atari
1.0.0

Forschungsspielplatz, der auf dem Atari Gym von OpenAI basiert und für die Implementierung verschiedener Reinforcement-Learning-Algorithmen vorbereitet ist.
Es kann jedes der folgenden Spiele emulieren:
['Asterix', 'Asteroids', 'MsPacman', 'Kaboom', 'BankHeist', 'Kangaroo', 'Skiing', 'FishingDerby', 'Krull', 'Berzerk', 'Tutankham', 'Zaxxon', ' Venture“, „Riverraid“, „Centipede“, „Adventure“, „BeamRider“, „CrazyClimber“, „TimePilot“, „Carnival“, „Tennis“, „Seaquest“, „Bowling“, „SpaceInvaders“, „Freeway“, „YarsRevenge“, „RoadRunner“, „JourneyEscape“, „WizardOfWor“, „Gopher“. ', 'Breakout', 'StarGunner', 'Atlantis', 'DoubleDunk', „Hero“, „BattleZone“, „Solaris“, „UpNDown“, „Frostbite“, „KungFuMaster“, „Pooyan“, „Pitfall“, „MontezumaRevenge“, „PrivateEye“, „AirRaid“, „Amidar“, „Robotank“. ', 'DemonAttack', 'Defender', 'NameThisGame', 