CenterSnap
1.0.0

Dieses Repository ist die Pytorch-Implementierung unseres Artikels: 
CenterSnap: Multi-Objekt-3D-Formrekonstruktion mit einer Aufnahme und kategoriale 6D-Posen- und Größenschätzung
Muhammad Zubair Irshad , Thomas Kollar, Michael Laskey, Kevin Stone, Zsolt Kira
Internationale Konferenz für Robotik und Automatisierung (ICRA), 2022
[Projektseite] [arXiv] [PDF] [Video] [Poster]
Folgearbeiten des ECCV'22:
ShAPO: Implizite Darstellungen für die Optimierung von Form, Aussehen und Pose mehrerer Objekte
Muhammad Zubair Irshad , Sergey Zakharov, Rares Ambrus, Thomas Kollar, Zsolt Kira, Adrien Gaidon
Europäische Konferenz für Computer Vision (ECCV), 2022
[Projektseite] [arXiv] [PDF] [Video] [Poster]

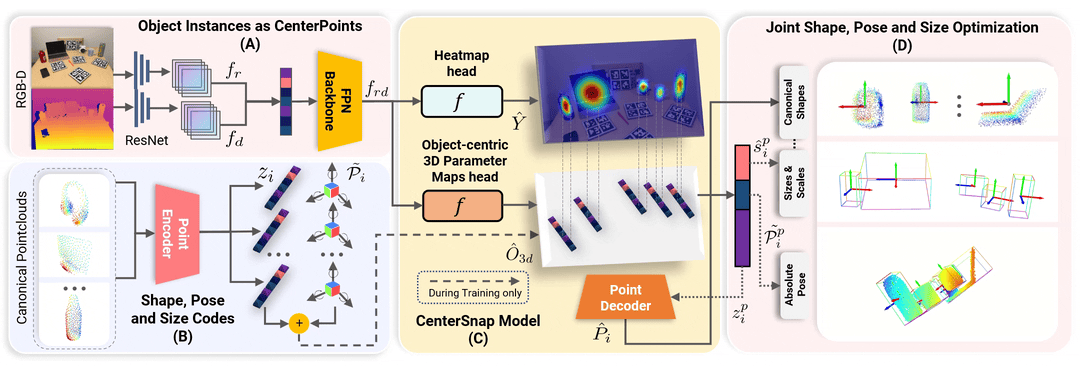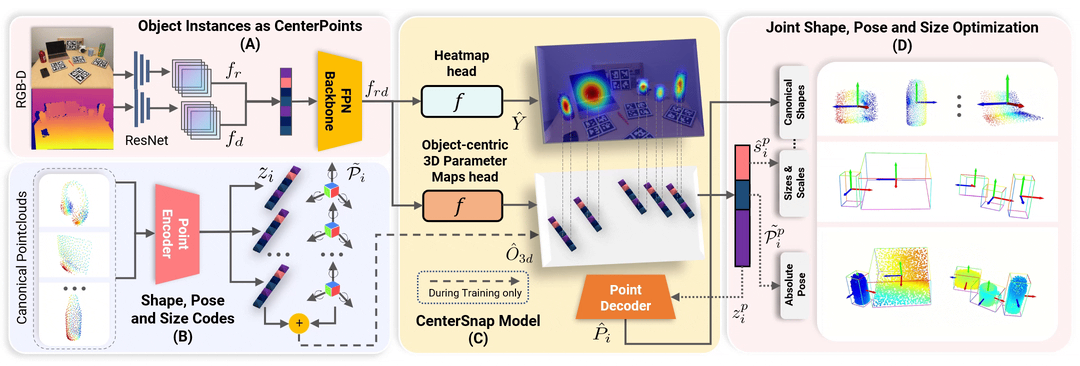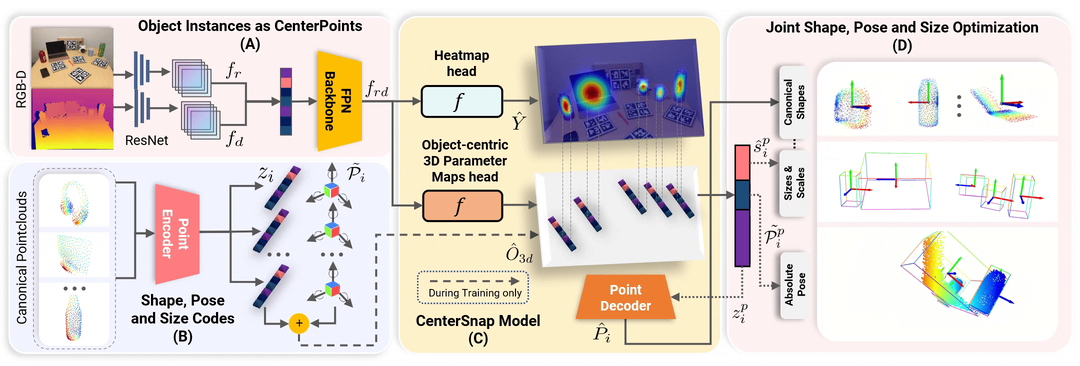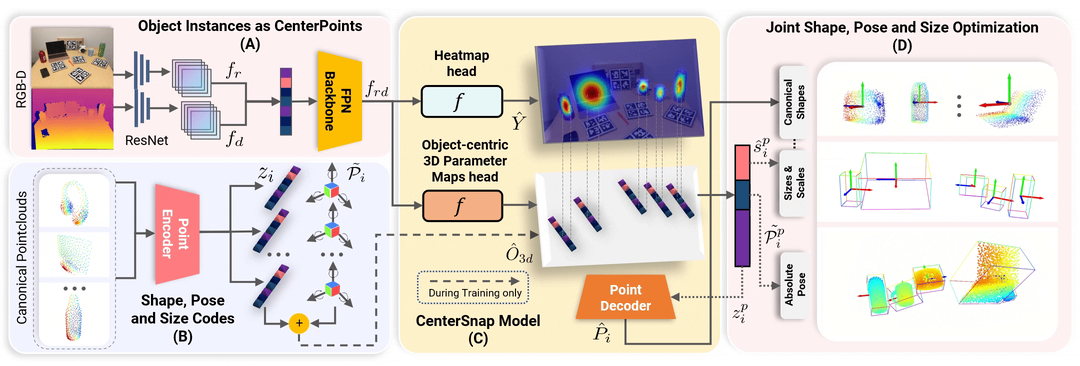
Wenn Sie dieses Repository nützlich finden, denken Sie bitte darüber nach, Folgendes zu zitieren:
@inproceedings{irshad2022centersnap,
title = {CenterSnap: Single-Shot Multi-Object 3D Shape Reconstruction and Categorical 6D Pose and Size Estimation},
author = {Muhammad Zubair Irshad and Thomas Kollar and Michael Laskey and Kevin Stone and Zsolt Kira},
