article_spider
1.0.0
Konsolenausgabe:
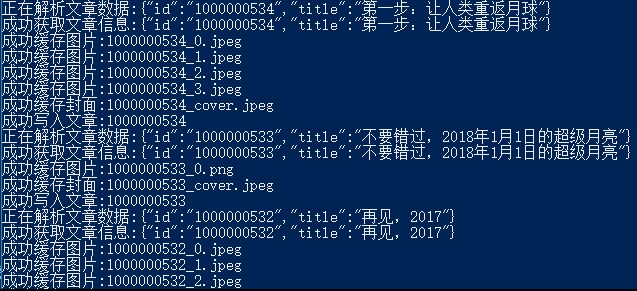
Artikeldaten:
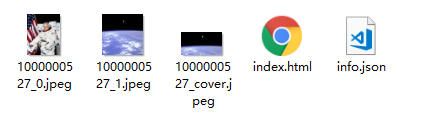
HTML-Vorschau:

Derzeit werden zwei Methoden zum Crawlen von Artikeln unterstützt.
Fangen Sie Artikel über die Suchergebnisse von Sogou WeChat ab.
Vorteile: Diese Methode erfordert keine Login-Authentifizierung und ist einfach zu bedienen.
Nachteile: Es können nur die letzten 10 Daten erfasst werden.
Verwendungsszenario: Geeignet zum Konfigurieren geplanter Crawling-Aufgaben zum Abrufen großer Datenmengen.
Fangen Sie die Ajax-Anforderungsparameter der Artikelliste des öffentlichen WeChat-Kontos ab und simulieren Sie den WeChat-Client, um die Artikelliste und Artikelinformationen zu lesen.
Vorteile: Kann alle Artikeldaten öffentlicher Konten abrufen.
Nachteile: Sie müssen sich bei WeChat anmelden und Parameter wie Cookies manuell über Tools festlegen, bevor Sie es verwenden können.
Verwendungsszenario: Erfassen Sie eine große Menge öffentlicher Kontodaten gleichzeitig und aktualisieren Sie die Daten nach Abschluss der Erfassung mit der Sogou-Methode.
NodeJS & NPM, Chrome-Browser, WeChat-Desktop-Client (entweder Mac oder Windows)
git clone [email protected]:f111fei/article_spider.git
cd article_spider
npm install typescript -g
npm install
tsc
Legen Sie die Datei config.json im Stammverzeichnis des Projekts fest. Die Felder sind wie folgt definiert:
interface Config {
// 必填,要抓取的微信公众号名称。
name: string;
// 可选,若快打码平台的账号密码。用于搜狗抓取模式下自动识别验证码。
ruokuai: {
username: string;
password: string;
};
wechat: {
// 可选,要抓取文章的起始页,默认0
start?: number;
// 可选,要抓取的文章数,默认不限制
maxNum?: number;
// 可选,抓取模式(sougou, all)。默认all
mode?: string;
// 抓取模式为all时有效,公众号的biz字段,获取方法参见下面
biz?: string;
// 抓取模式为all时有效,当前cookie字段,获取方法参见下面
cookie?: string;
// 抓取模式为all时有效,当前appmsg_token字段,获取方法参见下面
appmsg_token?: string;
};
}
Wenn der Crawl-Modus sougou lautet, überspringen Sie diesen Abschnitt.
Um die Ajax-Anfragedaten der Artikelliste zu erhalten, müssen Sie die Anfrage erfassen, um die Artikellistendaten zu erhalten und wichtige Parameter wie biz, cookie, appmsg_token usw. zu finden. Hier erfahren Sie, wie Sie die Anforderungsparameter abrufen.
Nehmen wir als Beispiel die Ergreifung öffentlicher Accounts von NASA爱好者.
1. Öffnen Sie das offizielle Konto – obere rechte Ecke – klicken Sie, um historische Nachrichten anzuzeigen
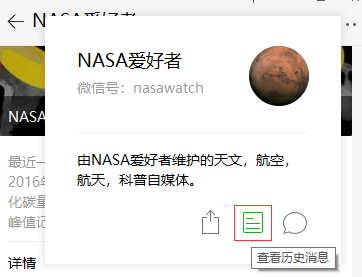
Hinweis: Das
namein der Konfiguration sollte mit der WeChat-IDnasawatchhier ausgefüllt werden, nicht mitNASA爱好者.
2. Klicken Sie im geöffneten Fenster in der Menüleiste auf Mit Standardbrowser (Chrome) öffnen und verwenden Sie Chrome, um die Artikellistenseite zu öffnen.

3. Wenn der Link beim Öffnen im Browser angezeigt wird请在微信客户端打开链接。 Eingabeaufforderung, die anzeigt, dass die URL verschlüsselt wurde. Bitte befolgen Sie die folgenden Schritte, um die richtige URL zu erhalten. Andernfalls überspringen Sie diesen Schritt.