'Phoenix', „Gravitar“, „ElevatorAction“, „Pong“, „VideoPinball“, „IceHockey“, „Boxing“, „Assault“, „Alien“, „Qbert“, „Enduro“, „ChopperCommand“, „Jamesbond“]
Schauen Sie sich den entsprechenden Medium-Artikel an: Atari – Reinforcement Learning im Detail? (Teil 1: DDQN)
Das ultimative Ziel dieses Projekts ist die Implementierung und der Vergleich verschiedener RL-Ansätze mit Atari-Spielen als gemeinsamem Nenner.
pip install -r requirements.txt .python atari.py --help anzuzeigen. * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
Deep Convolutional Neural Network von DeepMind
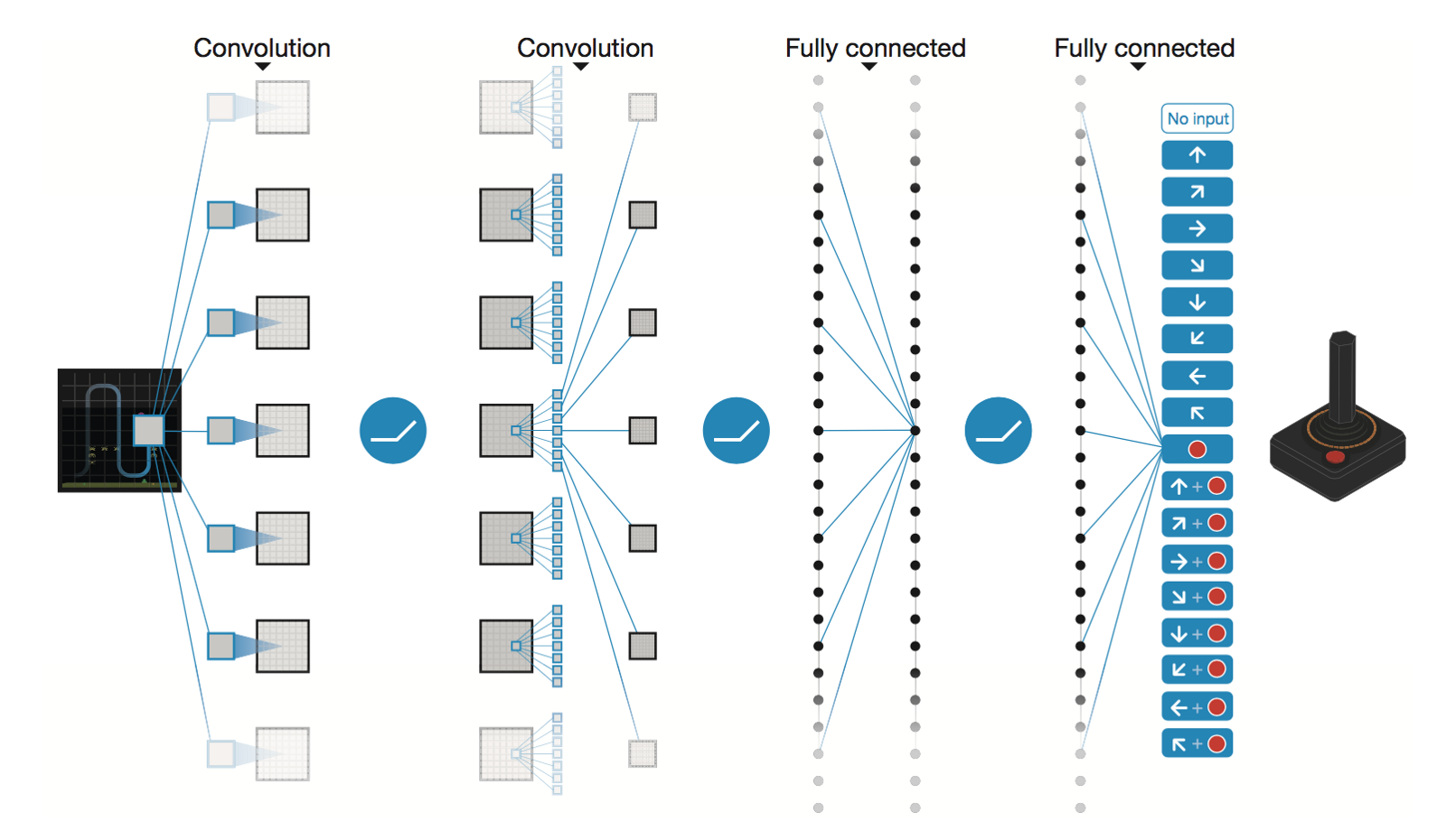
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
Nach 5 Millionen Schritten ( ~40 Stunden auf der Tesla K80-GPU oder ~90 Stunden auf der 2,9-GHz-Intel-i7-Quad-Core-CPU):
Ausbildung:
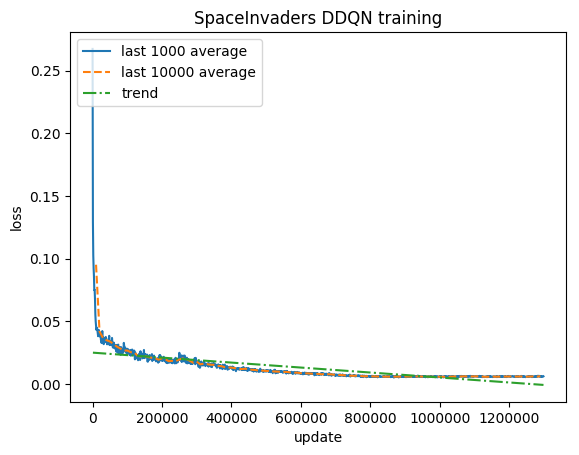
Normalisierte Punktzahl – jede Belohnung wird auf (-1, 1) gekürzt
