L2C
1.0.0
Eine Clustering-Strategie mit tiefen neuronalen Netzen. Dieser Blogartikel bietet einen allgemeinen Überblick.
Dieses Repository stellt die PyTorch-Implementierung der Transfer-Lernschemata (L2C) und zwei Lernkriterien bereit, die für Deep Clustering nützlich sind:
*Es wird von CCL umbenannt
Dieses Repository umfasst folgende Referenzen:
@inproceedings{Hsu19_MCL,
title = {Multi-class classification without multi-class labels},
author = {Yen-Chang Hsu, Zhaoyang Lv, Joel Schlosser, Phillip Odom, Zsolt Kira},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2019},
url = {https://openreview.net/forum?id=SJzR2iRcK7}
}
@inproceedings{Hsu18_L2C,
title = {Learning to cluster in order to transfer across domains and tasks},
author = {Yen-Chang Hsu and Zhaoyang Lv and Zsolt Kira},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2018},
url = {https://openreview.net/forum?id=ByRWCqvT-}
}
@inproceedings{Hsu16_KCL,
title = {Neural network-based clustering using pairwise constraints},
author = {Yen-Chang Hsu and Zsolt Kira},
booktitle = {ICLR workshop},
year = {2016},
url = {https://arxiv.org/abs/1511.06321}
}
Dieses Repository unterstützt PyTorch 1.0, Python 2.7, 3.6 und 3.7.
pip install -r requirements.txt # A quick trial:
python demo.py # Default Dataset:MNIST, Network:LeNet, Loss:MCL
python demo.py --loss KCL
# Lookup available options:
python demo.py -h
# For more examples:
./scripts/exp_supervised_MCL_vs_KCL.sh # Learn the Similarity Prediction Network (SPN) with Omniglot_background and then transfer to the 20 alphabets in Omniglot_evaluation.
# Default loss is MCL with an unknown number of clusters (Set a large cluster number, i.e., k=100)
# It takes about half an hour to finish.
python demo_omniglot_transfer.py
# An example of using KCL and set k=gt_#cluster
python demo_omniglot_transfer.py --loss KCL --num_cluster -1
# Lookup available options:
python demo_omniglot_transfer.py -h
# Other examples:
./scripts/exp_unsupervised_transfer_Omniglot.sh| Datensatz | gt #Klasse | KCL (k=100) | MCL (k=100) | KCL (k=gt) | MCL (k=gt) |
|---|---|---|---|---|---|
| Engelhaft | 20 | 73,2 % | 82,2 % | 89,0 % | 91,7 % |
| Atemayar_Qelisayer | 26 | 73,3 % | 89,2 % | 82,5 % | 86,0 % |
| Atlantisch | 26 | 65,5 % | 83,3 % | 89,4 % | 93,5 % |
| Aurek_Besh | 26 | 88,4 % | 92,8 % | 91,5 % | 92,4 % |
| Avesta | 26 | 79,0 % | 85,8 % | 85,4 % | 86,1 % |
| Meine Güte | 26 | 77,1 % | 84,0 % | 85,4 % | 86,6 % |
| Glagolitisch | 45 | 83,9 % | 85,3 % | 84,9 % | 87,4 % |
| Gurmukhi | 45 | 78,8 % | 78,7 % | 77,0 % | 78,0 % |
| Kannada | 41 | 64,6 % | 81,1 % | 73,3 % | 81,2 % |
| Keble | 26 | 91,4 % | 95,1 % | 94,7 % | 94,3 % |
| Malayalam | 47 | 73,5 % | 75,0 % | 72,7 % | 73,0 % |
| Manipuri | 40 | 82,8 % | 81,2 % | 85,8 % | 81,5 % |
| mongolisch | 30 | 84,7 % | 89,0 % | 88,3 % | 90,2 % |
| Old_Church_Slavonic_Cyrillic | 45 | 89,9 % | 90,7 % | 88,7 % | 89,8 % |
| Oriya | 46 | 56,5 % | 73,4 % | 63,2 % | 75,3 % |
| Sylheti | 28 | 61,8 % | 68,2 % | 69,8 % | 80,6 % |
| Syrisch_Serto | 23 | 72,1 % | 82,0 % | 85,8 % | 89,8 % |
| Tengwar | 25 | 67,7 % | 76,4 % | 82,5 % | 85,5 % |
| Tibetisch | 42 | 81,8 % | 80,2 % | 84,3 % | 81,9 % |
| ULOG | 26 | 53,3 % | 77,1 % | 73,0 % | 89,1 % |
| --Durchschnitt-- | 75,0 % | 82,5 % | 82,4 % | 85,7 % |
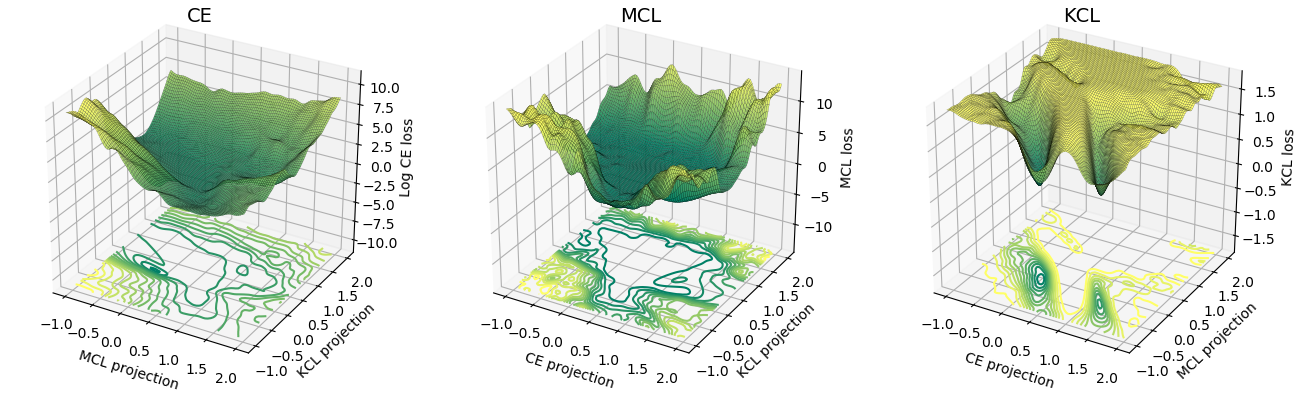
Die Verlustoberfläche von MCL ähnelt eher der Kreuzentropie (CE) als von KCL. Empirisch gesehen konvergierte MCL schneller als KCL. Einzelheiten finden Sie im ICLR-Papier.
@article{Hsu18_InsSeg,
title = {Learning to Cluster for Proposal-Free Instance Segmentation},
author = {Yen-Chang Hsu, Zheng Xu, Zsolt Kira, Jiawei Huang},
booktitle = {accepted to the International Joint Conference on Neural Networks (IJCNN)},
year = {2018},
url = {https://arxiv.org/abs/1803.06459}
}
Diese Arbeit wurde von der National Science Foundation und der National Robotics Initiative (Zuschuss Nr. IIS-1426998) und dem Lifelong Learning Machines (L2M)-Programm der DARPA im Rahmen der Kooperationsvereinbarung HR0011-18-2-001 unterstützt.


