imagen pytorch
2.1.0
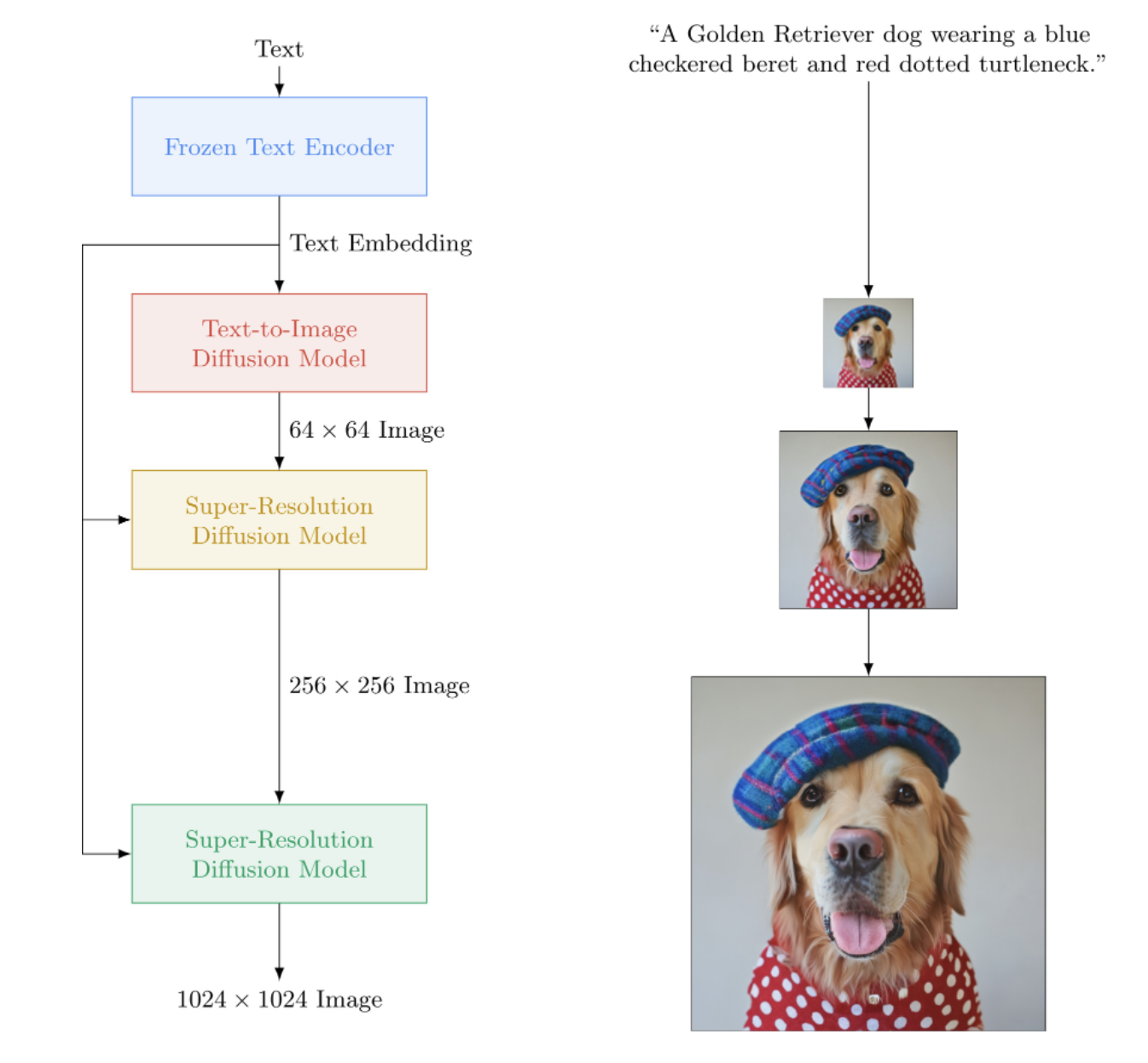
Implementierung von Imagen, dem neuronalen Text-to-Image-Netzwerk von Google, das DALL-E2 übertrifft, in Pytorch. Es ist das neue SOTA für die Text-zu-Bild-Synthese.
