audiolm pytorch
2.2.3
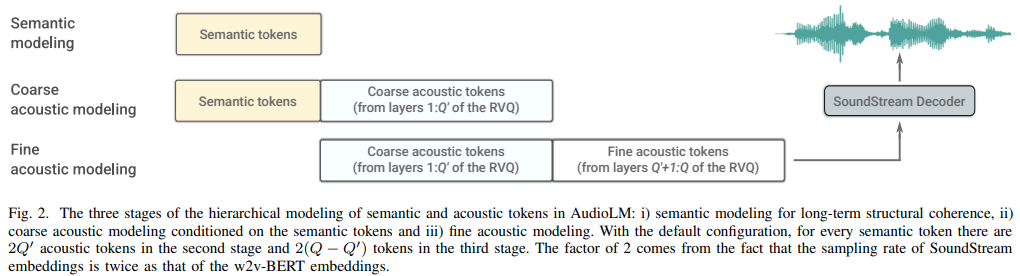
Implementierung von AudioLM, einem Sprachmodellierungsansatz zur Audiogenerierung aus Google Research, in Pytorch
Es erweitert auch die Arbeit für die Konditionierung mit klassifikatorfreier Führung mit T5. Dies ermöglicht die Durchführung von Text-to-Audio oder TTS, die in der Arbeit nicht angeboten werden. Ja, das bedeutet, dass VALL-E aus diesem Repository trainiert werden kann. Es ist im Wesentlichen dasselbe.
Bitte melden Sie sich an, wenn Sie daran interessiert sind, diese Arbeit öffentlich zu reproduzieren
Dieses Repository enthält jetzt auch eine MIT-lizenzierte Version von SoundStream. Es ist auch mit EnCodec kompatibel, das zum Zeitpunkt des Schreibens ebenfalls MIT-lizenziert war.
Update: AudioLM wurde im Wesentlichen dazu verwendet, die Musikgenerierung im neuen MusicLM zu „lösen“.
In Zukunft würde dieser Filmausschnitt keinen Sinn mehr ergeben. Sie würden stattdessen einfach eine KI veranlassen.
Stability.ai für das großzügige Sponsoring der Arbeit und der Open-Source-Forschung im Bereich der künstlichen Intelligenz
? Huggingface für ihre erstaunlichen Beschleunigungs- und Transformer-Bibliotheken
MetaAI für Fairseq und die liberale Lizenz
@eonglints und Joseph für ihre professionelle Beratung und ihr Fachwissen sowie für Pull-Requests!
@djqualia, @yigityu, @inspirit und @BlackFox1197 für ihre Hilfe beim Debuggen von Soundstream
Allen und LWprogramming für die Überprüfung des Codes und die Einreichung von Fehlerbehebungen!
Ilya für die Entdeckung eines Problems mit dem Multiskalen-Diskriminator-Downsampling und für die Verbesserungen des Soundstream-Trainers
Andrey, der einen fehlenden Verlust im Schallstrom identifiziert und mich durch die richtigen Mel-Spektrogramm-Hyperparameter geführt hat
Alejandro und Ilya für das Teilen ihrer Ergebnisse mit dem Trainings-Soundstream und für die Lösung einiger Probleme mit den lokalen Aufmerksamkeitspositionseinbettungen
LWprogrammierung zum Hinzufügen von Encodec-Kompatibilität!
LWprogrammierung zum Finden eines Problems mit der Handhabung des EOS-Tokens beim Sampling vom FineTransformer !
@YoungloLee für die Identifizierung eines großen Fehlers in der 1D-Kausalfaltung für den Soundstream, der damit zusammenhängt, dass das Padding keine Schritte berücksichtigt!
Hayden für den Hinweis auf einige Unstimmigkeiten im Multiskalen-Diskriminator für Soundstream
$ pip install audiolm-pytorchFür den neuronalen Codec gibt es zwei Optionen. Wenn Sie den vorab trainierten 24-kHz-Encodec verwenden möchten, erstellen Sie einfach ein Encodec-Objekt wie folgt:
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. Andernfalls können Sie SoundStream verwenden, um dem Originalpapier treuer zu bleiben. Zunächst muss SoundStream auf einem großen Korpus von Audiodaten trainiert werden
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel Ihr trainierter SoundStream kann dann als generischer Tokenizer für Audio verwendet werden
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) Sie können auch AudioLM und MusicLM spezifische Soundstreams verwenden, indem Sie AudioLMSoundStream bzw. MusicLMSoundStream importieren
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above Ab Version 0.17.0 können Sie nun die Klassenmethode auf SoundStream aufrufen, um Checkpoint-Dateien zu laden, ohne sich Ihre Konfigurationen merken zu müssen.
