ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot ist ein ChatGPT-ähnlicher Roboter, der mithilfe des Dialogmodells basierend auf der offiziellen OpenAI-API implementiert und über das Wechaty-Framework auf WeChat bereitgestellt wird, um Roboter-Chat zu realisieren.
ChatGPT WechatBot ist eine Art ChatGPT-Roboter, der auf der offiziellen OpenAI-API basiert und das Dialogmodell verwendet. Er wird über das Wechat-Framework auf WeChat bereitgestellt, um Roboter-Chat zu erreichen.
Hinweis : Dieses Projekt ist eine lokale Win10-Implementierung und erfordert keine Serverbereitstellung (wenn eine Serverbereitstellung erforderlich ist, können Sie Docker auf dem Server bereitstellen).
(1), Windows10
(2), Docker 20.10.21
(3), Python3.9
(4), Wechaty 0.10.7
1. Laden Sie Docker herunter
https://www.docker.com/products/docker-desktop/ Laden Sie Docker herunter
2. Aktivieren Sie die Win10-Virtualisierung
Geben Sie in cmd die Steuerung ein, um das Bedienfeld zu öffnen und das Programm aufzurufen, wie in der folgenden Abbildung dargestellt:
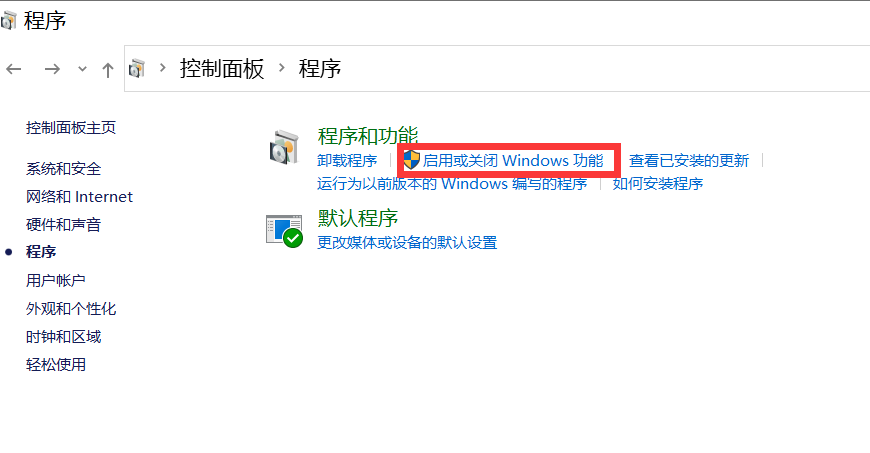
Gehen Sie zu „Windows-Funktionen ein- oder ausschalten“ und aktivieren Sie Hyper-V
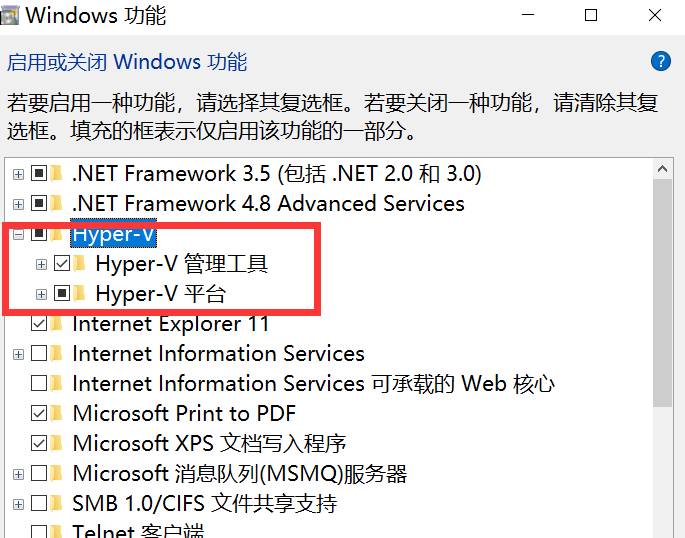
Hinweis : Wenn Ihr Computer nicht über Hyper-V verfügt, müssen Sie die folgenden Vorgänge ausführen:
Erstellen Sie ein Textdokument, geben Sie den folgenden Code ein und nennen Sie es Hyper.cmd
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALLFühren Sie diese Datei dann als Administrator aus. Nachdem die Ausführung des Skripts abgeschlossen ist, wird nach dem Neustart des Computers ein Hyper-V -Knoten angezeigt.