Architektonisch ist es tatsächlich viel einfacher als DALL-E2. Es besteht aus einem kaskadierenden DDPM, das auf Texteinbettungen aus einem großen vorab trainierten T5-Modell (Aufmerksamkeitsnetzwerk) basiert. Es enthält außerdem dynamisches Clipping für eine verbesserte klassifikatorfreie Führung, Rauschpegelkonditionierung und ein speichereffizientes Einheitendesign.
Es scheint, dass weder CLIP noch ein vorheriges Netzwerk erforderlich sind. Und so geht die Forschung weiter.
KI-Kaffeepause mit Letitia | Versammlungs-KI | Yannic Kilcher
Bitte treten Sie bei, wenn Sie daran interessiert sind, bei der Replikation mit der LAION-Community mitzuhelfen
StabilityAI für das großzügige Sponsoring sowie meine anderen Sponsoren da draußen
? Huggingface für ihre erstaunliche Transformers-Bibliothek. Der Text-Encoder-Teil ist dadurch weitgehend erledigt
Jonathan Ho, der durch seine bahnbrechende Arbeit eine Revolution in der generativen künstlichen Intelligenz herbeigeführt hat
Sylvain und Zachary für die Accelerate-Bibliothek, die dieses Repository für verteiltes Training verwendet
Alex für einops, unverzichtbares Werkzeug zur Tensormanipulation
Jorge Gomes für seine Hilfe beim T5-Ladecode und seine Ratschläge zur richtigen T5-Version
Katherine Crowson, für ihren schönen Code, der mir geholfen hat, die zeitkontinuierliche Version der Gaußschen Diffusion zu verstehen
Marunine und Netruk44 für die Überprüfung des Codes, die Weitergabe experimenteller Ergebnisse und die Hilfe beim Debuggen
Marunine für die Bereitstellung einer möglichen Lösung für ein Farbverschiebungsproblem in den speichereffizienten U-Nets. Vielen Dank an Jacob für die Bereitstellung experimenteller Vergleiche zwischen den Basis- und speichereffizienten Einheiten
Marunine für das Finden zahlreicher Fehler, die Lösung eines Problems mit der Größenänderungsberechtigung und für das Teilen seiner experimentellen Konfigurationen und Ergebnisse
MalumaDev für seinen Vorschlag zur Verwendung eines Pixel-Shuffle-Upsamplers zur Behebung von Checkboard-Artefakten
Valentin für den Hinweis auf unzureichende Skip-Verbindungen im Unet sowie die spezifische Methode der Aufmerksamkeitskonditionierung im Basis-Unet im Anhang
BIGJUN zum Fangen eines großen Käfers mit kontinuierlicher Konditionierung des Gaußschen Diffusionsrauschpegels zur Inferenzzeit
Bingbing zum Identifizieren eines Fehlers mit Sampling und Reihenfolge der Normalisierung und Rauschen mit Konditionierungsbild mit niedriger Auflösung
Kay für seinen Beitrag zum One-Line-Command-Training von Imagen!
Hadrien Reynaud für das Testen von Text-to-Video an einem medizinischen Datensatz, das Teilen seiner Ergebnisse und das Identifizieren von Problemen!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)Für ein einfacheres Training können Sie Textzeichenfolgen direkt bereitstellen, anstatt Textkodierungen vorab zu berechnen. (Obwohl Sie aus Skalierungsgründen auf jeden Fall die Texteinbettungen und die Maske vorab berechnen möchten)
Bei diesem Weg muss die Anzahl der Textbeschriftungen zur Stapelgröße der Bilder passen.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () Mit der ImagenTrainer -Wrapper-Klasse werden die exponentiellen gleitenden Durchschnitte für alle U-Netze im kaskadierenden DDPM beim Aufruf von update automatisch berücksichtigt
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)Sie können Imagen auch ohne Text (bedingungslose Bildgenerierung) wie folgt trainieren
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)Oder trainieren Sie nur superauflösende Einheiten
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) Mit den save und load können Sie jederzeit den Trainer und alle zugehörigen Zustände speichern und laden. Es wird empfohlen, diese Methoden zu verwenden, anstatt manuell mit einem state_dict -Aufruf zu speichern, da im Trainer eine gewisse Gerätespeicherverwaltung unter der Haube erfolgt.