journal = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2022}
}
@inproceedings{irshad2022shapo,
title = {ShAPO: Implicit Representations for Multi-Object Shape Appearance and Pose Optimization},
author = {Muhammad Zubair Irshad and Sergey Zakharov and Rares Ambrus and Thomas Kollar and Zsolt Kira and Adrien Gaidon},
journal = {European Conference on Computer Vision (ECCV)},
year = {2022}
}
Erstellen Sie eine virtuelle Python 3.8-Umgebung und installieren Sie die Anforderungen:
cd $CenterSnap_Repo
conda create -y --prefix ./env python=3.8
conda activate ./env/
./env/bin/python -m pip install --upgrade pip
./env/bin/python -m pip install -r requirements.txt Installieren Sie torch==1.7.1 torchvision==0.8.2 basierend auf Ihrer CUDA-Version. Der Code wurde auf cuda 10.2 erstellt und getestet. Ein Beispielbefehl zum Installieren von Torch auf Cuda 10.2 lautet wie folgt:
pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2Neues Update : Bitte schauen Sie sich das verteilte Skript unseres neuen ECCV'22-Werks ShAPO an, wenn Sie in ein paar Stunden Ihre eigenen Daten von Grund auf sammeln möchten. Dieses verteilte Skript sammelt die Daten im gleichen Format, wie es von CenterSnap benötigt wird, allerdings mit ein paar kleineren Änderungen, wie in diesem Repo erwähnt.
