adeptRL
1.0.0
adept ist ein Framework für Reinforcement Learning, das die Forschung durch die Abstrahierung technischer Herausforderungen, die mit Deep Reinforcement Learning verbunden sind, beschleunigen soll. Adept bietet:
Bei diesem Code handelt es sich um einen Early-Access-Code. Erwarten Sie einige Ecken und Kanten. Schnittstellenänderungen vorbehalten. Wir freuen uns über Feedback und Beiträge.
git clone https://github.com/heronsystems/adeptRL
cd adeptRL
pip install -e .[all]Von Docker:
Trainieren Sie einen Agenten . Protokolle gehen standardmäßig zu /tmp/adept_logs/ . Das Protokollverzeichnis enthält die Tensorboard-Datei, gespeicherte Modelle und andere Metadaten.
# Local Mode (A2C)
# We recommend 4GB+ GPU memory, 8GB+ RAM, 4+ Cores
python -m adept.app local --env BeamRiderNoFrameskip-v4
# Distributed Mode (A2C, requires NCCL)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app distrib --env BeamRiderNoFrameskip-v4
# IMPALA (requires ray, resource intensive)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app actorlearner --env BeamRiderNoFrameskip-v4
# To see a full list of options:
python -m adept.app -h
python -m adept.app help < command >Verwenden Sie Ihren eigenen Agenten, Ihre eigene Umgebung, Ihr eigenes Netzwerk oder Ihr eigenes Submodul
"""
my_script.py
Train an agent on a single GPU.
"""
from adept . scripts . local import parse_args , main
from adept . network import NetworkModule , SubModule1D
from adept . agent import AgentModule
from adept . env import EnvModule
class MyAgent ( AgentModule ):
pass # Implement
class MyEnv ( EnvModule ):
pass # Implement
class MyNet ( NetworkModule ):
pass # Implement
class MySubModule1D ( SubModule1D ):
pass # Implement
if __name__ == '__main__' :
import adept
adept . register_agent ( MyAgent )
adept . register_env ( MyEnv )
adept . register_network ( MyNet )
adept . register_submodule ( MySubModule1D )
main ( parse_args ())python my_script.py --agent MyAgent --env env-id-1 --custom-network MyNetLokal (Einzelknoten, Einzel-GPU)
Verteilt (Multi-Knoten, Multi-GPU)
Wichtigkeitsgewichtete Akteur-Lerner-Architekturen, IMPALA (Einzelknoten, Multi-GPU)
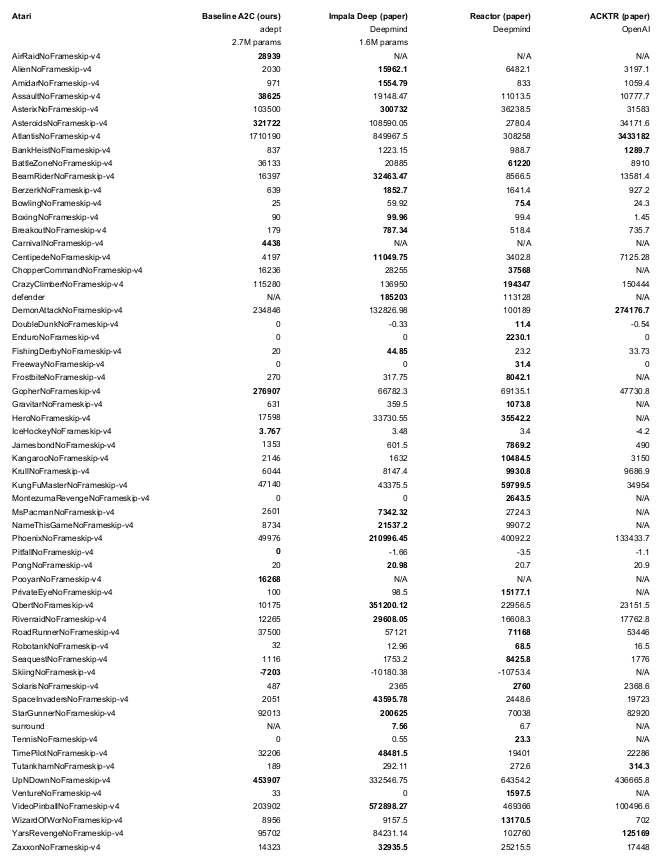
python -m adept.app local --logdir ~/local64_benchmark --eval -y --nb-step 50e6 --env <env-id> Wir leihen uns Teile des Gym- und Baselines-Codes von OpenAI aus. Wir geben an, wo dies geschieht.