3. Führen Sie Docker aus
Hinweis : Wenn beim ersten Ausführen von Docker Folgendes auftritt:
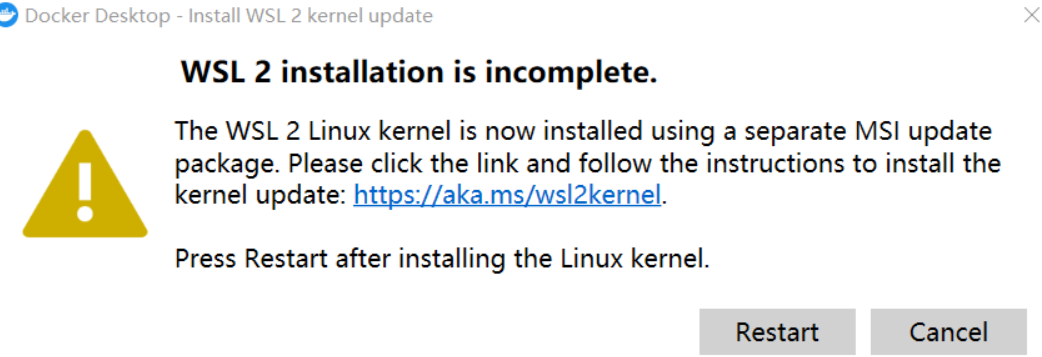
Sie müssen das neueste WSL 2-Paket herunterladen
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
Nach der Aktualisierung können Sie die Hauptseite aufrufen, dann die Einstellungen in der Docker-Engine ändern und das Bild durch das inländische Bild von Alibaba Cloud ersetzen:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}Dadurch lässt sich der Spiegel schneller herausziehen (für Privatanwender)
4. Ziehen Sie das Wechaty-Bild :
docker pull wechaty:0 . 65Denn beim Testen stellte sich heraus, dass die Version 0.65 von Wechaty am stabilsten ist
Nach dem Ziehen des Bildes:
Puppet : Wenn Sie Wechaty zum Entwickeln eines WeChat-Roboters verwenden möchten, müssen Sie einen Middleware-Puppet verwenden, um den Betrieb von WeChat zu steuern. Es gibt derzeit viele Arten von Puppet Der Vorteil von Puppet liegt in den verschiedenen Roboterfunktionen, die erreicht werden können. Wenn Sie beispielsweise möchten, dass Ihr Roboter Benutzer aus einem Gruppenchat wirft, müssen Sie Puppet unter dem Pad-Protokoll verwenden.
Beantragen Sie eine Verbindung: http://pad-local.com/#/login
Hinweis : Nachdem Sie ein Konto beantragt haben, erhalten Sie ein 7-Tage-Token.
Führen Sie nach der Beantragung des Tokens den folgenden Befehl im cmd-Fenster aus:
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
Parameterbeschreibung:
WECHATY_PUPPET_PADLOCAL_TOKEN : Beantragen Sie ein gutes Token
**WECHATY_TOKEN **: Schreiben Sie einfach eine zufällige Zeichenfolge, die garantiert eindeutig ist
WECHATY_PUPPET_SERVER_PORT : Docker-Server-Port
wechaty/wechaty:0.65 : Version des Wechaty-Bildes
Hinweis: - „8080:8080“* ist der Port Ihres lokalen Computers und Docker-Servers. Beachten Sie, dass der Docker-Server-Port mit WECHATY_PUPPET_SERVER_PORT übereinstimmen muss
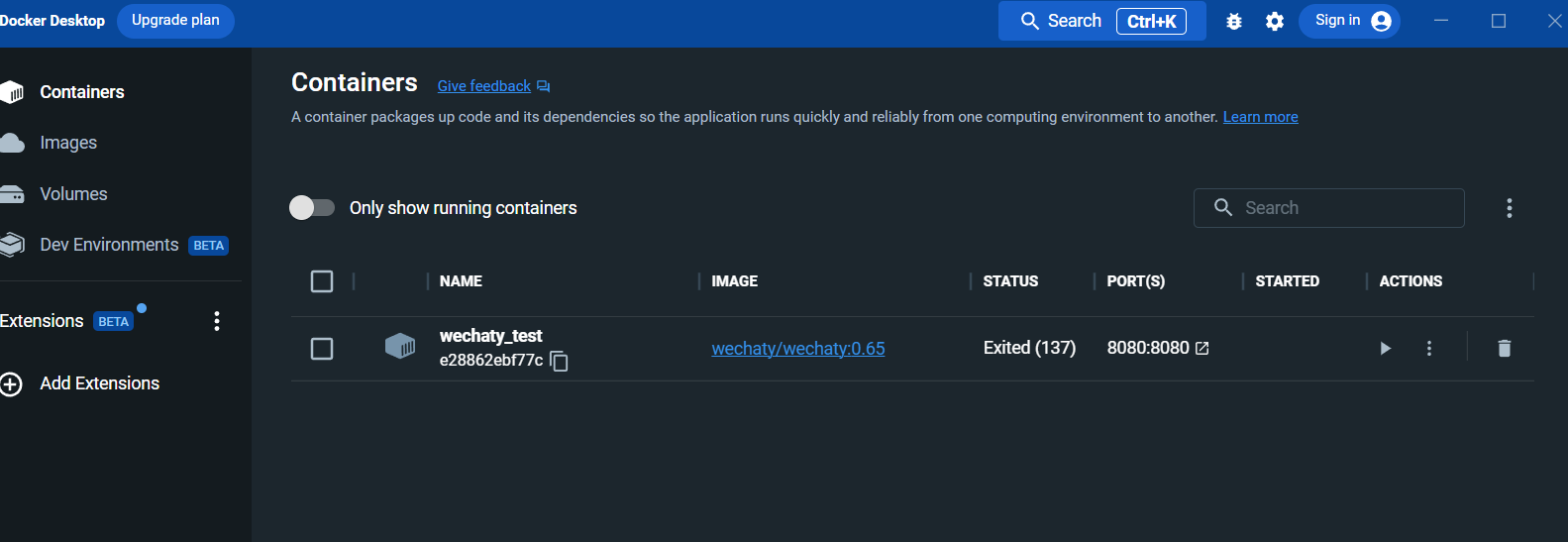
Sehen Sie sich nach der Ausführung den Container im Docker-Desktop-Bereich an:
Geben Sie die Protokollschnittstelle ein:
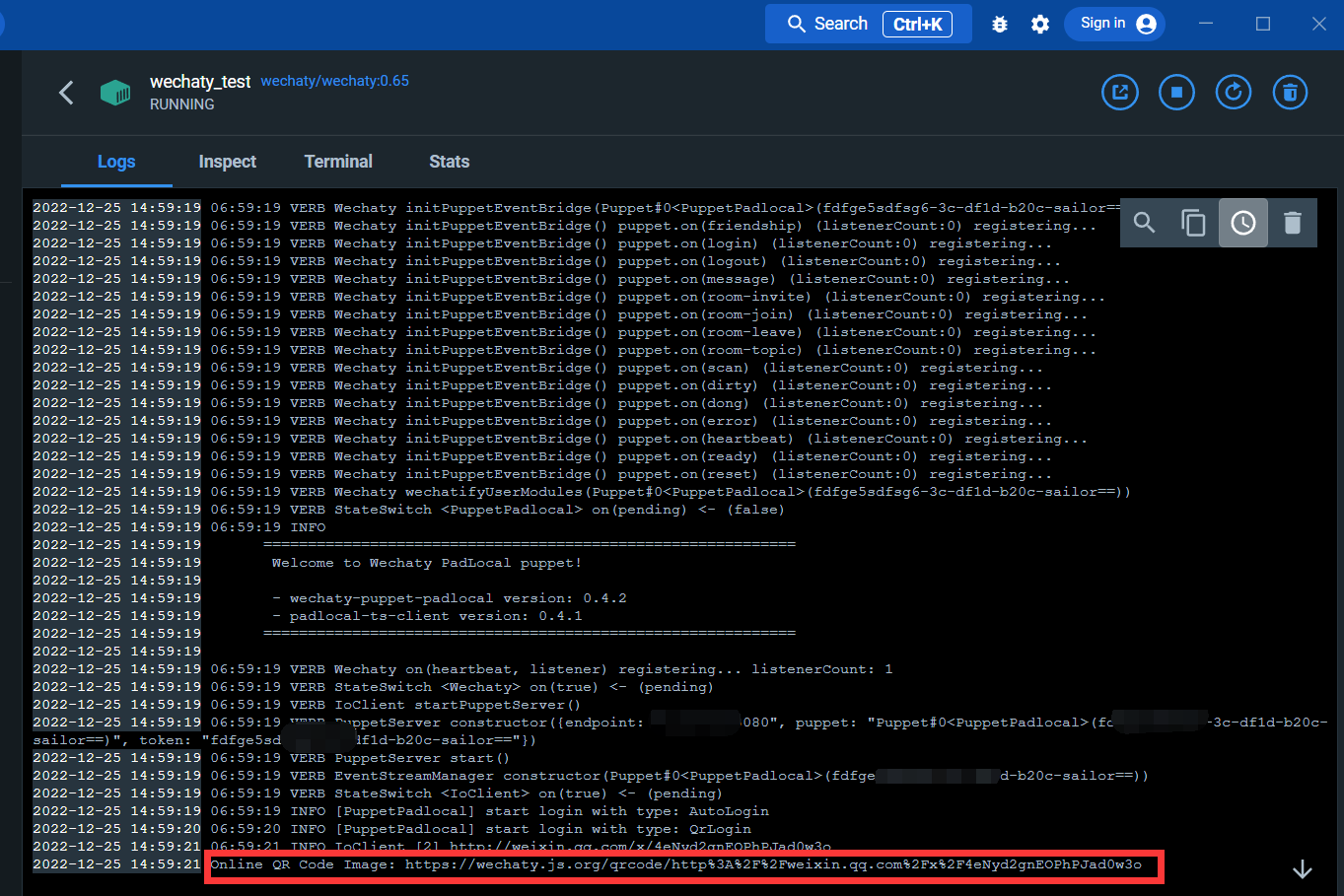
Über den untenstehenden Link können Sie den QR-Code scannen, um sich bei WeChat anzumelden
Nach der Anmeldung ist der Docker-Dienst abgeschlossen.
Installieren Sie die Bibliotheken wechaty und openai
Öffnen Sie cmd und führen Sie den folgenden Befehl aus:
pip install wechaty
pip install openaiMelden Sie sich bei openAI an
https://beta.openai.com/
Klicken Sie auf API-Schlüssel anzeigen
Holen Sie sich einfach API-Codes
An diesem Punkt wird die Umgebung eingerichtet
Sie können versuchen, diesen Democode zu lesen
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
Dieser Code ruft das CPT-3-Modell auf, das dasselbe Modell wie chatGPT ist, und der Antworteffekt ist ebenfalls gut.