Schließen Sie den WeChat-Client und suchen Sie den Speicherort des ausführbaren Programms des WeChat-Desktop-Clients. Starten Sie das Programm über die Befehlszeile:
Unter Windows ist es normalerweise:
"C:Program Files (x86)TencentWeChatWeChat.exe" --remote-debugging-port=9222
Unter Mac ist es normalerweise:
"/Applications/WeChat.app/Contents/MacOS/WeChat" --remote-debugging-port=9222
Befolgen Sie Schritt 1, um die Seite mit den Verlaufsnachrichten zu öffnen.
Öffnen Sie die URL http://127.0.0.1:9222/json mit dem Chrome-Browser.
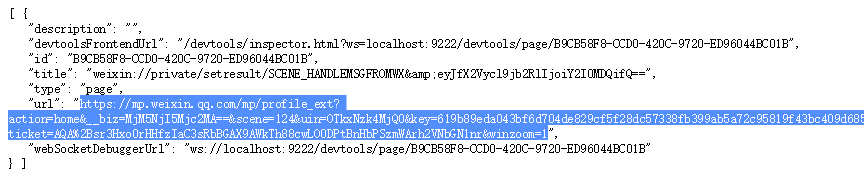
Kopieren Sie das URL-Feld und öffnen Sie es in einem neuen Tab. Daraufhin wird die korrekte Seite mit den historischen Nachrichten angezeigt.
4. Klicken Sie auf der Seite mit den Verlaufsnachrichten mit der rechten Maustaste ---- Aktivieren Sie, öffnen Sie die Chrome Developer Tools ---- Wechseln Sie zur Registerkarte „Netzwerk“ ---- Aktualisieren Sie den Browser. Suchen Sie rechts nach den Feldern „cookie“, „biz“, „appmsg_token“ und anderen Feldern und füllen Sie diese in config.json aus.
Sie müssen auf der Listenseite nach unten scrollen, um die nächste Seite zu laden, die Anfrage zu finden, die mit
https://mp.weixin.qq.com/mp/profile_ext?action=getmsgbeginnt, und ihre Parameter anzuzeigen.
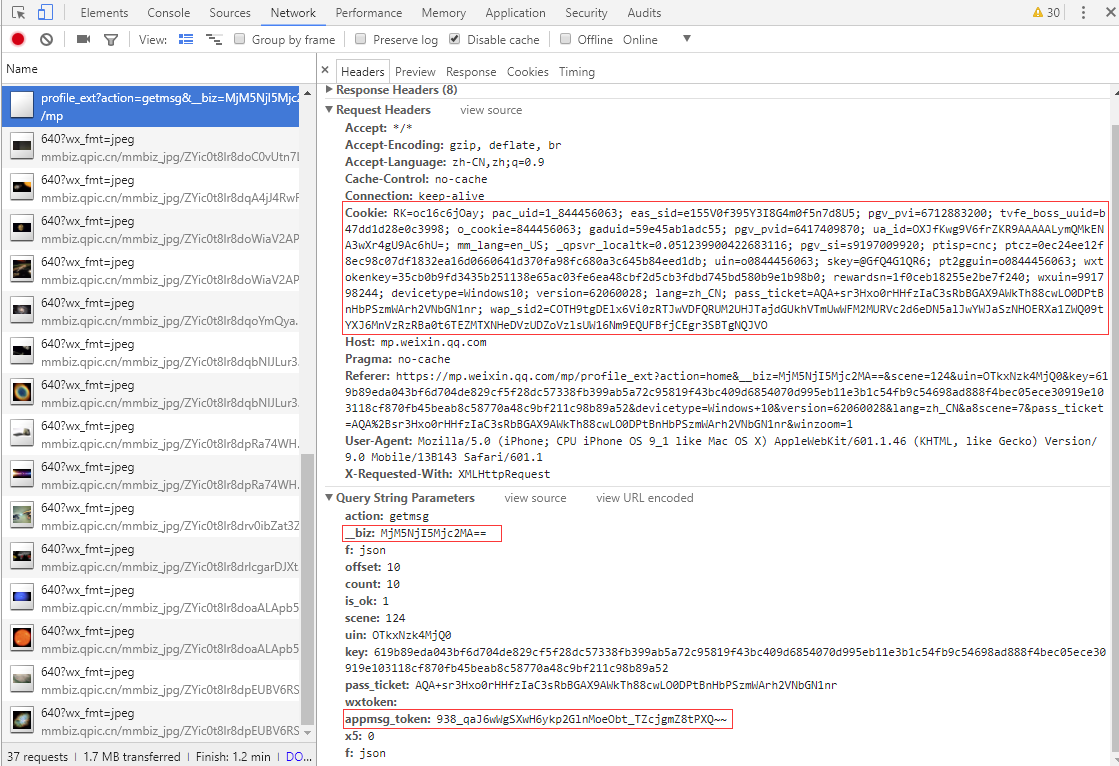
Diese Felder können nach ein paar Stunden ungültig werden und Sie können sie wieder abrufen, indem Sie die oben genannten Schritte ausführen.
npm start
Die gecrawlten Artikelinformationen, Bilder und Originalartikeldaten werden im DB-Ordner im Projektstammverzeichnis gespeichert.


