make a video pytorch
0.4.0
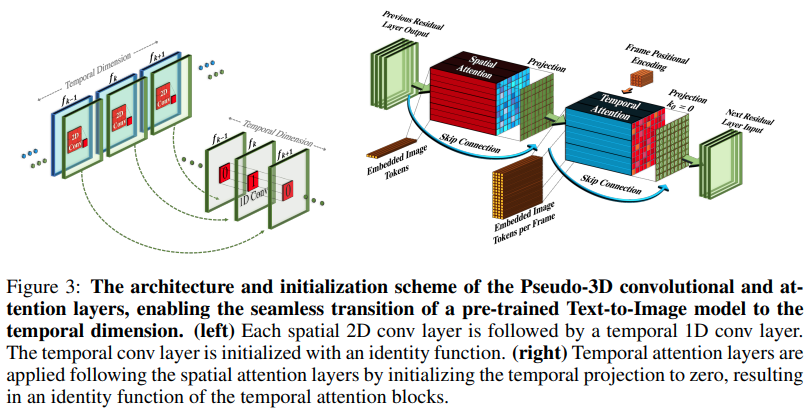
Implementierung von Make-A-Video, dem neuen SOTA-Text-zu-Video-Generator von Meta AI, in Pytorch. Sie kombinieren Pseudo-3D-Faltungen (axiale Faltungen) und zeitliche Aufmerksamkeit und zeigen eine viel bessere zeitliche Fusion.
Die Pseudo-3D-Faltungen sind kein neues Konzept. Es wurde bereits in anderen Zusammenhängen untersucht, beispielsweise zur Vorhersage von Proteinkontakten als „dimensionale hybride Restnetzwerke“.
Der Kern des Artikels besteht darin, ein SOTA-Text-zu-Bild-Modell zu nehmen (hier wird DALL-E2 verwendet, aber die gleichen Lernpunkte würden problemlos auf Imagen anwendbar sein), ein paar kleinere Änderungen vorzunehmen, um die Aufmerksamkeit im Laufe der Zeit zu wahren und auf andere Weise Um die Rechenkosten zu sparen, führen Sie die Frame-Interpolation korrekt durch und erhalten Sie ein großartiges Videomodell.
Erklärung zur KI-Kaffeepause
Stability.ai für das großzügige Sponsoring für die Arbeit an der Spitzenforschung im Bereich der künstlichen Intelligenz
Jonathan Ho, der durch seine bahnbrechende Arbeit eine Revolution in der generativen künstlichen Intelligenz herbeigeführt hat
Alex für Einops, eine Abstraktion, die einfach genial ist. Kein anderes Wort dafür.
$ pip install make-a-video-pytorchWeitergabe von Videofunktionen
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)Beim Übergeben von Bildern (wenn man die Bilder zuerst vorab trainieren würde) werden sowohl die zeitliche Faltung als auch die Aufmerksamkeit automatisch übersprungen. Mit anderen Worten: Sie können dies direkt in Ihrem 2D-Unet verwenden und es dann auf ein 3D-Unet portieren, sobald diese Phase des Trainings abgeschlossen ist. Die zeitlichen Module werden initialisiert, um die Identität auszugeben, wie es in der Arbeit getan wurde.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)Sie können die beiden Module auch so steuern, dass bei der Eingabe dreidimensionaler Merkmale nur räumlich trainiert wird
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) Vollständiges SpaceTimeUnet , das unabhängig von Bild- oder Videotraining ist und bei dem selbst bei der Weitergabe von Video die Zeit ignoriert werden kann
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )Achten Sie auf das Beste, was die Forschung zu Positionseinbettungen zu bieten hat
erhöhen Sie die Aufmerksamkeit
Fügen Sie grelle Aufmerksamkeit hinzu
Stellen Sie sicher, dass dalle2-pytorch SpaceTimeUnet für das Training akzeptieren kann
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