Das GPT-3-Modell von openAI wird wie folgt eingeführt:
Unsere GPT-3-Modelle können natürliche Sprache verstehen und generieren. Wir bieten vier Hauptmodelle mit unterschiedlichen Leistungsstufen an, die für verschiedene Aufgaben geeignet sind, und Ada ist das schnellste.
| NEUESTES MODELL | BESCHREIBUNG | MAX. ANFRAGE | TRAININGSDATEN |
|---|---|---|---|
| text-davinci-003 | Das leistungsfähigste GPT-3-Modell kann jede Aufgabe erledigen, die die anderen Modelle erledigen können, oft mit höherer Qualität, längerer Ausgabe und besserer Befehlsfolge. Unterstützt auch das Einfügen von Vervollständigungen in Text. | 4.000 Token | Bis Juni 2021 |
| text-curie-001 | Sehr leistungsfähig, aber schneller und kostengünstiger als Davinci. | 2.048 Token | Bis Oktober 2019 |
| text-babbage-001 | Erledigt unkomplizierte Aufgaben, sehr schnell und zu geringeren Kosten. | 2.048 Token | Bis Oktober 2019 |
| text-ada-001 | Für sehr einfache Aufgaben geeignet, normalerweise das schnellste Modell der GPT-3-Serie und mit den niedrigsten Kosten. | 2.048 Token | Bis Oktober 2019 |
Während Davinci im Allgemeinen am leistungsstärksten ist, können die anderen Modelle bestimmte Aufgaben mit erheblichen Geschwindigkeits- oder Kostenvorteilen äußerst gut ausführen. Beispielsweise kann Curie viele der gleichen Aufgaben wie Davinci ausführen, jedoch schneller und zu einem Zehntel der Kosten.
