soundstorm pytorch
0.5.0
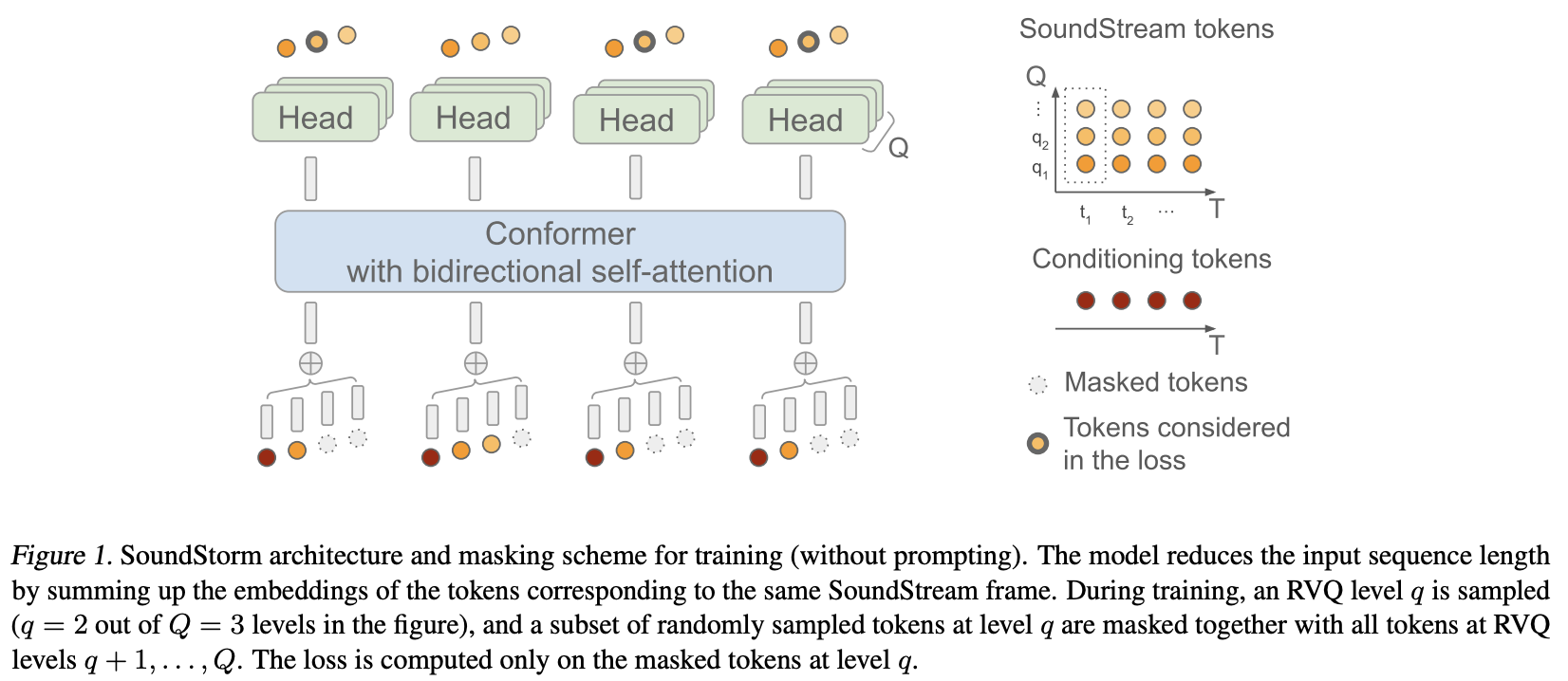
Implementierung von SoundStorm, Efficient Parallel Audio Generation von Google Deepmind, in Pytorch.
Sie haben MaskGiT grundsätzlich auf die restlichen vektorquantisierten Codes von Soundstream angewendet. Die von ihnen gewählte Transformatorarchitektur passt gut zur Audiodomäne und heißt Conformer
Projektseite
Stabilität und ? Huggingface für die großzügigen Sponsorings und die Open-Source-Forschung im Bereich der künstlichen Intelligenz
Lucas Newman für zahlreiche Beiträge, einschließlich des anfänglichen Trainingscodes, der akustischen Eingabeaufforderungslogik und der Quantisierungsdekodierung pro Ebene!
? Accelerate bietet eine einfache und leistungsstarke Lösung für das Training
Einops für die unverzichtbare Abstraktion, die den Aufbau neuronaler Netze unterhaltsam, einfach und erhebend macht
Steven Hillis für die Einreichung der korrekten Maskierungsstrategie und die Überprüfung, ob das Repository funktioniert!
Lucas Newman dafür, dass er im Grunde genommen einen kleinen, funktionierenden Soundstorm mit Modellen aus mehreren Repositories trainiert und gezeigt hat, dass alles Ende-zu-Ende funktioniert. Zu den Modellen gehören SoundStream, Text-to-Semantic T5 und schließlich hier der SoundStorm-Transformator.
@Jiang-Stan für die Identifizierung eines kritischen Fehlers bei der iterativen Demaskierung!
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024) Um Rohaudio direkt zu trainieren, müssen Sie Ihren vorab trainierten SoundStream an SoundStorm übergeben. Sie können Ihren eigenen SoundStream bei audiolm-pytorch trainieren.
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above) Die vollständige Text-zu-Sprache-Umwandlung basiert auf einem trainierten TextToSemantic Encoder/Decoder-Transformator. Anschließend laden Sie die Gewichte und übergeben sie als spear_tts_text_to_semantic an SoundStorm
Dies ist noch in Arbeit, da bei spear-tts-pytorch nur die Modellarchitektur vollständig ist und nicht die Vortrainings-, Pseudo-Labeling- und Rückübersetzungslogik.
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream Soundstream integrieren
beim Generieren, und die Länge kann in Sekunden definiert werden (berücksichtigt die Abtastfrequenz usw.)
Stellen Sie sicher, dass gruppiertes RVQ unterstützt wird. Concat-Einbettungen statt Summierung über die Gruppendimension hinweg
Kopieren Sie einfach das Konformer und wiederholen Sie Shaws relative Positionseinbettung mit Rotationseinbettung. Niemand benutzt mehr Shaw.
Standardmäßige Flash-Aufmerksamkeit auf „true“.
Entfernen Sie Batchnorm und verwenden Sie einfach Layernorm, aber nach dem Swish (wie in Normformer-Papier)
Trainer mit Beschleunigung – danke an @lucasnewman
Ermöglichen Sie das Training und die Generierung von Sequenzen variabler Länge, indem Sie beim forward und generate mask übergeben
Option, um beim Generieren eine Liste der Audiodateien zurückzugeben
Verwandeln Sie es in ein Befehlszeilentool
Fügen Sie Queraufmerksamkeit und adaptive Layernorm-Konditionierung hinzu
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