ex.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 Sie können sich auch darauf verlassen, dass ImagenTrainer DataLoader -Instanzen automatisch trainiert. Sie müssen lediglich Ihren DataLoader so gestalten, dass er entweder images (für den bedingungslosen Fall) oder ('images', 'text_embeds') für die textgesteuerte Generierung zurückgibt.
ex. bedingungslose Ausbildung
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )Dank ? Beschleunigen Sie, Sie können in zwei Schritten ganz einfach Multi-GPU-Training durchführen.
Zuerst müssen Sie accelerate config im selben Verzeichnis wie Ihr Trainingsskript aufrufen (sagen wir, es heißt train.py ).
$ accelerate config Als nächstes würden Sie, anstatt python train.py wie für eine einzelne GPU aufzurufen, die Beschleunigungs-CLI als solche verwenden
$ accelerate launch train.pyDas ist es!
Imagen kann auch direkt über CLI verwendet werden.
ex.
$ imagen configoder
$ imagen config --path ./configs/config.jsonIn der Konfiguration können Sie Einstellungen für den Trainer, den Datensatz und die Bildkonfiguration ändern.
Die Imagen-Konfigurationsparameter finden Sie hier
Die Konfigurationsparameter von Elucidated Imagen finden Sie hier
Die Imagen Trainer-Konfigurationsparameter finden Sie hier
Für die Datensatzparameter können alle Dataloader-Parameter verwendet werden.
Mit diesem Befehl können Sie Ihr Modell trainieren oder das Training fortsetzen
ex.
$ imagen trainoder
$ imagen train --unet 2 --epoches 10Sie können folgende Argumente an den Trainingsbefehl übergeben.
--config gibt die Konfigurationsdatei an, die für das Training verwendet werden soll [Standard: ./imagen_config.json]--unet der Index des zu trainierenden Unets [Standard: 1]--epoches für wie viele Epochen trainiert werden soll [Standard: 50]Beachten Sie bei der Probenahme, dass Ihr Kontrollpunkt alle Einheiten trainiert haben sollte, um ein brauchbares Ergebnis zu erhalten.
ex.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngSie können die folgenden Argumente an den Beispielbefehl übergeben.
--model gibt die Modelldatei an, die für die Probenahme verwendet werden soll--cond_scale Konditionierungsskala (klassifikatorfreie Führung) im Decoder--load_ema lädt die EMA-Version von Unets, falls verfügbar Um einen gespeicherten Prüfpunkt mit dieser Funktion zu verwenden, müssen Sie entweder Ihre Imagen-Instanz mithilfe der Konfigurationsklassen ImagenConfig und ElucidatedImagenConfig instanziieren oder direkt über die CLI einen Prüfpunkt erstellen
Für eine ordnungsgemäße Schulung möchten Sie wahrscheinlich sowieso ein konfigurationsgesteuertes Training einrichten.
ex.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalSo einfach sollte es eigentlich sein
Sie können diese Prüfpunktdatei auch weitergeben, und jeder kann seine eigenen Daten weiter optimieren
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning Inpainting folgt der Formulierung des aktuellen Repaint-Artikels. Übergeben Sie einfach inpaint_images und inpaint_masks an die sample für Imagen oder ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) Für Videos übergeben Sie Ihre Videos ebenfalls an das Schlüsselwort inpaint_videos in .sample . Die Inpainting-Maske kann entweder für alle Frames gleich (batch, height, width) oder unterschiedlich (batch, frames, height, width) sein.
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) Tero Karras von StyleGAN hat einen neuen Artikel geschrieben, dessen Ergebnisse von einer Reihe unabhängiger Forscher sowie auf meinem eigenen Computer bestätigt wurden. Ich habe beschlossen, eine Version von Imagen zu erstellen, die ElucidatedImagen , damit man das neue elucidated DDPM für die textgesteuerte Kaskadengenerierung verwenden kann.
