Extendible Hashing for DBMS
1.0.0
Eine Low-Level-Implementierung von erweiterbarem Hashing für Datenbanksysteme.
Diese Methode nutzt Verzeichnisse und Buckets zum Hashen von Daten und ist weithin für ihre Flexibilität und Effizienz bei der Rechenzeit bekannt.
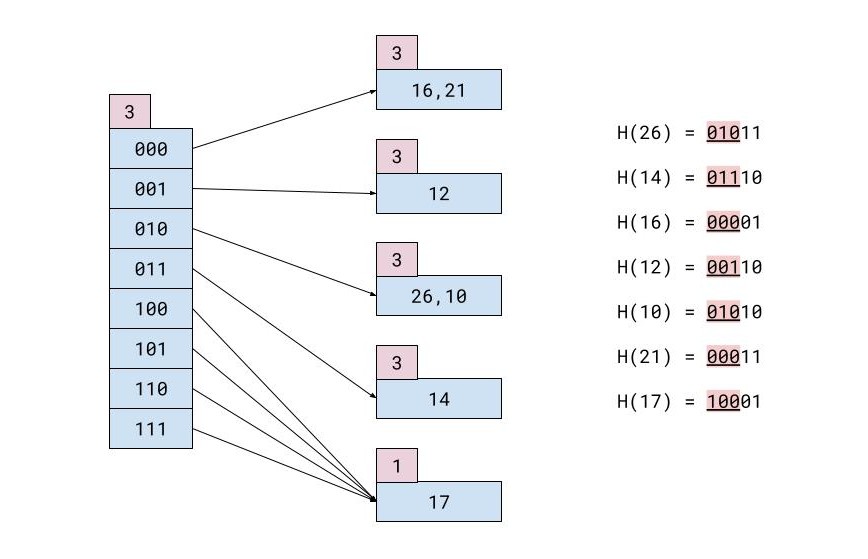
Sie haben zum Beispiel diese Tabelle mit Datensätzen:
| AUSWEIS | NAME | NACHNAME | STADT |
|---|---|---|---|
| 26 | Maria | Koronis | Hongkong |
| 14 | Christoforos | Gaitanis | Tokio |
| 16 | Marianna | Karvounari | Miami |
| 12 | Theofilos | Nikolopoulos | London |
| 10 | Iosif | Svingos | Tokio |
| 21 | Theofilos | Michas | Athen |
| 17 | Giorgos | Halatsis | München |
Wenn jeder Speicherblock nur zwei Datensätze enthalten kann, sieht die Hash-Datei nach allen Einfügungen folgendermaßen aus:
Das Programm kann von zwei verschiedenen Hauptfunktionen ausgeführt werden. Der erste fügt eine große Anzahl von Datensätzen in eine Datei ein und der zweite erstellt und fügt Datensätze gleichzeitig in drei verschiedene Dateien ein.
test_main1:
make main1
./build/runner
test_main2:
make main2
./build/runner