lion pytorch
0.2.3
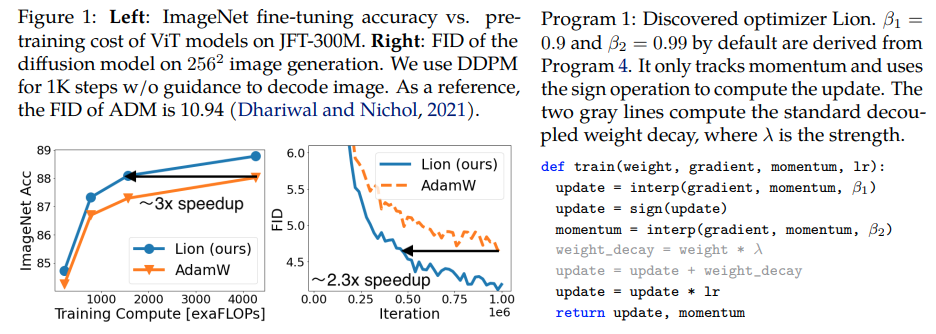
Lion, Evo L ved S i gn M o me n tum, neuer von Google Brain entdeckter Optimierer, der angeblich besser als Adam(w) in Pytorch ist. Dies ist nahezu eine reine Kopie von hier, mit wenigen geringfügigen Änderungen.
Es ist so einfach, dass wir es genauso gut schnellstmöglich allen zugänglich machen und nutzen können, um einige großartige Modelle zu trainieren. Wenn es wirklich funktioniert?
Lernrate und Gewichtsabnahme: Die Autoren schreiben in Abschnitt 5 – Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. Der Anfangswert, der Spitzenwert und der Endwert im Lernratenplan sollten gleichzeitig im gleichen Verhältnis wie bei AdamW geändert werden, wie von einem Forscher nachgewiesen.
Lernratenplan: Die Autoren verwenden für Lion den gleichen Lernratenplan wie für AdamW in der Arbeit. Dennoch beobachten sie einen größeren Gewinn, wenn zum Trainieren von ViT ein Cosinus-Zerfallsplan verwendet wird, im Vergleich zu einem reziproken Quadratwurzelplan.
β1 und β2: Die Autoren schreiben in Abschnitt 5 – The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. Ähnlich wie Menschen bei AdamW β2 auf 0,99 oder weniger reduzieren und ε auf 1e-6 erhöhen, um die Stabilität zu verbessern, kann die Verwendung von β1=0.95, β2=0.98 bei Lion auch hilfreich sein, um die Instabilität während des Trainings zu mildern, wie von den Autoren vorgeschlagen. Dies wurde von einem Forscher bestätigt.
Update: Scheint für meine lokale autoregressive Sprachmodellierung enwik8 zu funktionieren.
Update 2: Experimente scheinen viel schlechter zu sein als Adam, wenn die Lernrate konstant bleibt.
Update 3: Lernrate durch 3 dividieren, bessere frühe Ergebnisse als bei Adam. Vielleicht wurde Adam nach fast einem Jahrzehnt entthront.
Update 4: Die Verwendung der Faustregel „10x kleinere Lernrate“ aus dem Papier führte zum schlechtesten Lauf. Ich vermute also, dass es noch ein wenig Feinabstimmung braucht.
Eine Zusammenfassung früherer Updates: Wie in den Experimenten gezeigt wurde, schlägt Lion mit einer dreimal geringeren Lernrate Adam. Es ist noch ein wenig Anpassung erforderlich, da eine 10-mal geringere Lernrate zu einem schlechteren Ergebnis führt.
Update 5: Bisher habe ich bei der Sprachmodellierung alle positiven Ergebnisse gehört, wenn man es richtig macht. Ich habe auch positive Ergebnisse für ein signifikantes Text-zu-Bild-Training gehört, obwohl es ein wenig Feinabstimmung erfordert. Die negativen Ergebnisse scheinen sich auf Probleme und Architekturen zu beziehen, die über das hinausgehen, was in der Arbeit bewertet wurde – RL, Feedforward-Netzwerke, seltsame Hybridarchitekturen mit LSTMs + Faltungen usw. Negative Anekdoten bestätigen auch, dass diese Technik empfindlich auf Batchgröße, Datenmenge/Erweiterung reagiert . Wir klären noch, welcher optimale Lernratenplan ist und ob sich die Abklingzeit auf die Ergebnisse auswirkt. Interessanterweise gibt es auch ein positives Ergebnis bei Open-Clip, das negativ wurde, als die Modellgröße vergrößert wurde (aber möglicherweise auflösbar ist).
Update 6: Das Problem mit dem offenen Clip wurde vom Autor behoben, indem eine höhere Anfangstemperatur eingestellt wurde.
Update 7: Ich würde diesen Optimierer nur bei hohen Batchgrößen (64 oder mehr) empfehlen.
$ pip Lion-Pytorch installieren
Alternativ mit conda:
$ conda installiert lion-pytorch
# Toy Modelimport Torchfrom Torch Import nnmodel = nn.Linear(10, 1)# Lion importieren und mit Parametern von lion_pytorch instanziieren import Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2)# vorwärts und backwardsloss = model(torch.randn(10))loss.backward()# Optimizer stepopt.step()opt.zero_grad()
Um einen fusionierten Kernel zum Aktualisieren der Parameter zu verwenden, pip install triton -U --pre zuerst und dann
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # setzen Sie dies auf True, um den Cuda-Kernel mit Triton lang zu verwenden (Tillet et al))
Stability.ai für das großzügige Sponsoring der Arbeit und der Open-Source-Forschung im Bereich der künstlichen Intelligenz
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Chen, Xiangning und Liang, Chen und Huang, Da und Real, Esteban und Wang, Kaiyuan und Liu, Yao und Pham, Hieu und Dong, Xuanyi und Luong, Thang und Hsieh, Cho-Jui und Lu, Yifeng und Le, Quoc V.},title = {Symbolic Discovery of Optimization Algorithms},publisher = {arXiv},year = {2023}} @article{Tillet2019TritonAI,title = {Triton: eine Zwischensprache und ein Compiler für gekachelte neuronale Netzwerkberechnungen},Autor = {Philippe Tillet und H. Kung und D. Cox},journal = {Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Sprachen lernen und programmieren},Jahr = {2019}} @misc{Schaipp2024,author = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {Vorsichtige Optimierer: Verbesserung des Trainings mit einer Codezeile},Autor = {Kaizhao Liang und Lizhang Chen und Bo Liu und Qiang Liu},Jahr = {2024},url = {https://api .semanticsscholar.org/CorpusID:274234738}} 