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) Um das Weights & Biases-Tracking zu verwenden, setzen Sie zunächst use_wandb_tracking = True für den SoundStreamTrainer und führen Sie dann die folgenden Schritte aus
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () Anschließend müssen drei separate Transformatoren ( SemanticTransformer , CoarseTransformer , FineTransformer ) trainiert werden
ex. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () ex. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () ex. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()Jetzt alle zusammen
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])Update: Es sieht so aus, als ob dies angesichts von „VALL-E“ funktionieren wird.
ex. Semantischer Transformator
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] Weil alle Trainerklassen ? Accelerator: Sie können ganz einfach ein Multi-GPU-Training durchführen, indem Sie den accelerate verwenden
Im Projektstamm
$ accelerate configDann im selben Verzeichnis
$ accelerate launch train . py kompletter CoarseTransformer
Verwenden Sie fairseq vq-wav2vec für Einbettungen
Konditionierung hinzufügen
Fügen Sie eine kostenlose Anleitung zum Klassifikator hinzu
Fügen Sie eine eindeutige Folge für hinzu
Integrieren Sie die Fähigkeit, Hubert-Zwischenfunktionen als semantische Token zu verwenden, empfohlen von Eonglints
Unterbringen Sie Audio mit variabler Länge und bringen Sie EOS-Token mit
Stellen Sie sicher, dass mit dem Grobtransformator eindeutige, aufeinanderfolgende Arbeiten durchgeführt werden
Schön, dass alle Diskriminatorverluste protokolliert werden
Beachten Sie bei der Generierung semantischer Token, dass die letzten Logits bei eindeutiger aufeinanderfolgender Verarbeitung möglicherweise nicht unbedingt die letzten in der Sequenz sind
Vollständiger Sampling-Code für Grob- und Feintransformatoren, was schwierig sein wird
Stellen Sie sicher, dass die vollständige Inferenz mit oder ohne Eingabeaufforderung in der AudioLM -Klasse funktioniert
Vervollständigen Sie den vollständigen Trainingscode für Soundstream und kümmern Sie sich um das Diskriminatortraining
Fügen Sie eine effiziente Gradientenstrafe für Diskriminatoren für den Soundstream hinzu
Verbinden Sie die Sample-Hz aus dem Sound-Datensatz -> Transformatoren und führen Sie während des Trainings ein ordnungsgemäßes Resampling durch. Überlegen Sie, ob der Datensatz Sounddateien mit unterschiedlichen Sounddateien zulassen oder dieselben Sample-Hz erzwingen soll
Vollständiger Transformator-Trainingscode für alle drei Transformatoren
Umgestalten, sodass der semantische Transformator über einen Wrapper verfügt, der eindeutige Konsekutivdaten sowie WAV an Hubert oder VQ-WAV2VEC verarbeitet
Achten Sie einfach nicht selbst auf den EOS-Token auf der Eingabeaufforderungsseite (Semantik für groben Transformator, grob für feinen Transformator).
Fügen Sie strukturierte Dropouts aus vergesslicher Kausalmaskierung hinzu, weitaus besser als herkömmliche Dropouts
Finden Sie heraus, wie Sie die Protokollierung in fairseq unterdrücken können
Stellen Sie sicher, dass alle drei an audiolm übergebenen Transformatoren kompatibel sind
ermöglichen spezielle relative Positionseinbettungen im Feintransformator basierend auf absoluten Übereinstimmungspositionen von Quantisierern zwischen grob und fein
Ermöglichen Sie gruppiertes Rest-VQ im Soundstream (verwenden Sie GroupedResidualVQ aus der Vector-Quantize-Pytorch-Bibliothek) aus dem HiFi-Codec
Erhöhen Sie die Aufmerksamkeit mit NoPE
Akzeptieren Sie Prime Wave in AudioLM als Pfad zu einer Audiodatei und führen Sie ein automatisches Resample für Semantik und Akustik durch
Fügen Sie allen Transformatoren Schlüssel-/Wert-Caching hinzu, um die Inferenz zu beschleunigen
Entwerfen Sie einen hierarchischen Grob- und Feintransformator
Untersuchen Sie die Spezifikationsdekodierung, testen Sie sie zunächst in X-Transformern und portieren Sie sie gegebenenfalls
Wiederholen Sie die Positionseinbettungen bei Vorhandensein von Gruppen im Rest vq
Test mit Sprachsynthese für den Anfang
CLI-Tool, so etwas wie audiolm generate <wav.file | text> und speichern Sie die generierte WAV-Datei im lokalen Verzeichnis
Gibt eine Liste von Wellen zurück, wenn es sich um Audiodaten mit variabler Länge handelt
Achten Sie einfach auf den Randfall beim textkonditionierten Training mit Grobtransformatoren, bei dem die Rohwelle bei verschiedenen Frequenzen neu abgetastet wird. Bestimmen Sie automatisch, wie die Route basierend auf der Länge ausgeführt wird
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

