feathr
v1.0.0

Feathr ist eine Daten- und KI-Engineering-Plattform, die seit vielen Jahren in der Produktion bei LinkedIn weit verbreitet ist und im Jahr 2022 als Open Source verfügbar war. Derzeit handelt es sich um ein Projekt der LF AI & Data Foundation.
Lesen Sie unsere Ankündigung zu Open Sourcing Feathr und Feathr auf Azure sowie die Ankündigung der LF AI & Data Foundation.
Mit Feather können Sie:
Feathr ist besonders nützlich bei der KI-Modellierung, wo es Ihre Feature-Transformationen automatisch berechnet und mit Ihren Trainingsdaten verknüpft. Dabei wird eine zeitpunktkorrekte Semantik verwendet, um Datenlecks zu vermeiden, und es unterstützt die Materialisierung und Bereitstellung Ihrer Features für den Online-Einsatz in der Produktion.
Der einfachste Weg, Feathr auszuprobieren, ist die Verwendung der Feathr-Sandbox, einem eigenständigen Container mit den meisten Funktionen von Feathr. Sie sollten in 5 Minuten produktiv sein. Um es zu verwenden, führen Sie einfach diesen Befehl aus:
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0Und Sie können sich das Feathr-Schnellstart-Jupyter-Notizbuch ansehen:
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynbNach dem Ausführen des Notebooks werden alle Funktionen in der Benutzeroberfläche registriert und Sie können die Feathr-Benutzeroberfläche unter folgender Adresse besuchen:
http://localhost:8081Wenn Sie den Feathr-Client in einer Python-Umgebung installieren möchten, verwenden Sie Folgendes:
pip install feathrOder verwenden Sie den neuesten Code von GitHub:
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeathr verfügt über native Integrationen mit Databricks und Azure Synapse:
Befolgen Sie die Feathr ARM-Bereitstellungsanleitung, um Feathr auf Azure auszuführen. Dadurch können Sie schnell mit der automatisierten Bereitstellung mithilfe der Azure Resource Manager-Vorlage beginnen.
Wenn Sie alles manuell einrichten möchten, können Sie sich die Anleitung zur Feathr-CLI-Bereitstellung ansehen, um Feathr auf Azure auszuführen. Auf diese Weise können Sie verstehen, was vor sich geht, und jeweils eine Ressource einrichten.
| Name | Beschreibung | Plattform |
|---|---|---|
| NYC Taxi-Demo | Schnellstart-Notizbuch, das zeigt, wie Funktionen mit Beispieldaten zur Taxipreisvorhersage in New York definiert, materialisiert und registriert werden. | Azure Synapse, Databricks, Local Spark |
| Databricks Quickstart NYC Taxi-Demo | Schnellstart-Databricks-Notizbuch mit Beispieldaten für die Taxipreisvorhersage in New York. | Datenbausteine |
| Feature-Einbettung | Feathr UDF-Beispiel, das zeigt, wie die Funktionseinbettung mit einem vorab trainierten Transformer-Modell und Beispieldaten für Hotelbewertungen definiert und verwendet wird. | Datenbausteine |
| Demo zur Betrugserkennung | Ein Beispiel zur Veranschaulichung des Feature Store unter Verwendung mehrerer Datenquellen wie Benutzerkonto- und Transaktionsdaten. | Azure Synapse, Databricks, Local Spark |
| Produktempfehlungsdemo | Beispielnotizbuch für den Feathr Feature Store mit einem Produktempfehlungsszenario | Azure Synapse, Databricks, Local Spark |
Weitere Beispiele finden Sie unter „Feathr Full Capabilities“. Nachfolgend einige ausgewählte:
Feathr bietet eine intuitive Benutzeroberfläche, sodass Sie alle verfügbaren Funktionen und ihre entsprechenden Abstammungen durchsuchen und erkunden können.