Wir empfehlen die Verwendung von Davinci beim Experimentieren, da es die besten Ergebnisse liefert. Sobald Sie alles zum Laufen gebracht haben, empfehlen wir Ihnen, die anderen Modelle auszuprobieren, um zu sehen, ob Sie die gleichen Ergebnisse mit geringerer Latenz erzielen können. Möglicherweise können Sie auch das andere verbessern Sie können die Leistung von Modellen verbessern, indem Sie sie auf eine bestimmte Aufgabe abstimmen.
Kurz gesagt, das leistungsstärkste GPT-3-Modell. Kann alles, was andere Modelle können, normalerweise mit höherer Qualität, längerer Ausgabe und besserer Befolgung der Anweisungen. Das Einfügen von Vervollständigungen in Text wird ebenfalls unterstützt.
Obwohl das text-davinci-003-Modell direkt verwendet werden kann, um den Einrunden-Dialogeffekt von chatGPT zu erzielen, kann ein Dialogmodell entworfen werden, um den gleichen Mehrrunden-Dialogeffekt wie bei chatGPT zu erzielen.
Grundprinzip: Teilen Sie dem text-davinci-003-Modell den Kontext des aktuellen Gesprächs mit
Implementierungsmethode: Entwerfen Sie eine Dialogspeicherwarteschlange, um die ersten k Dialogrunden des aktuellen Dialogs zu speichern, und teilen Sie dem text-davinci-003-Modell den Inhalt der ersten k Dialogrunden mit, bevor Sie eine Frage stellen, und erhalten Sie dann die aktuelle Antwort durch den Inhalt des Modells text-davinci-003
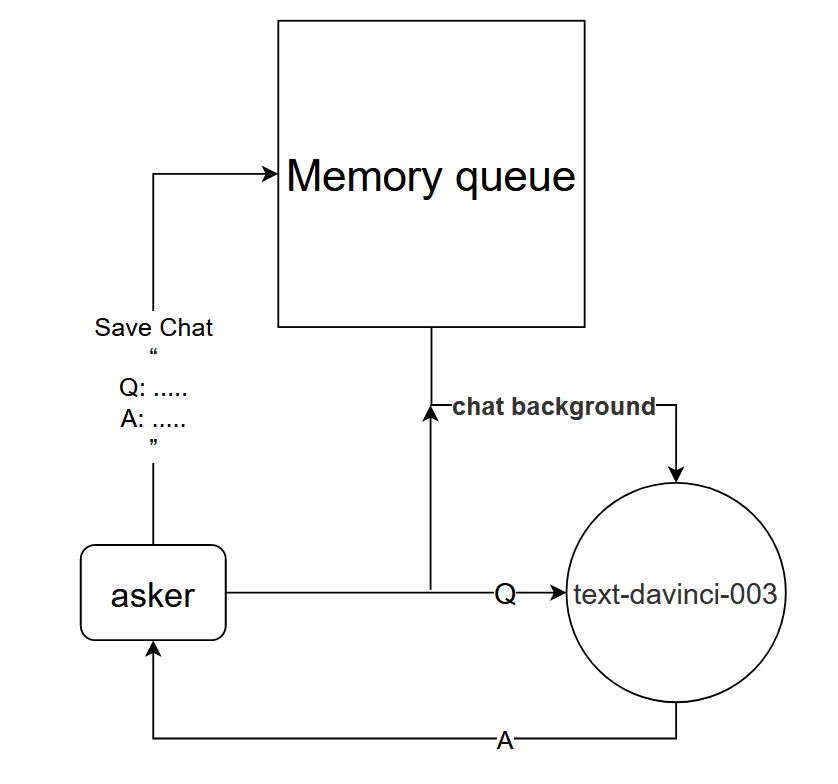
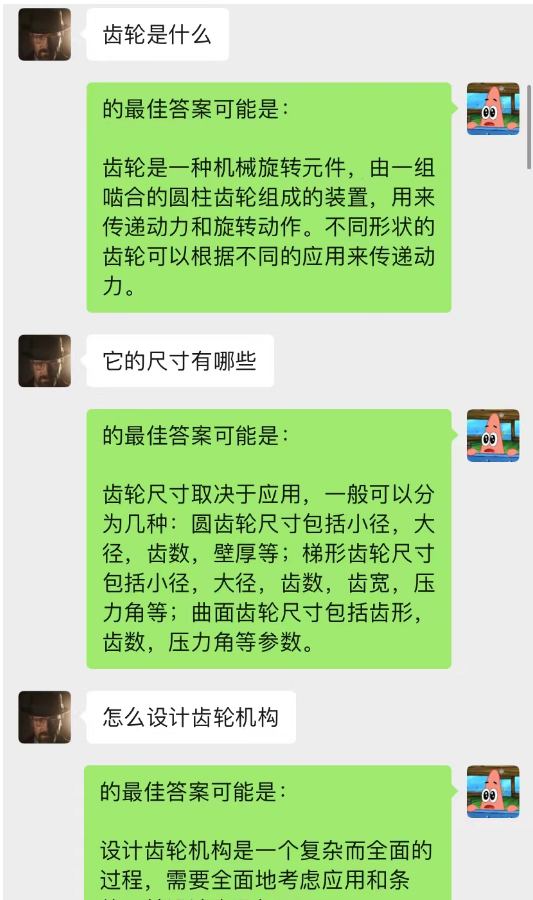
Diese Methode funktioniert überraschend gut! Geben Sie einige Chataufzeichnungen an
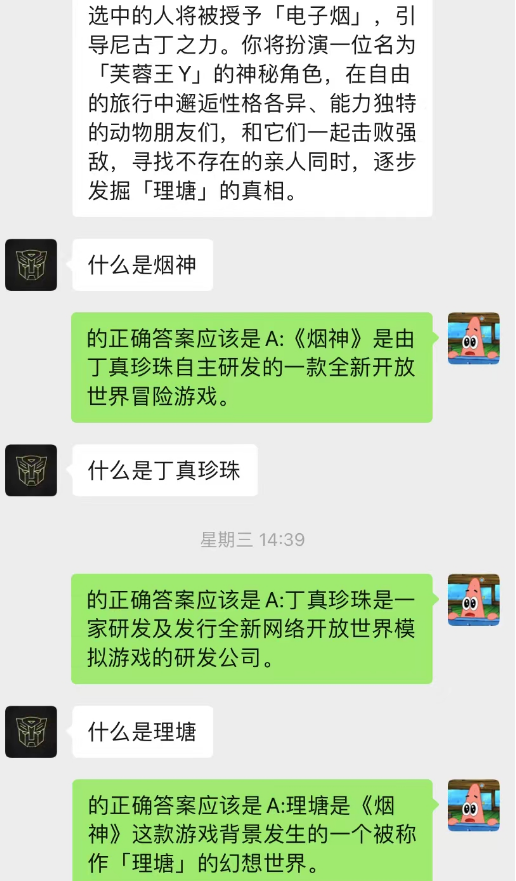
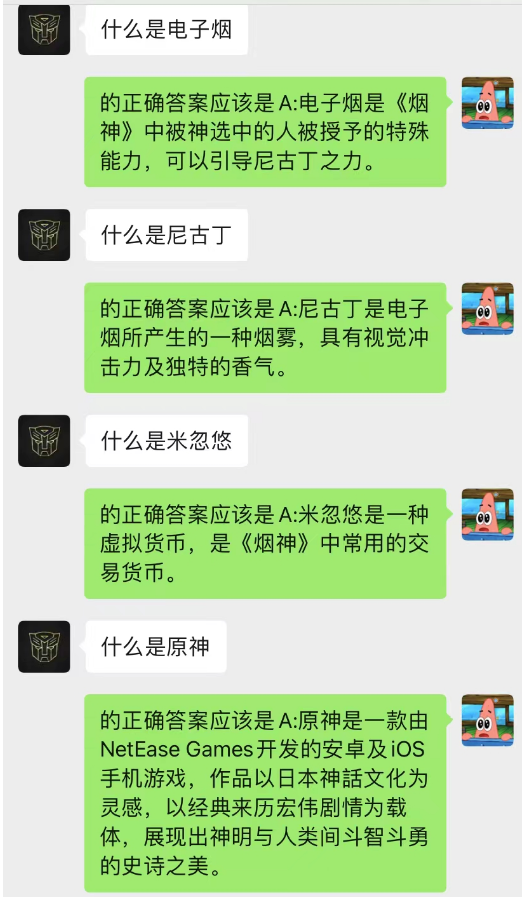
Es ist ersichtlich, dass der Chat-Hintergrund derzeit auch dazu verwendet werden kann, der KI das situative Lernen zu ermöglichen.
