rotary embedding torch
0.8.6
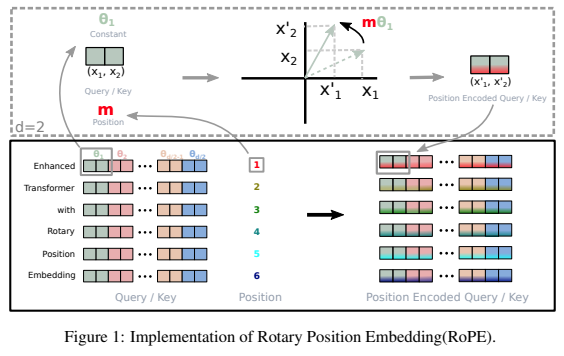
Eine eigenständige Bibliothek zum Hinzufügen rotierender Einbettungen zu Transformatoren in Pytorch, nach ihrem Erfolg als relative Positionskodierung. Insbesondere wird es die Rotation von Informationen in jede beliebige Achse eines Tensors einfach und effizient machen, unabhängig davon, ob sie ortsfest oder erlernt sind. Mit dieser Bibliothek erhalten Sie zu geringen Kosten modernste Ergebnisse für die Positionseinbettung.
Mein Bauchgefühl sagt mir auch, dass Rotationen noch etwas anderes beinhalten, das in künstlichen neuronalen Netzen ausgenutzt werden kann.
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usualWenn Sie alle oben genannten Schritte richtig ausführen, sollten Sie während des Trainings eine dramatische Verbesserung feststellen
Beim Umgang mit Schlüssel-/Wert-Caches bei der Inferenz muss die Abfrageposition mit key_value_seq_length - query_seq_length versetzt werden
Um dies zu vereinfachen, verwenden Sie die Methode rotate_queries_with_cached_keys .
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )Sie können dies auch manuell tun
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])Zur einfachen Verwendung der n-dimensionalen axialen relativen Positionseinbettung, d. h. Videotransformatoren
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k ) In diesem Artikel konnten sie das Problem der Längenextrapolation bei rotierenden Einbettungen beheben, indem sie ihm einen Zerfall ähnlich wie bei ALiBi gaben. Sie haben diese Technik XPos genannt, und Sie können sie verwenden, indem Sie bei der Initialisierung use_xpos = True festlegen.
Dies kann nur für autoregressive Transformatoren verwendet werden
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )In diesem MetaAI-Artikel wird lediglich eine Feinabstimmung der Interpolationen der Sequenzpositionen vorgeschlagen, um vorab trainierte Modelle auf eine längere Kontextlänge auszudehnen. Sie zeigen, dass dies viel besser funktioniert als die einfache Feinabstimmung derselben Sequenzpositionen, die jedoch weiter ausgedehnt wird.
Sie können dies nutzen, indem Sie den interpolate_factor bei der Initialisierung auf einen Wert größer als 1. setzen. (Beispiel: Wenn das vorab trainierte Modell auf 2048 trainiert wurde, würde die Einstellung interpolate_factor = 2. eine Feinabstimmung auf 2048 x 2. = 4096 )
Update: Jemand in der Community hat gemeldet, dass es nicht gut funktioniert. Bitte senden Sie mir eine E-Mail, wenn Sie ein positives oder negatives Ergebnis sehen
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