Sie können die Feathr-Benutzeroberfläche verwenden, um nach Features zu suchen, Datenquellen zu identifizieren, Feature-Abstammungen zu verfolgen und Zugriffskontrollen zu verwalten. Sehen Sie sich hier die neueste Live-Demo an, um zu sehen, was Feathr UI für Sie tun kann. Verwenden Sie eines der folgenden Konten, wenn Sie zur Anmeldung aufgefordert werden:
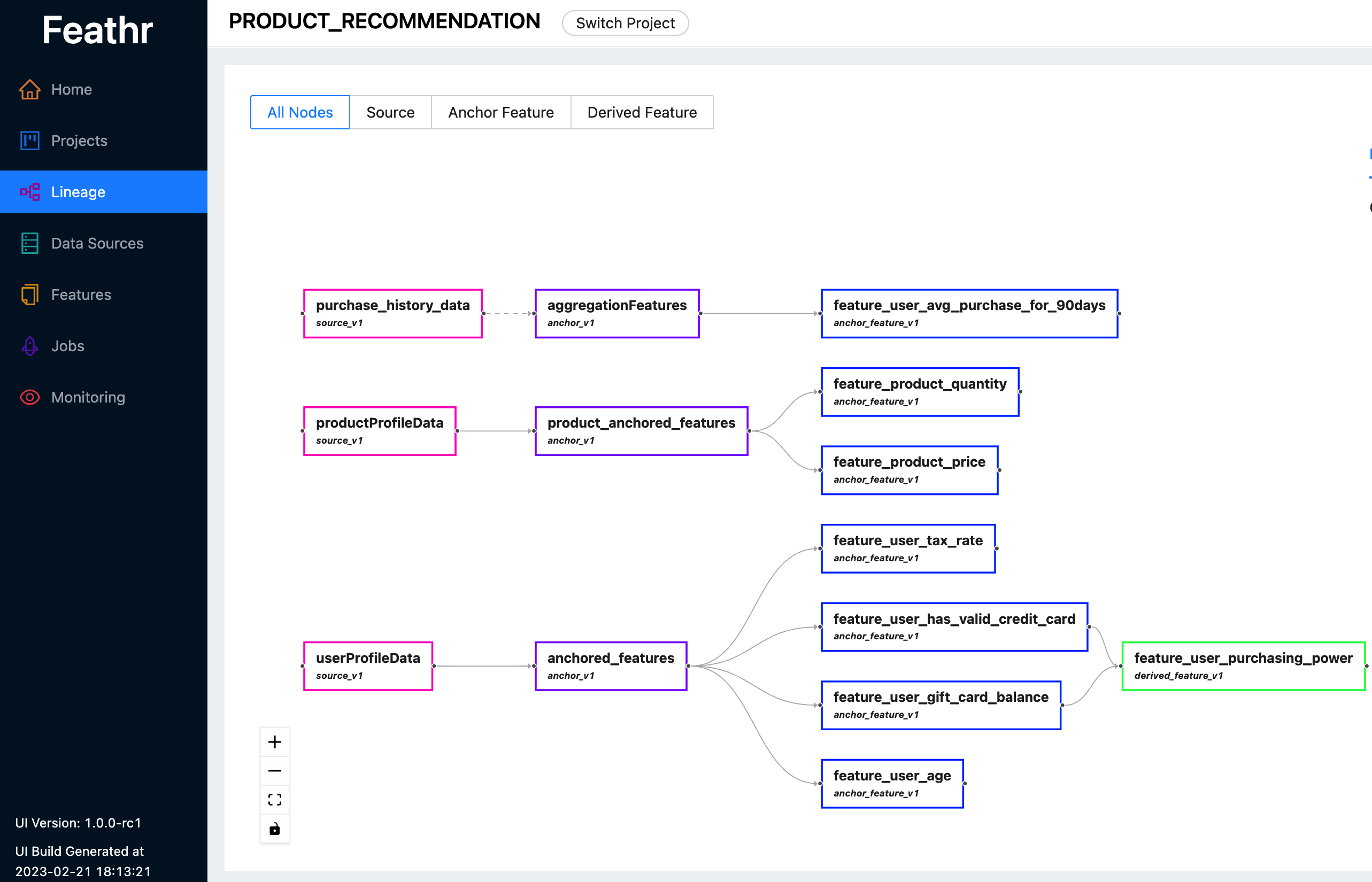
Weitere Informationen zur Feathr-Benutzeroberfläche und der dahinter stehenden Registrierung finden Sie unter Feathr Feature Registry
Feathr verfügt über hochgradig anpassbare UDFs mit nativer PySpark- und Spark SQL-Integration, um den Lernaufwand für Datenwissenschaftler zu verkürzen:
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )Weitere Informationen finden Sie im Leitfaden zur Streaming-Quellenaufnahme.
Weitere Informationen finden Sie unter „Punkt-in-Zeit-Korrektheit“ und „Punkt-in-Zeit-Join in Feathr“.
Folgen Sie dem Schnellstart-Jupyter-Notebook, um es auszuprobieren. Es gibt auch eine begleitende Kurzanleitung mit etwas mehr Erläuterungen zum Notebook.