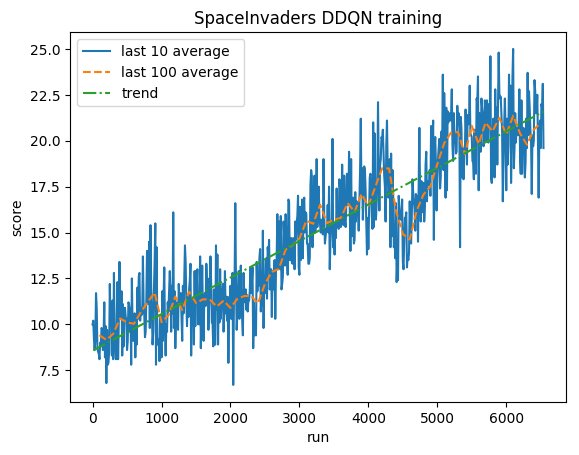
Testen:
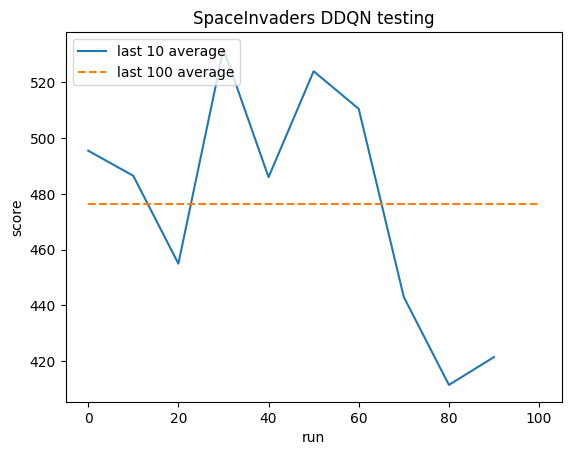
Menschlicher Durchschnitt: ~372
DDQN-Durchschnitt: ~479 (128 %)
Ausbildung:
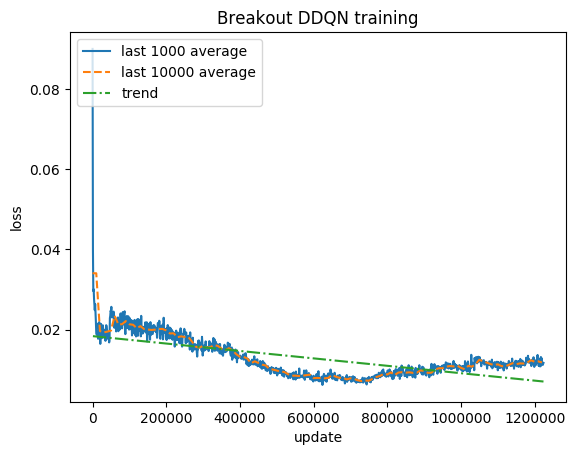
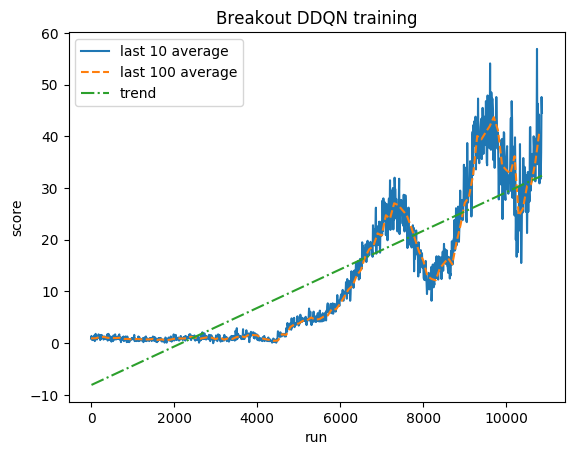
Normalisierte Punktzahl – jede Belohnung wird auf (-1, 1) gekürzt
Testen:
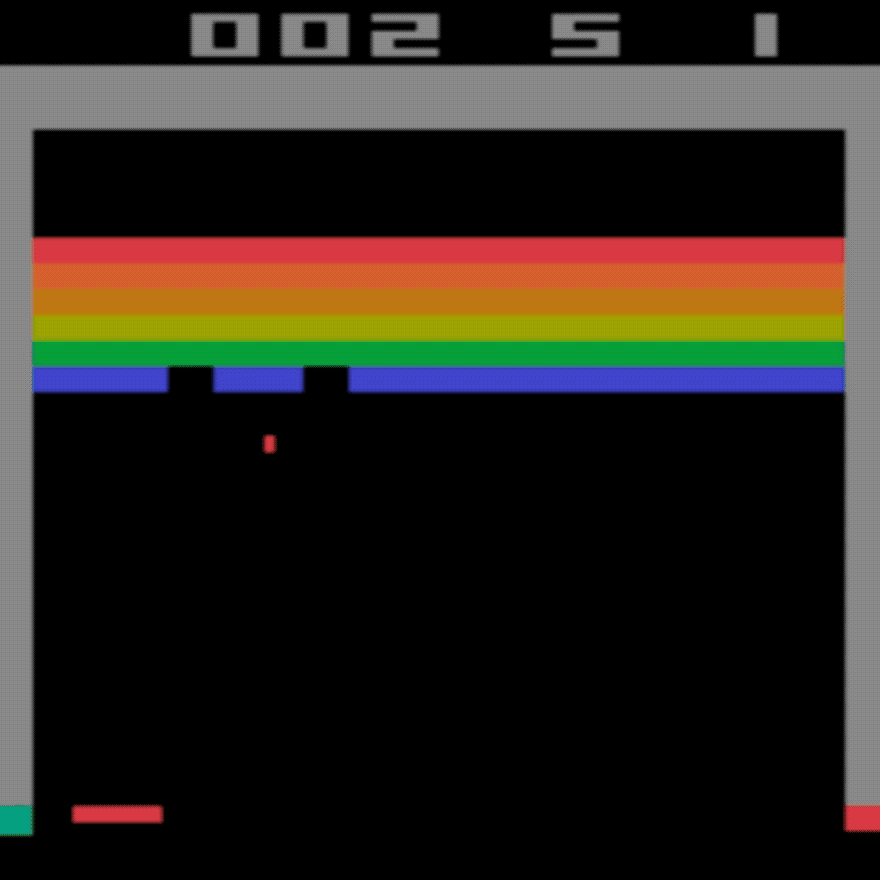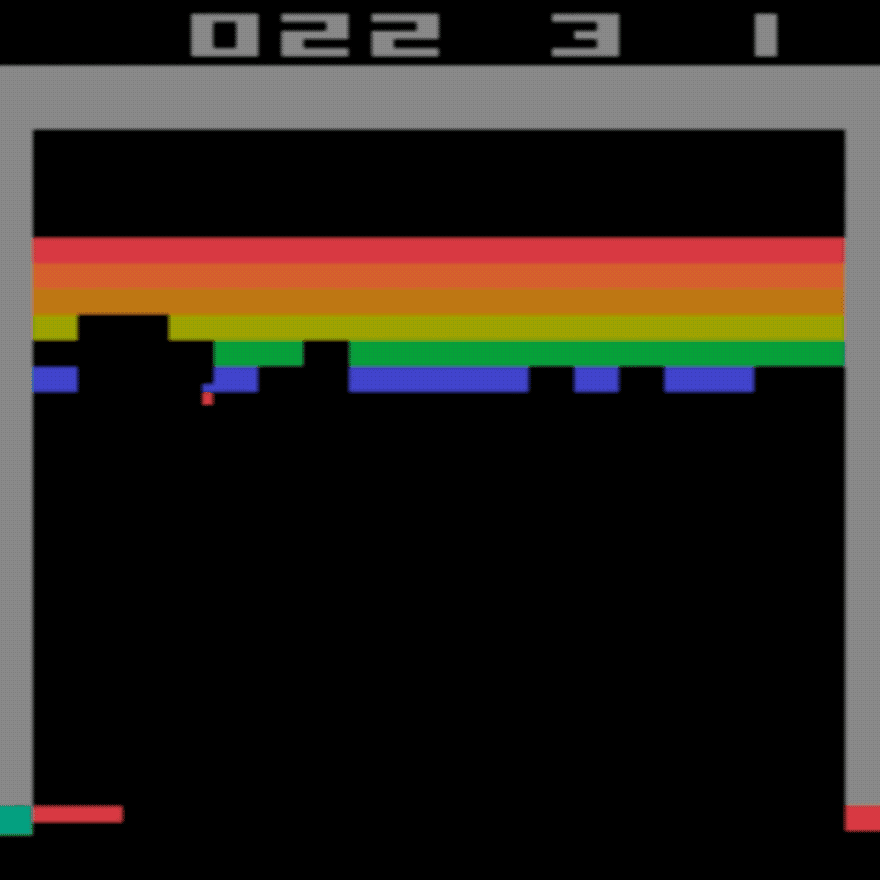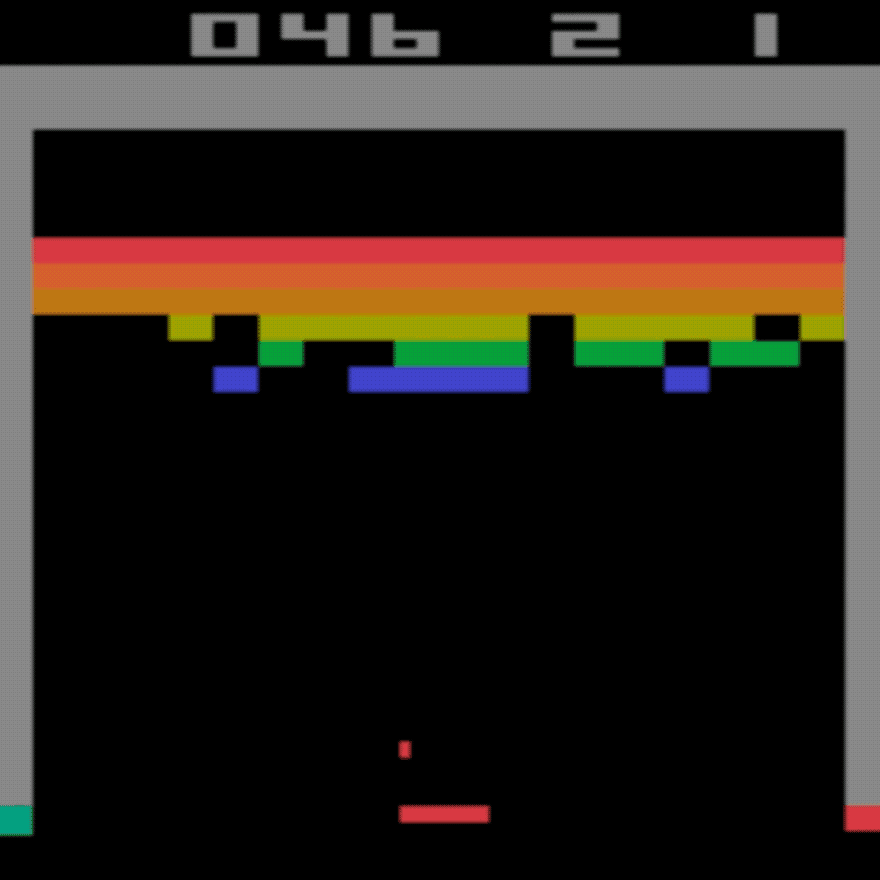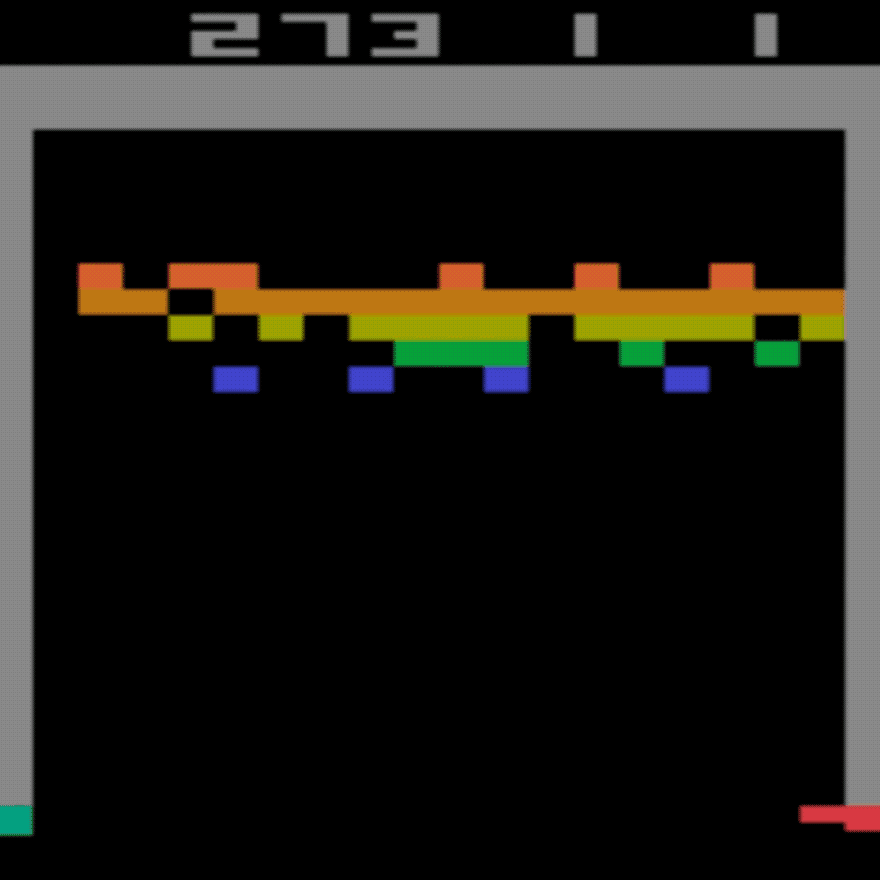