Darüber hinaus können Sie die gleiche geführte Artikelerstellung wie mit chatGPT erreichen.
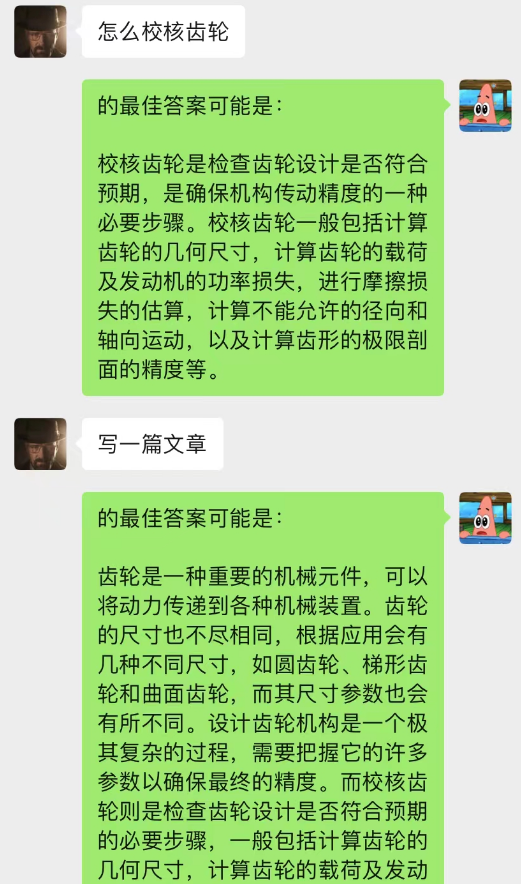
Dieses Modell ist eine Methode, die ich derzeit zur Optimierung des Chat-Backgroud-Dialogmodells entwerfe. Seine Grundlogik ist die gleiche wie beim N-Gramm-Sprachmodell, außer dass N dynamisch geändert wird und Markov-Eigenschaften hinzugefügt werden, um den aktuellen Dialog vorherzusagen Beurteilen Sie anhand des Kontexts, dass der Abschnitt im Chat-Hintergrund der wichtigste ist, und verwenden Sie dann das Modell text-davinci-003, um eine Antwort basierend auf dem wichtigsten gespeicherten Gesprächsinhalt und dem aktuellen Problem zu geben (entspricht dem Verlassen). KI (Machen Sie dies während des Chats und verwenden Sie dabei vorherige Chat-Inhalte.)
Die Implementierung dieses Modells erfordert eine große Datenmenge für das Training und der Code ist noch nicht fertiggestellt.