Importieren Sie einfach ElucidatedImagen und instanziieren Sie dann die Instanz wie zuvor. Die Hyperparameter unterscheiden sich von den üblichen für diskrete und kontinuierliche Gauß-Diffusion und können für jede Einheit in der Kaskade individuell angepasst werden.
Ex.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above Dieses Repository wird auch damit beginnen, neue Forschungsergebnisse zur textgesteuerten Videosynthese zu sammeln. Zunächst wird die von Jonathan Ho in „Video Diffusion Models“ beschriebene 3D-Unit-Architektur übernommen
Update: bestätigte Funktionsfähigkeit von Hadrien Reynaud!
Ex.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) Sie können auch zuerst an Text-Bild-Paaren trainieren. Unet3D konvertiert es automatisch in Videos mit Einzelbildern und lernt ohne zeitliche Komponenten (durch automatisches Festlegen von ignore_time = True ), unabhängig davon, ob es sich um 1D-Faltungen oder kausale Aufmerksamkeit über die Zeit handelt.
Dies ist der aktuelle Ansatz aller großen Labore für künstliche Intelligenz (Brain, MetaAI, Bytedance).
Imagen verwendet einen Algorithmus namens Classifier Free Guidance. Beim Sampling wenden Sie eine Skalierung auf die Konditionierung (in diesem Fall Text) von mehr als 1.0 an.
Der Forscher Netruk44 hat berichtet, dass 5-10 optimal sind, aber alles, was größer als 10 ist, wird durchbrochen.
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averageIm Moment noch nicht, aber wahrscheinlich wird einer im Laufe des Jahres, wenn nicht früher, geschult und Open-Source-fähig sein. Wenn Sie teilnehmen möchten, können Sie der Community der Trainer für künstliche neuronale Netze in Laion beitreten (Link zu Discord finden Sie in der Readme-Datei oben) und mit der Zusammenarbeit beginnen.
Ein Grund mehr, warum Sie ab heute mit dem Training Ihres eigenen Modells beginnen sollten! Das Letzte, was wir brauchen, ist, dass sich diese Technologie in den Händen einiger weniger Eliten befindet. Hoffentlich reduziert dieses Repository die Arbeit darauf, nur die erforderliche Rechenleistung zu finden und sie mit Ihrem eigenen kuratierten Datensatz zu ergänzen.
Irgendetwas! Es ist MIT-lizenziert. Mit anderen Worten: Sie können sie für Ihre eigene Recherche frei kopieren/einfügen und für jede erdenkliche Modalität remixen. Trainieren Sie erstaunliche Modelle aus Profitgründen, für die Wissenschaft oder einfach, um Ihr persönliches Vergnügen zu stillen, wenn Sie Zeuge werden, wie sich etwas Göttliches vor Ihren Augen entfaltet.
Echokardiogramm-Synthese [Code]
SOTA Hi-C Kontaktmatrixsynthese [Code]
Grundrisserstellung
Ultrahochauflösende Histopathologie-Objektträger
Synthetische laparoskopische Bilder
Entwerfen von Metamaterialien
Audioübertragung von Flavio Schneider
Minibild von Ryan O. | AssemblyAI-Beitrag
Verwenden Sie Huggingface-Transformatoren für T5-kleine Texteinbettungen
Fügen Sie dynamische Schwellenwerte hinzu
Fügen Sie außerdem das dynamische Schwellenwert-DALLE2 und das Videodiffusions-Repository hinzu
Ermöglichen Sie die Einstellung von T5-groß (und möglicherweise einer kleinen Fabrikmethode, um jeden Huggingface-Transformator aufzunehmen).
Fügen Sie den Low-Res-Rauschpegel mit dem Pseudocode im Anhang hinzu und finden Sie heraus, was für ein Sweep sie zur Inferenzzeit durchführen
Port über etwas Trainingscode von DALLE2
Sie müssen in der Lage sein, pro Einheit einen anderen Rauschplan zu verwenden (Kosinus wurde für die Basis verwendet, aber linear für SR).
