Schema auch in einer schema.sql Datei im build -Verzeichnis gespeichert. Da das build -Verzeichnis für jeden Zweig in einem PR automatisch neu erstellt und im Repository festgeschrieben wird, wird jede durch eine Codeänderung verursachte Änderung am Schema bei der Überprüfung des PR als Unterschied in der Datei schema.sql angezeigt.
Jede Kennzahl für einen Kandidaten wird unabhängig berechnet. Eine Metrik könnte etwa „Gesamtzahl der erhaltenen Beiträge“ oder etwas komplexeres wie „Prozentsatz der Beiträge, die weniger als 100 US-Dollar betragen“ sein.
Wenn Sie eine neue Berechnung hinzufügen, ist das offizielle Formular 460 ein guter erster Ausgangspunkt. Sind die gesuchten Daten auf diesem Formular angegeben? Wenn ja, werden Sie es wahrscheinlich nach dem Importvorgang in Ihrer Datenbank finden. Es gibt auch ein paar andere Formulare, die wir importieren, wie z. B. Formular 496. (Dies sind die Namen der Dateien im input . Schauen Sie sich diese an.)
Jeder Zeitplan jedes Formulars wird in eine separate Postgres-Tabelle importiert. Beispielsweise wird Anhang A des Formulars 460 in die Tabelle A-Contributions importiert.
Da Sie nun die Möglichkeit haben, die Daten abzufragen, sollten Sie eine SQL-Abfrage erstellen, die den Wert berechnet, den Sie erhalten möchten. Sobald Sie Ihre Berechnung als SQL ausdrücken können, fügen Sie sie wie folgt in eine Rechnerdatei ein:
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID auswählt.candidate.save_calculation aktualisieren. Diese Methode serialisiert ihr zweites Argument als JSON, sodass jede Art von Daten gespeichert werden kann.candidate.calculation(:your_thing) abgerufen werden. Sie sollten dies zu einer API-Antwort in der Datei process.rb hinzufügen. Auf diese Weise fließen die Daten durch das Backend. Finanzdaten werden aus Netfile abgerufen, das durch ein Google Sheet ergänzt wird, das Filer-IDs den Wahlinformationen wie Kandidatennamen, Ämtern, Wahlmaßnahmen usw. zuordnet. Sobald die Daten gefiltert, aggregiert und transformiert sind, verarbeitet das Frontend sie und erstellt den statischen HTML-Code Frontend.
Während der Bundle-Installation
error: use of undeclared identifier 'LZMA_OK'
Versuchen:
brew unlink xz
bundle install
brew link xz
Während make download
wget: command not found
Führen Sie brew install wget .
Während make import
Es scheint, dass auf Macintosh-Systemen, die Apple-Chips verwenden, ein Problem vorliegt.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
Versuchen Sie Folgendes:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