------ Digging : Aktualisieren Sie diesen Teil der detaillierten Schritte, nachdem der Code implementiert wurde
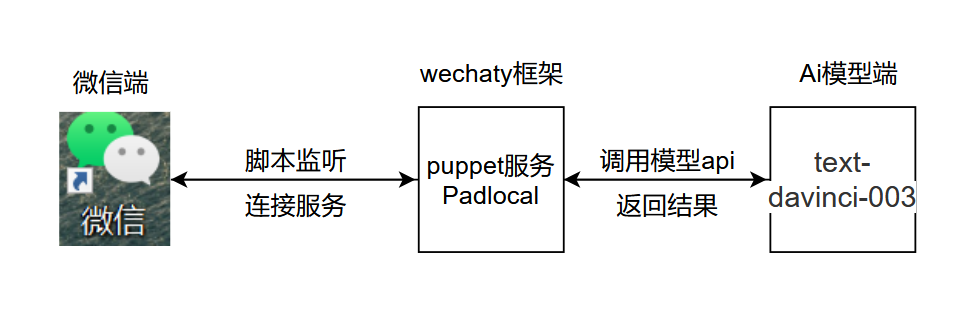
Die Grundlogik des Projekts ist in der folgenden Abbildung dargestellt:
 .py, fügen Sie chatGPT.py am angezeigten Speicherort hinzu und öffnen Sie es, fügen Sie den geheimen Schlüssel hinzu und konfigurieren Sie Umgebungsvariablen am angezeigten Speicherort
.py, fügen Sie chatGPT.py am angezeigten Speicherort hinzu und öffnen Sie es, fügen Sie den geheimen Schlüssel hinzu und konfigurieren Sie Umgebungsvariablen am angezeigten Speicherort

Code-Erklärung :
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
Erfolgreich ausgeführt
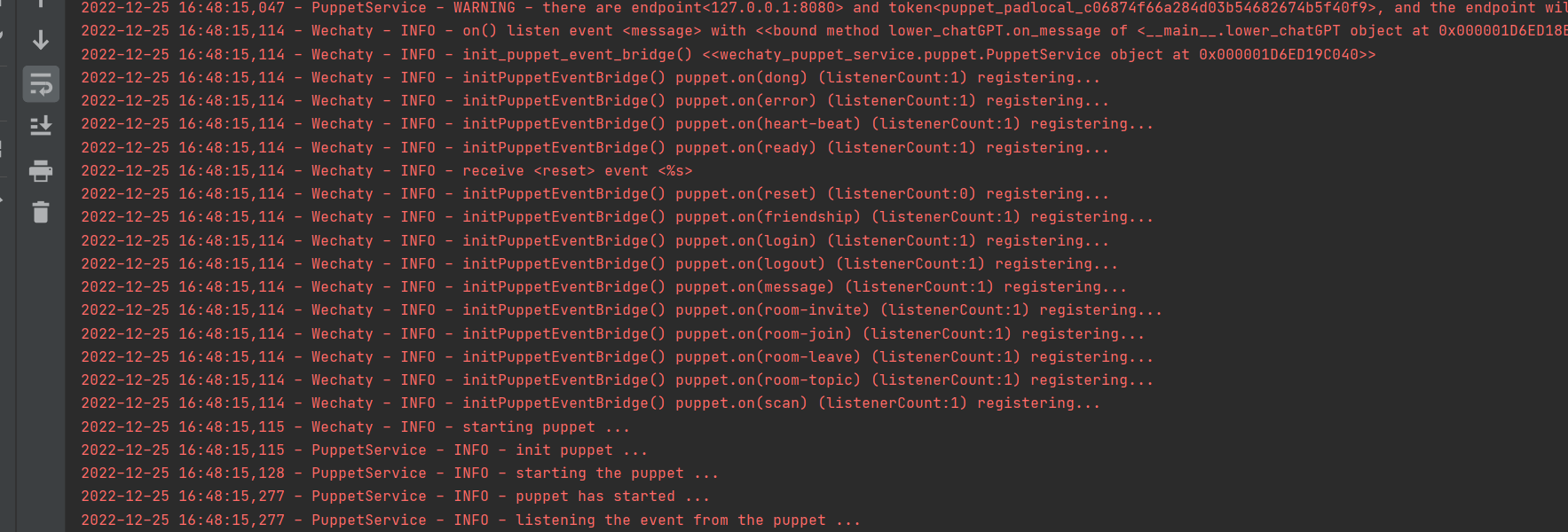
1. Melden Sie sich im Docker an, verwenden Sie nicht die Wechaty-Anmeldung in Python
2. Legen Sie time.sleep() im Code fest, um die Geschwindigkeit zu simulieren, mit der Personen auf Nachrichten antworten.
3. Es ist am besten, beim Testen keine große Größe zu verwenden. Es wird empfohlen, eine dedizierte kleine Größe für KI-Tests zu erstellen.
Der Inhalt dieses Projekts dient ausschließlich der technischen Forschung und der wissenschaftlichen Popularisierung und stellt keine schlüssige Grundlage dar. Es stellt keine Genehmigung für kommerzielle Anwendungen dar und ist für keinerlei Handlungen verantwortlich.
~~E-Mail: [email protected]