Erstellen Sie einfach eine Master-konfigurierbare Einheit
Vollständiger Resnet-Block (Biggan-inspiriert?, aber mit Gruppennorm) – vollständige Selbstaufmerksamkeit
Vollständiger Konditionierungs-Einbettungsblock (und ihn vollständig konfigurierbar machen, sei es Aufmerksamkeit, Film usw.)
Erwägen Sie die Verwendung von Pearcer-Resampler von https://github.com/lucidrains/flamingo-pytorch anstelle der Aufmerksamkeitsbündelung
Fügen Sie zusätzlich zu Queraufmerksamkeit und Film die Option zur Aufmerksamkeitsbündelung hinzu
Fügen Sie dem Trainer für jede Einheit einen optionalen Kosinus-Abklingplan mit Aufwärmen hinzu
Wechseln Sie zu kontinuierlichen Zeitschritten statt zu diskretisierten, da dies anscheinend für alle Phasen verwendet wurde. Finden Sie zunächst den Fall des linearen Rauschplans aus dem Variations-ddpm-Artikel https://openreview.net/forum?id=2LdBqxc1Yv heraus
Berechnen Sie log(snr) für den Alpha-Cosinus-Rauschenplan.
Unterdrücken Sie die Transformatorwarnung, da nur der T5-Encoder verwendet wird
Erlauben Sie die Einstellung für die Verwendung linearer Aufmerksamkeit auf Ebenen, bei denen die volle Aufmerksamkeit nicht verwendet werden kann
Erzwinge unets im zeitkontinuierlichen Fall, nicht-Fourier-Bedingungen zu verwenden (leite einfach das Protokoll (snr) durch ein MLP mit optionalen Layernorms), da ich das lokal am Laufen habe
gelernte Varianz entfernt
Fügen Sie die p2-Verlustgewichtung für kontinuierliche Zeit hinzu
Stellen Sie sicher, dass kaskadierendes ddpm ohne Textbedingung trainiert werden kann, und stellen Sie sicher, dass sowohl die kontinuierliche als auch die zeitdiskrete Gaußsche Diffusion funktioniert
Verwenden Sie die Tiefenkonvektionen des Primers für die qkv-Projektionen in linearer Aufmerksamkeit (oder verwenden Sie Token-Shifting vor Projektionen) – verwenden Sie auch den neuen Dropout, der von Bayesformer vorgeschlagen wurde, da er mit linearer Aufmerksamkeit gut zu funktionieren scheint
Entdecken Sie die Skip-Layer-Anregung im Unet-Decoder
Beschleunigung der Integration
Erstellen Sie ein CLI-Tool und eine einzeilige Bildgenerierung
Beseitigen Sie alle Probleme, die durch die Beschleunigung entstanden sind
Fügen Sie die Inpainting-Funktion mithilfe des Resamplers aus dem Repaint-Papier https://arxiv.org/abs/2201.09865 hinzu
Erstellen Sie ein einfaches Checkpointing-System, das von einem Ordner unterstützt wird
Fügen Sie eine Sprungverbindung von den Ausgängen aller Upsample-Blöcke hinzu, die in Unet-Karos und einigen früheren Unet-Werken verwendet wird
Fügen Sie fsspec hinzu, empfohlen von Romain @rom1504, für cloud-/lokales Dateisystem-unabhängige Persistenz von Prüfpunkten
Testen Sie die Persistenz in gcs mit https://github.com/fsspec/gcsfs
Erweitern Sie die Videogenerierung unter Verwendung axialer Zeitaufmerksamkeit, wie in Hos Video-ddpm-Artikel
Ermöglichen Sie die Verallgemeinerung erläuterter Bilder auf jede beliebige Form
Ermöglichen Sie die Verallgemeinerung von Bildern auf jede beliebige Form
Fügen Sie eine dynamische Positionsverzerrung hinzu, um die beste Art der Längenextrapolation über die Videozeit zu erzielen
Verschieben Sie Videobilder in die Sample-Funktion, da wir eine Zeitextrapolation versuchen werden
Die Aufmerksamkeitsverzerrung gegenüber Nullschlüsseln/-werten sollte ein erlernter Skalar der Kopfdimension sein
Fügen Sie die Selbstkonditionierung aus Bitdiffusionspapier hinzu, die bereits bei ddpm-pytorch codiert ist
Fügen Sie die V-Parametrisierung (https://arxiv.org/abs/2202.00512) aus dem Imagen-Videopapier hinzu, das einzige, was neu ist
Integrieren Sie alle Erkenntnisse aus make-a-video (https://makeavideo.studio/)
Erstellen Sie ein CLI-Tool für das Training und setzen Sie das Training außerhalb der Konfigurationsdatei fort
ermöglichen eine zeitliche Interpolation in bestimmten Phasen
Stellen Sie sicher, dass die zeitliche Interpolation beim Inpainting funktioniert
Stellen Sie sicher, dass alle Interpolationsmodi angepasst werden können (einige Forscher erzielen mit trilinear bessere Ergebnisse).