Wir empfehlen, den vorverarbeiteten Datensatz herunterzuladen, um das CenterSnap-Modell zu trainieren und zu bewerten. Laden Sie synthetische (868 GB) und echte (70 GB) Datensätze herunter und entpacken Sie sie. Diese Dateien enthalten alle Schulungen und Validierungen, die Sie zur Replikation unserer Ergebnisse benötigen.
cd $CenterSnap_REPO/data
wget https://tri-robotics-public.s3.amazonaws.com/centersnap/CAMERA.tar.gz
tar -xzvf CAMERA.tar.gz
wget https://tri-robotics-public.s3.amazonaws.com/centersnap/Real.tar.gz
tar -xzvf Real.tar.gz
Die Datenverzeichnisstruktur sollte wie folgt aussehen:
data
├── CAMERA
│ ├── train
│ └── val_subset
├── Real
│ ├── train
└── └── test
./runner.sh net_train.py @configs/net_config.txtBeachten Sie, dass runner.sh der Verwendung von Python zum Ausführen des Skripts entspricht. Darüber hinaus richtet es den PYTHONPATH- und CenterSnap-Umgebungspfad automatisch ein.
./runner.sh net_train.py @configs/net_config_real_resume.txt --checkpoint p ath t o b est c heckpoint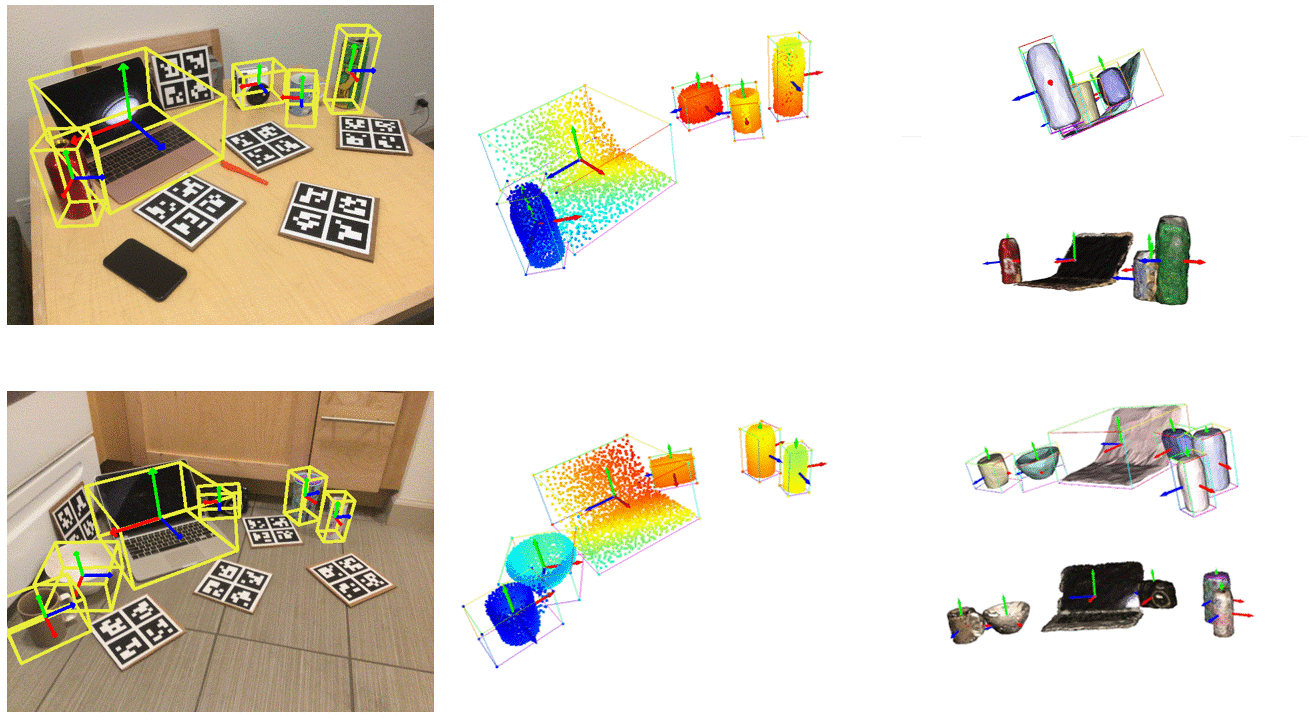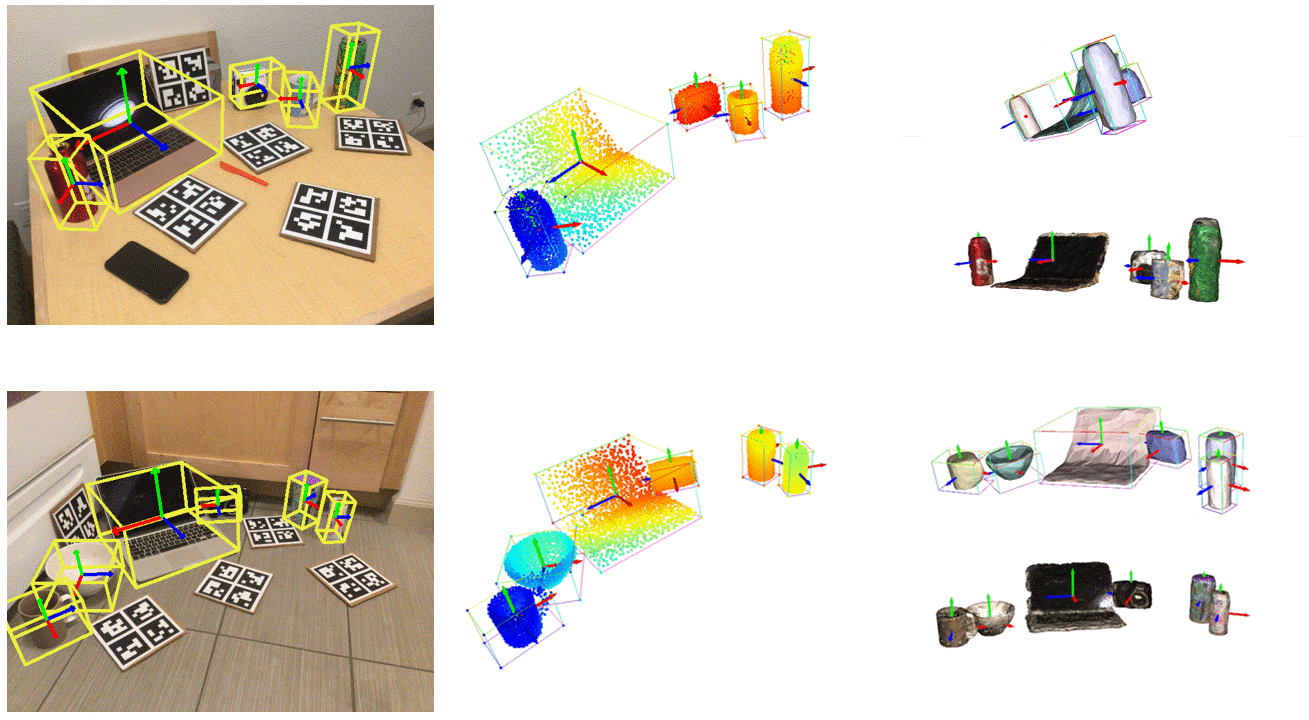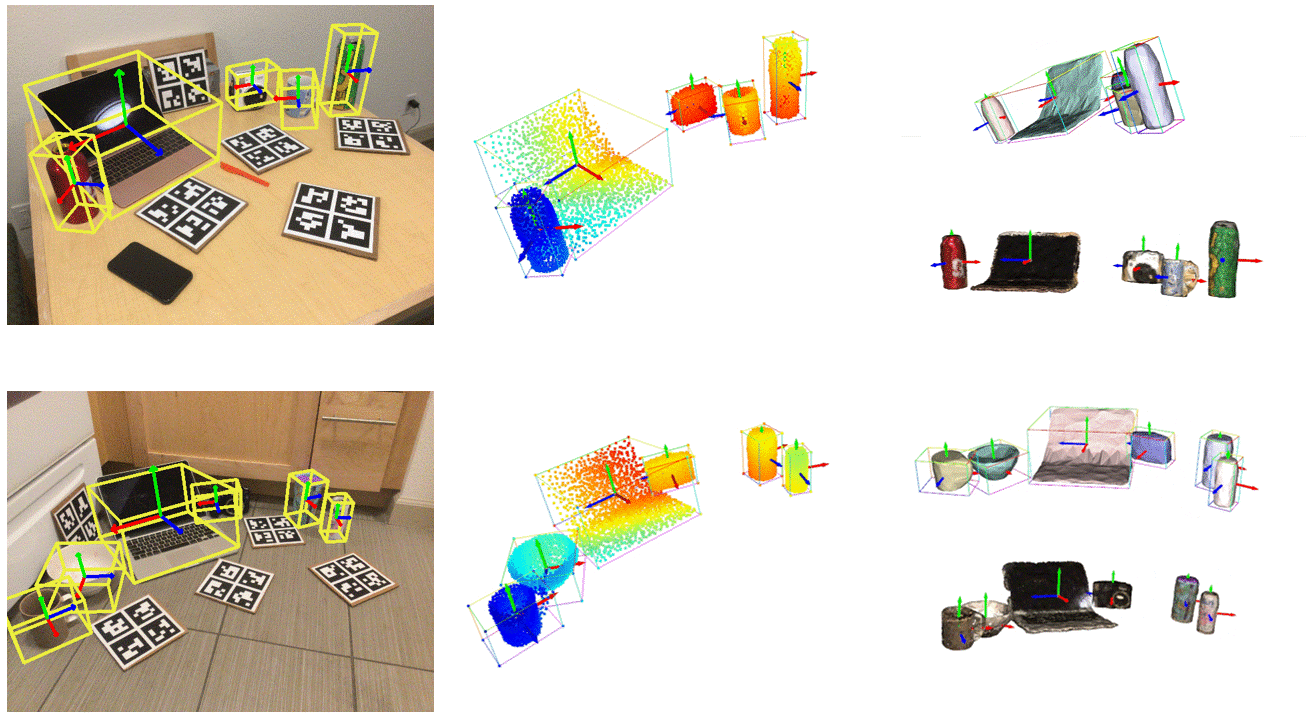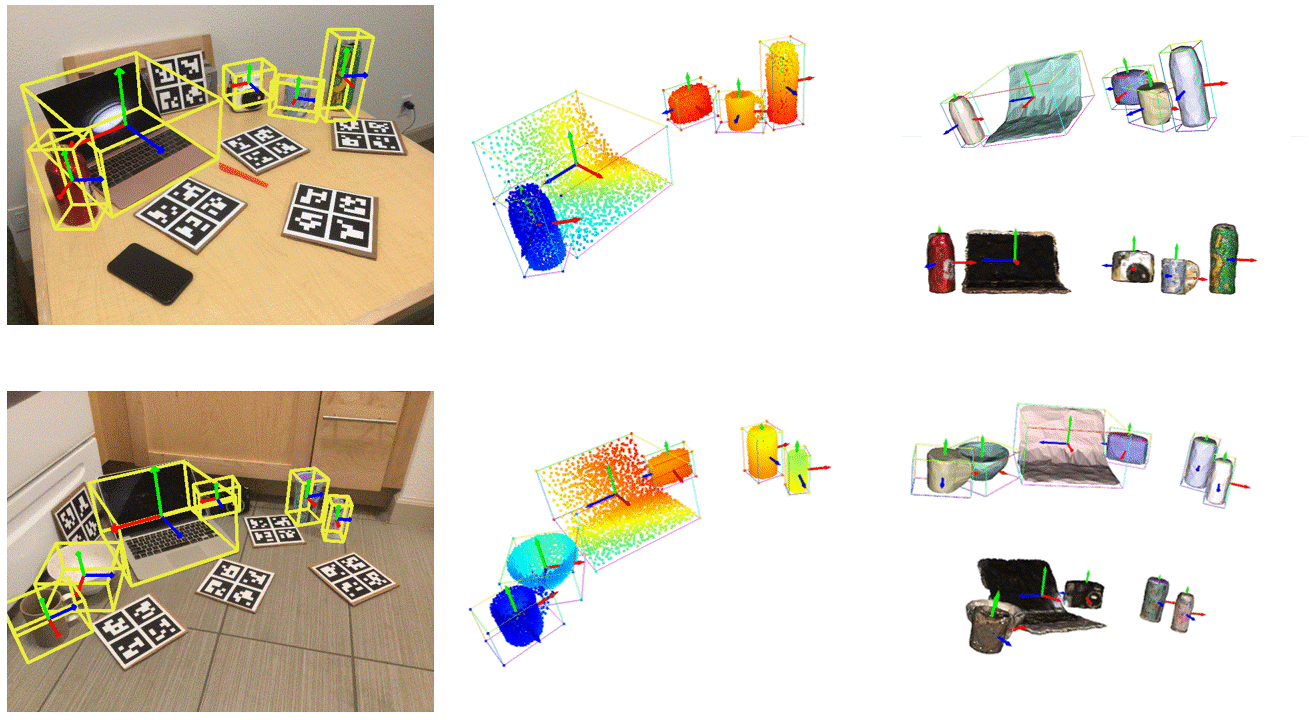
Laden Sie eine kleine NOCS Real-Teilmenge von [hier] herunter.
./runner.sh inference/inference_real.py @configs/net_config.txt --data_dir path_to_nocs_test_subset --checkpoint checkpoint_path_here Sie sollten die in results/CenterSnap gespeicherten Visualisierungen sehen. Ändern Sie den --ouput_path in *config.txt, um sie in einem anderen Ordner zu speichern