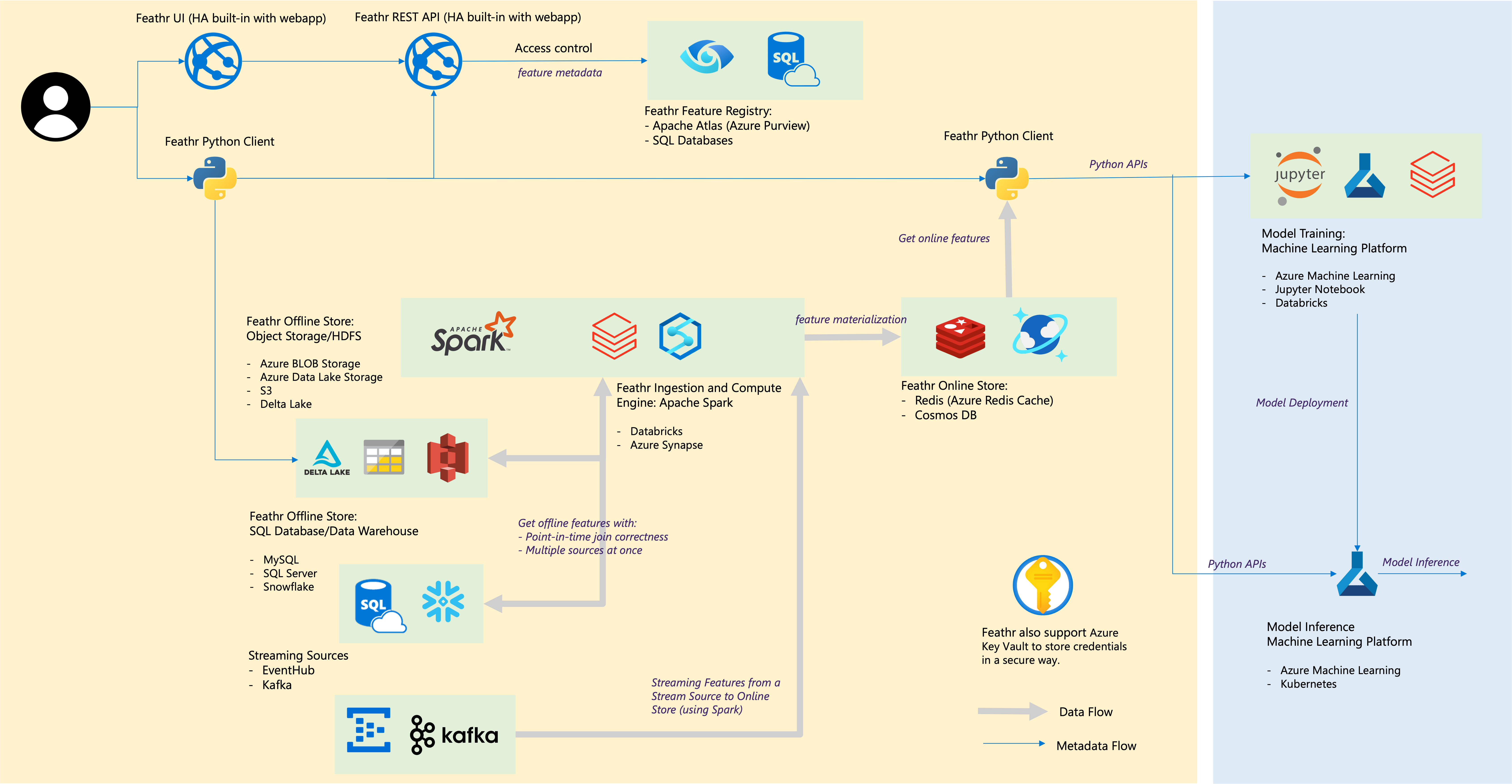
| Federkomponente | Cloud-Integrationen |
|---|---|
| Offline-Speicher – Objektspeicher | Azure Blob Storage, Azure ADLS Gen2, AWS S3 |
| Offline-Speicher – SQL | Azure SQL DB, Azure Synapse Dedicated SQL Pools, Azure SQL in VM, Snowflake |
| Streaming-Quelle | Kafka, EventHub |
| Online-Shop | Redis, Azure Cosmos DB |
| Feature-Registrierung und Governance | Azure Purview, ANSI SQL wie Azure SQL Server |
| Compute Engine | Azure Synapse Spark-Pools, Databricks |
| Plattform für maschinelles Lernen | Azure Machine Learning, Jupyter Notebook, Databricks Notebook |
| Dateiformat | Parkett, ORC, Avro, JSON, Delta Lake, CSV |
| Anmeldeinformationen | Azure Key Vault |
Bauen Sie für die Community und bauen Sie von der Community. Schauen Sie sich die Community-Richtlinien an.
Treten Sie unserem Slack-Kanal für Fragen und Diskussionen bei (oder klicken Sie auf den Einladungslink).