imagen-video: Ermöglicht die Konditionierung vorhergehender (und möglicherweise zukünftiger) Frames von Videos. In diesem Szenario sollte keine Zeit zum Ignorieren zulässig sein
Stellen Sie sicher, dass das zeitliche Down-/Upsampling zur Konditionierung von Videobildern automatisch erfolgt, aber lassen Sie eine Option zum Ausschalten zu
Stellen Sie sicher, dass Inpainting mit Video funktioniert
Stellen Sie sicher, dass die Inpainting-Maske für Videos pro Frame angepasst werden kann
Fügen Sie grelle Aufmerksamkeit hinzu
Lesen Sie cogvideo noch einmal und finden Sie heraus, wie die Bildratenkonditionierung verwendet werden kann
Bringen Sie Aufmerksamkeitsexpertise für Selbstaufmerksamkeitsebenen in unet3d ein
Erwägen Sie die Einbeziehung der 3D-Faltungsaufmerksamkeit von NUWA
Betrachten Sie Transformer-XL-Erinnerungen in den zeitlichen Aufmerksamkeitsblöcken
Betrachten Sie den Wahrnehmer-Ansatz, um sich um die vergangene Zeit zu kümmern
Frame-Aussetzer während der Aufmerksamkeit, um sowohl einen regulierenden Effekt als auch eine verkürzte Trainingszeit zu erzielen
Untersuchen Sie die Behauptungen von Frank Wood https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch und fügen Sie entweder die hierarchische Stichprobentechnik hinzu oder informieren Sie die Leute über ihre Mängel
Bieten Sie herausfordernde Bewegungssimulationen (mit Ablenkungsobjekten) als einzeilige, trainierbare Basislinie für Forscher, von der aus Text in Video umgewandelt werden kann
Vorkodierung von Text für gespeicherte Einbettungen
Sie können Dataloader-Iteratoren basierend auf dem alten Epochenstil erstellen und auch Shuffling usw. konfigurieren
in der Lage sein, auch Argumente zu übergeben (anstatt alle Schlüsselwortargumente im Modell weiterleiten zu müssen)
Bringen Sie umkehrbare Blöcke von Revnets für 3D Unet ein, um die Speicherbelastung zu verringern
Fügen Sie die Möglichkeit hinzu, nur Super-Resolution-Netzwerke zu trainieren
Lesen Sie den DPM-Löser und prüfen Sie, ob er auf die zeitkontinuierliche Gaußsche Diffusion anwendbar ist
ermöglichen die Konditionierung von Videobildern mit beliebigen absoluten Zeiten (Berechnung des RPE während der zeitlichen Aufmerksamkeit)
ermöglichen die Feinabstimmung Ihrer Traumkabine
Textumkehr hinzufügen
Bereinigung der Selbstkonditionierung, die bei der Bildinstanziierung extrahiert werden soll
Stellen Sie sicher, dass Dreambooth mit Imagen-Video funktioniert
Fügen Sie eine Frameratenkonditionierung für die Videoverbreitung hinzu
Stellen Sie sicher, dass Sie als Eingabeaufforderung gleichzeitig Videobilder und ein Bild über alle Bilder hinweg konditionieren können
Testen und Hinzufügen von Destillationstechniken anhand von Konsistenzmodellen
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

