LongNet
0.4.8

Dies ist eine Open-Source-Implementierung für den Artikel LongNet: Scaling Transformers to 1.000.000.000 Tokens von Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei. Das LongNet ist eine Transformer-Variante, die entwickelt wurde, um die Sequenzlänge auf mehr als 1 Milliarde Token zu skalieren, ohne die Leistung bei kürzeren Sequenzen zu beeinträchtigen.
pip install longnet Sobald Sie LongNet installiert haben, können Sie die DilatedAttention -Klasse wie folgt verwenden:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerEin vollständig lernbereites Transformatormodell mit erweiterten Transformatorblöcken mit Feedforwards mit Layernorm, SWIGLU und einem parallelen Transformatorblock
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
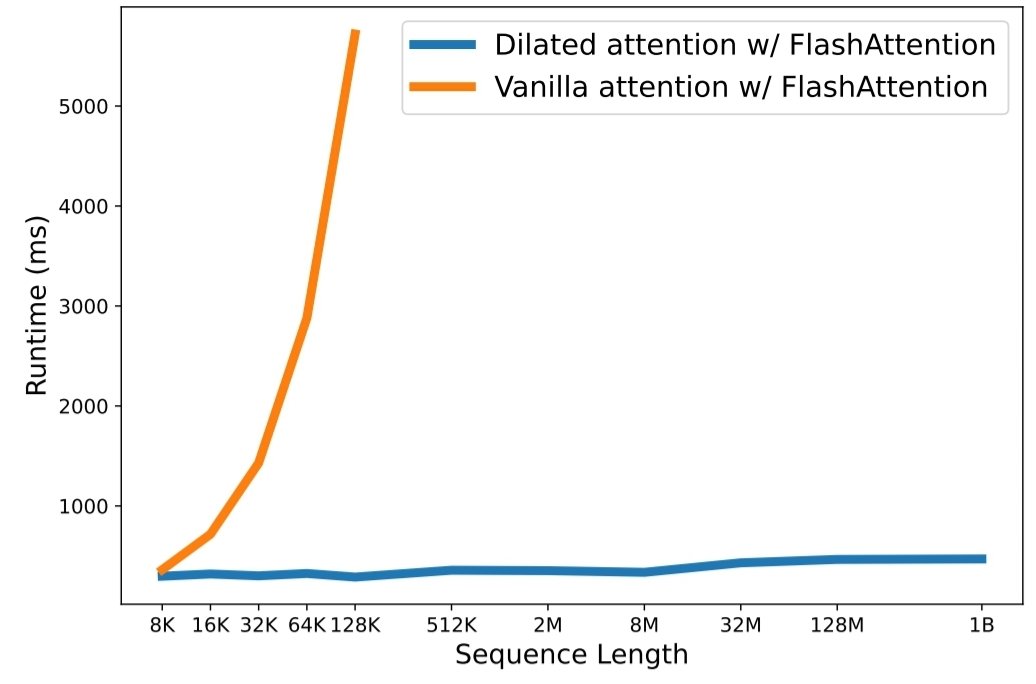
python3 train.py aus Die Skalierung der Sequenzlänge ist im Zeitalter großer Sprachmodelle zu einem kritischen Engpass geworden. Bestehende Methoden haben jedoch Probleme mit der Rechenkomplexität oder der Modellausdruckskraft, wodurch die maximale Sequenzlänge eingeschränkt ist. In diesem Artikel stellen sie LongNet vor, eine Transformer-Variante, die die Sequenzlänge auf mehr als 1 Milliarde Token skalieren kann, ohne die Leistung bei kürzeren Sequenzen zu beeinträchtigen. Konkret schlagen sie eine erweiterte Aufmerksamkeit vor, die das Aufmerksamkeitsfeld mit zunehmender Entfernung exponentiell erweitert.
LongNet hat wesentliche Vorteile:
Die Versuchsergebnisse zeigen, dass LongNet sowohl bei der Modellierung langer Sequenzen als auch bei allgemeinen Sprachaufgaben eine starke Leistung erbringt. Ihre Arbeit eröffnet neue Möglichkeiten zur Modellierung sehr langer Sequenzen, beispielsweise die Behandlung eines gesamten Korpus oder sogar des gesamten Internets als Sequenz.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