Wir stellen ein vorab trainiertes Modell für den Form-Auto-Encoder zur Verfügung, das für die Datenerfassung und -inferenz verwendet werden kann. Obwohl unsere Codebasis kein separates Training des Shape-Auto-Encoders erfordert, stellen wir Ihnen, wenn Sie dies möchten, zusätzliche Skripte unter external/shape_pretraining zur Verfügung
1. Ich erhalte keine gute Leistung bei meinen benutzerdefinierten Kamerabildern, z. B. Realsense, OAK-D oder anderen.
2. So erzielen Sie gute Zero-Shot-Ergebnisse mit der HSR-Roboterkamera:
3. Während ich Colab ausführe, stehen mir no cuda GPUs available .
Make sure that you have enabled the GPU under Runtime-> Change runtime type!
4. Ich erhalte die Meldung raise RuntimeError('received %d items of ancdata' % RuntimeError: received 0 items of ancdata
uimit -n 2048 auf 2048 oder 8096 5. Ich erhalte RuntimeError: CUDA error: no kernel image is available for execution on the device oder You requested GPUs: [0] But your machine only has: []
Cuda 10.2 installieren und dasselbe Skript in „requirements.txt“ ausführen
Installieren Sie die entsprechende Pytorch-Cuda-Version, dh ändern Sie diese Zeile in der Datei „requirements.txt“.
torch==1.7.1
torchvision==0.8.2
6. Ich sehe Nullwertmetriken in wandb
Unsere weitere ECCV-Arbeit:
Weitere Nachfolgewerke (Danke an die Autoren für ihre großartige Arbeit):


