liuli
v0.2.0
Erkläre es einfach kurz:
Collector : Überwacht benutzerdefinierte Lesequellen wie öffentliche Konten, Bücher oder Blog-Quellen, denen sie folgen, und fließt in einem einheitlichen Standardformat als Eingabequelle in Liuli ein;
Prozessor : Passen Sie den Zielinhalt an, indem Sie beispielsweise maschinelles Lernen verwenden, um einen Werbeklassifikator basierend auf historischen Werbedaten automatisch zu kennzeichnen, oder indem Sie Hook-Funktionen einführen, die auf relevanten Knoten ausgeführt werden.
Verteiler : Verlässt sich auf die Schnittstellenschicht, um Datenanfragen und -antworten durchzuführen, stellt Benutzern personalisierte Konfigurationen zur Verfügung und verteilt sie dann automatisch entsprechend der Konfiguration, indem er saubere Artikel an WeChat-, DingTalk-, TG-, RSS-Clients und sogar selbst erstellte Websites weiterleitet;
Unterstützer : Sichern Sie die verarbeiteten Artikel, indem Sie sie beispielsweise in einer Datenbank oder auf GitHub speichern usw.
Dadurch wird der Aufbau einer sauberen Leseumgebung erreicht. Basierend auf den erhaltenen Daten können viele Dinge getan werden. Möglicherweise möchten Sie Ihre Ideen verbreiten.
Dashboard für den Entwicklungsfortschritt:
v0.2.0: Implementieren Sie grundlegende Funktionen, um sicherzustellen, dass Lösungen für gängige Szenarien angewendet werden können
v0.3.0: Collector-Anpassung implementieren, Benutzer können sammeln, was sie sehen
Um die Erkennungsgenauigkeit des Modells zu verbessern, hoffe ich, dass jeder einige Werbebeispiele beisteuern kann. Bitte sehen Sie sich die Beispieldatei an: .files/datasets/ads.csv. Ich habe das Format wie folgt festgelegt:
| Titel | URL | is_process |
|---|---|---|
| Titel des Werbeartikels | Link zum Werbeartikel | 0 |
Feldbeschreibung:
Titel: Artikeltitel
URL: Artikel-Link. Wenn Sie den WeChat-Artikel verwenden möchten, überprüfen Sie bitte zuerst, ob er ungültig ist.
is_process: Gibt an, ob eine Beispielverarbeitung durchgeführt werden soll. Füllen Sie standardmäßig 0 aus.
Geben wir ein Beispiel:
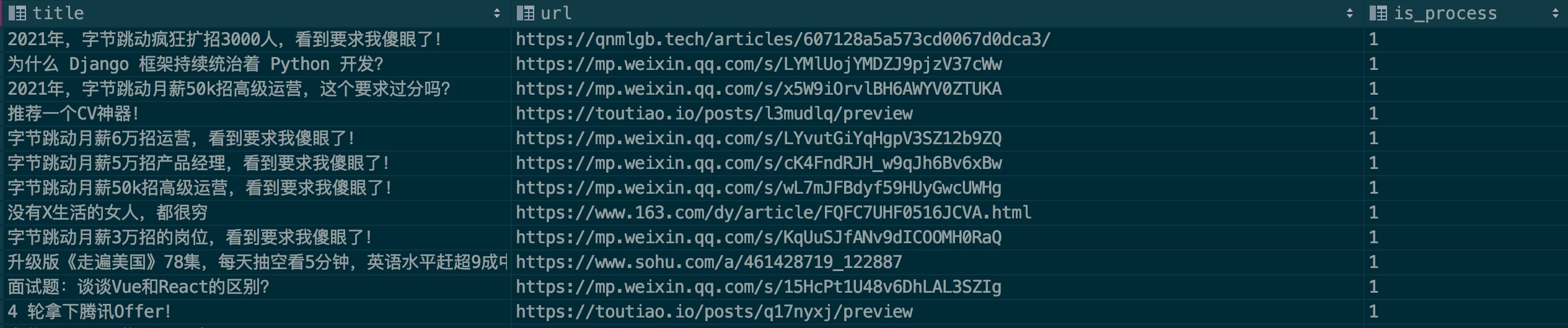
Im Allgemeinen werden Anzeigen immer wieder auf mehreren öffentlichen Konten geschaltet. Bitte prüfen Sie beim Ausfüllen, ob dieser Eintrag vorhanden ist. Lieber, kommen Sie und bringen Sie Ihre Stärke ein.
Vielen Dank an die folgenden Open-Source-Projekte:
Flask: Web-Framework
Vue: Progressives JavaScript-Framework
Ruia: Asynchrones Crawler-Framework (selbst entwickelt und verwendet)
Dramatiker: Daten-Scraping mit dem Browser
Oben sind nur die wichtigsten Open-Source-Abhängigkeiten aufgeführt. Weitere Abhängigkeiten von Drittanbietern finden Sie in der Pipfile-Datei.
Jede PR, die Sie erhalten, ist eine starke Unterstützung für das Liuli -Projekt. Wir sind den folgenden Entwicklern für ihre Beiträge sehr dankbar (in keiner bestimmten Reihenfolge):
Willkommen zur gemeinsamen Kommunikation (folgen Sie der Gruppe):