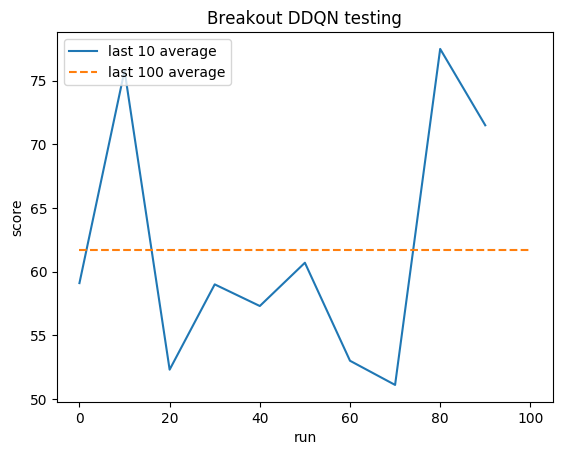
Menschlicher Durchschnitt: ~28
DDQN-Durchschnitt: ~62 (221 %)
Ausbildung:
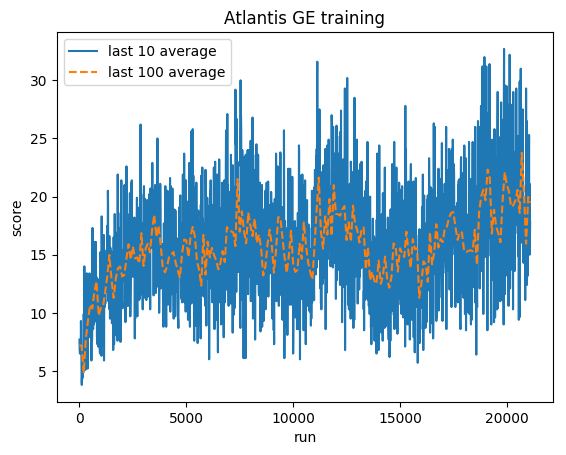
Normalisierte Punktzahl – jede Belohnung wird auf (-1, 1) gekürzt
Testen:

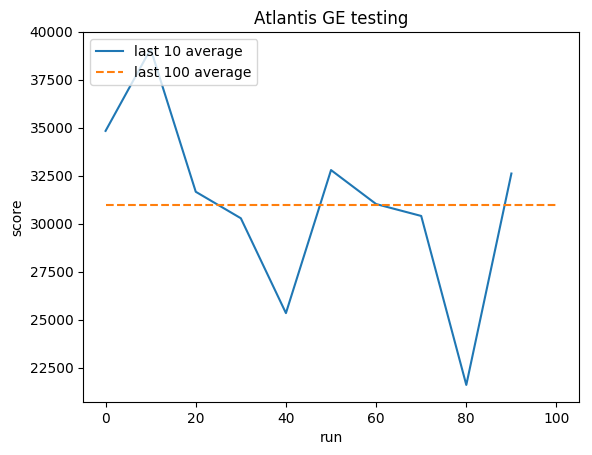
Menschlicher Durchschnitt: ~29.000
GE-Durchschnitt: 31.000 (106 %)
Greg (Grzegorz) Surma
PORTFOLIO
GITHUB
BLOG


