electra pytorch
0.1.2
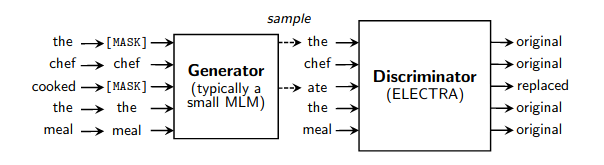
Ein einfacher funktionierender Wrapper für das schnelle Vortraining von Sprachmodellen, wie in diesem Artikel beschrieben. Es beschleunigt das Training (im Vergleich zur normalen maskierten Sprachmodellierung) um den Faktor 4 und erzielt schließlich eine bessere Leistung, wenn es noch länger trainiert wird. Besonderer Dank geht an Erik Nijkamp, der sich die Zeit genommen hat, die Ergebnisse für GLUE zu reproduzieren.
$ pip install electra-pytorch Im folgenden Beispiel wird reformer-pytorch verwendet, das für die Pip-Installation verfügbar ist.
import torch
from torch import nn
from reformer_pytorch import ReformerLM
from electra_pytorch import Electra
# (1) instantiate the generator and discriminator, making sure that the generator is roughly a quarter to a half of the size of the discriminator
generator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 256 , # smaller hidden dimension
heads = 4 , # less heads
ff_mult = 2 , # smaller feed forward intermediate dimension
dim_head = 64 ,
depth = 12 ,
max_seq_len = 1024
)
discriminator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 1024 ,
dim_head = 64 ,
heads = 16 ,
depth = 12 ,
ff_mult = 4 ,
max_seq_len = 1024
)
# (2) weight tie the token and positional embeddings of generator and discriminator
generator . token_emb = discriminator . token_emb
generator . pos_emb = discriminator . pos_emb
# weight tie any other embeddings if available, token type embeddings, etc.
# (3) instantiate electra
trainer = Electra (
generator ,
discriminator ,
discr_dim = 1024 , # the embedding dimension of the discriminator
discr_layer = 'reformer' , # the layer name in the discriminator, whose output would be used for predicting token is still the same or replaced
mask_token_id = 2 , # the token id reserved for masking
pad_token_id = 0 , # the token id for padding
mask_prob = 0.15 , # masking probability for masked language modeling
mask_ignore_token_ids = [] # ids of tokens to ignore for mask modeling ex. (cls, sep)
)
# (4) train
data = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
results = trainer ( data )
results . loss . backward ()
# after much training, the discriminator should have improved
torch . save ( discriminator , f'./pretrained-model.pt' )Wenn Sie nicht möchten, dass das Framework die versteckte Ausgabe des Diskriminators automatisch abfängt, können Sie den Diskriminator (mit dem zusätzlichen linearen [dim x 1]) wie folgt selbst übergeben.
import torch
from torch import nn
from reformer_pytorch import ReformerLM
from electra_pytorch import Electra
# (1) instantiate the generator and discriminator, making sure that the generator is roughly a quarter to a half of the size of the discriminator
generator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 256 , # smaller hidden dimension
heads = 4 , # less heads
ff_mult = 2 , # smaller feed forward intermediate dimension
dim_head = 64 ,
depth = 12 ,
max_seq_len = 1024
)
discriminator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 1024 ,
dim_head = 64 ,
heads = 16 ,
depth = 12 ,
ff_mult = 4 ,
max_seq_len = 1024 ,
return_embeddings = True
)
# (2) weight tie the token and positional embeddings of generator and discriminator
generator . token_emb = discriminator . token_emb
generator . pos_emb = discriminator . pos_emb
# weight tie any other embeddings if available, token type embeddings, etc.
# (3) instantiate electra
discriminator_with_adapter = nn . Sequential ( discriminator , nn . Linear ( 1024 , 1 ))
trainer = Electra (
generator ,
discriminator_with_adapter ,
mask_token_id = 2 , # the token id reserved for masking
pad_token_id = 0 , # the token id for padding
mask_prob = 0.15 , # masking probability for masked language modeling
mask_ignore_token_ids = [] # ids of tokens to ignore for mask modeling ex. (cls, sep)
)
# (4) train
data = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
results = trainer ( data )
results . loss . backward ()
# after much training, the discriminator should have improved
torch . save ( discriminator , f'./pretrained-model.pt' )Für ein effektives Training sollte der Generator etwa ein Viertel bis höchstens die Hälfte der Größe des Diskriminators betragen. Bei einem größeren Wert ist der Generator zu gut und das gegnerische Spiel bricht zusammen. Dies wurde erreicht, indem die verborgene Dimension reduziert, die verborgene Dimension weitergeleitet und die Anzahl der Aufmerksamkeitsköpfe in der Arbeit verringert wurde.
$ python setup.py test $ mkdir data
$ cd data
$ pip3 install gdown
$ gdown --id 1EA5V0oetDCOke7afsktL_JDQ-ETtNOvx
$ tar -xf openwebtext.tar.xz
$ wget https://storage.googleapis.com/electra-data/vocab.txt
$ cd ..$ python pretraining/openwebtext/preprocess.py$ python pretraining/openwebtext/pretrain.py$ python examples/glue/download.py $ python examples/glue/run.py --model_name_or_path output/yyyy-mm-dd-hh-mm-ss/ckpt/200000 @misc { clark2020electra ,
title = { ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators } ,
author = { Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning } ,
year = { 2020 } ,
eprint = { 2003.10555 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}

