PaLM rlhf pytorch
0.3.9
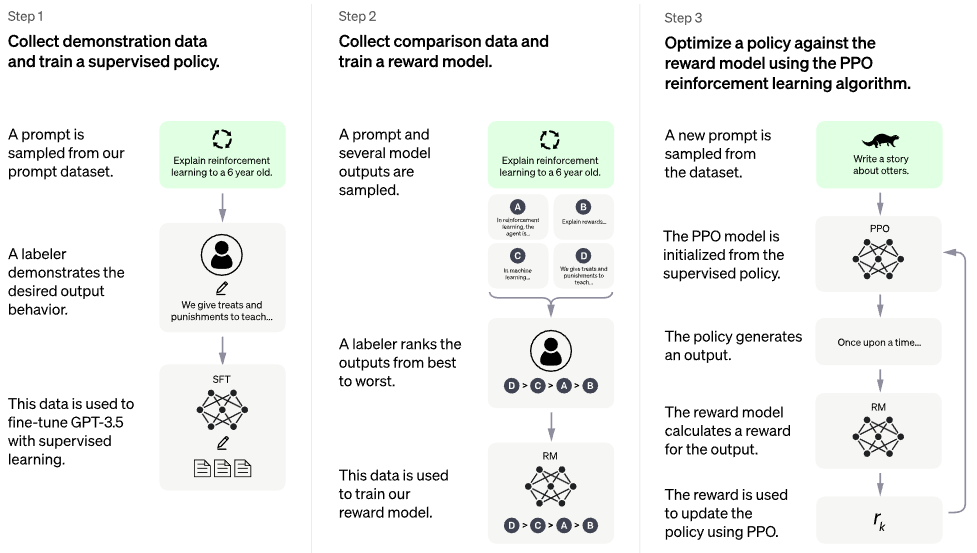
Offizieller Chatgpt-Blogpost
Implementierung von RLHF (Reinforcement Learning with Human Feedback) auf der PaLM-Architektur. Vielleicht füge ich auch eine Abruffunktion à la RETRO hinzu
Wenn Sie daran interessiert sind, etwas wie ChatGPT öffentlich zu reproduzieren, denken Sie bitte darüber nach, sich Laion anzuschließen
Möglicher Nachfolger: Direct Preference Optimization – der gesamte Code in diesem Repo wird zu ~ binärem Kreuzentropieverlust, < 5 loc. Soviel zu Reward-Modellen und PPO
Es gibt kein trainiertes Modell. Dies ist nur das Schiff und die Gesamtkarte. Wir benötigen immer noch Millionen von Dollar an Rechenleistung und Daten, um zum richtigen Punkt im hochdimensionalen Parameterraum zu gelangen. Selbst dann braucht man professionelle Segler (wie Robin Rombach von Stable Diffusion), die das Schiff tatsächlich durch turbulente Zeiten bis zu diesem Punkt führen.
CarperAI hatte vor der Veröffentlichung von ChatGPT viele Monate lang an einem RLHF-Framework für große Sprachmodelle gearbeitet.
Yannic Kilcher arbeitet ebenfalls an einer Open-Source-Implementierung
KI-Kaffeepause mit Letitia | Code Emporium | Code Emporium Teil 2
Stability.ai für das großzügige Sponsoring für die Arbeit an der Spitzenforschung im Bereich der künstlichen Intelligenz
? Hugging Face und CarperAI für das Verfassen des Blog-Beitrags „Illustrated Reinforcement Learning from Human Feedback“ (RLHF) und Ersteres auch für ihre Beschleunigungsbibliothek
@kisseternity und @taynoel84 für die Codeüberprüfung und das Finden von Fehlern
Enrico für die Integration von Flash Attention aus Pytorch 2.0
$ pip install palm-rlhf-pytorch Trainieren Sie zunächst PaLM wie jeden anderen autoregressiven Transformator
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) Trainieren Sie dann Ihr Belohnungsmodell mit dem kuratierten menschlichen Feedback. In der Originalarbeit konnten sie keine Feinabstimmung des Belohnungsmodells von einem vorab trainierten Transformator ohne Überanpassung erhalten, aber ich habe trotzdem die Option zur Feinabstimmung mit LoRA gegeben, da es sich noch um offene Forschung handelt.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) Anschließend übergibst du deinen Transformator und das Belohnungsmodell an den RLHFTrainer
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) Klon-Basistransformator mit separater Lora für Kritiker
ermöglichen auch eine nicht auf LoRA basierende Feinabstimmung
Führen Sie die Normalisierung erneut durch, um eine maskierte Version zu erhalten. Es ist nicht sicher, ob jemals jemand Belohnungen/Werte pro Token verwenden wird, aber eine gute Vorgehensweise bei der Implementierung
mit der besten Aufmerksamkeit ausstatten
Fügen Sie Hugging Face hinzu, beschleunigen Sie und testen Sie die Wandb-Instrumentierung
Durchsuchen Sie die Literatur, um herauszufinden, was das neueste SOTA für PPO ist, vorausgesetzt, der RL-Bereich macht noch Fortschritte.
Testen Sie das System mit einem vorab trainierten Sentiment-Netzwerk als Belohnungsmodell
Schreiben Sie den Speicher in PPO in eine gespeicherte Numpy-Datei
Sorgen Sie dafür, dass die Probenahme mit Eingabeaufforderungen variabler Länge funktioniert, auch wenn dies nicht erforderlich ist, da der Engpass menschliches Feedback darstellt
Ermöglichen Sie die Feinabstimmung der vorletzten N-Schichten nur im Akteur oder im Kritiker, vorausgesetzt, sie sind vorab trainiert
Integrieren Sie einige Lernpunkte von Sparrow anhand von Letitias Video
Einfache Weboberfläche mit Django + Htmx zum Sammeln von menschlichem Feedback
Betrachten Sie RLAIF
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

