glory admin
1.0.0
GloryAdmin ist ein Hintergrundframework, das auf springboot2.1.9.RELEASE und vue-admin-template basiert.
GloryAdmin verwendet eine rollenbasierte Berechtigungsverwaltung. Der Rollenbaum ist ein Baum mit „Systemadministrator“ als Stammknoten, und der Berechtigungsbaum besteht aus mehreren Unterberechtigungsbäumen. „Systemadministrator“ verfügt über alle Berechtigungen; Nicht-Systemadministratorrollen können die Informationen der aktuellen Rolle und der direkt untergeordneten Rollen anzeigen, aber nur die Informationen der direkt untergeordneten Rollen hinzufügen, löschen und ändern (direkte Untergebene: A ist die direkte). Untergeordneter von B, dann muss A der untergeordnete Knoten von B sein).
Glory-Admin
| Projekt | Technologie |
|---|---|
| Backend-Projekt | Springboot |
| Frontend-Projekt | Element-Benutzeroberfläche und Vue.js |
| Datenbank | MySQL |
| Cache | Redis |

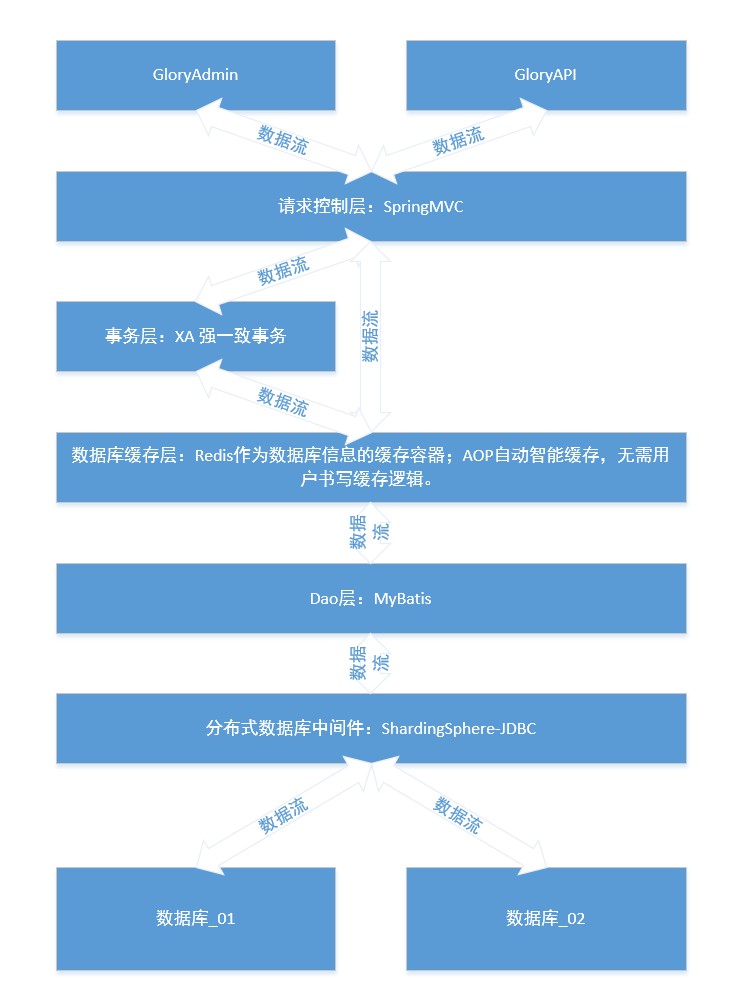
Dieses Projekt verwendet eine MySQL-Datenbank. Sie können das Datenbankskript verwenden, um zwei Datenbanken zu erstellen: multi_module_db multi_module_db_01
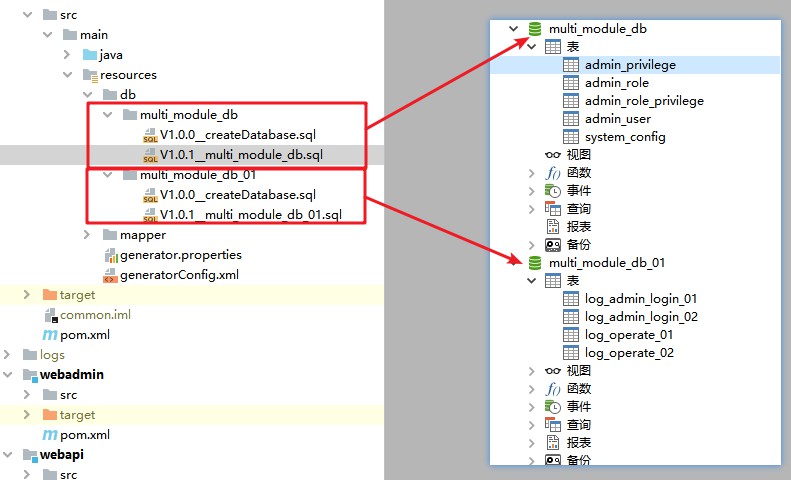
Starten Sie im Hintergrund und verwenden Sie Port 28081
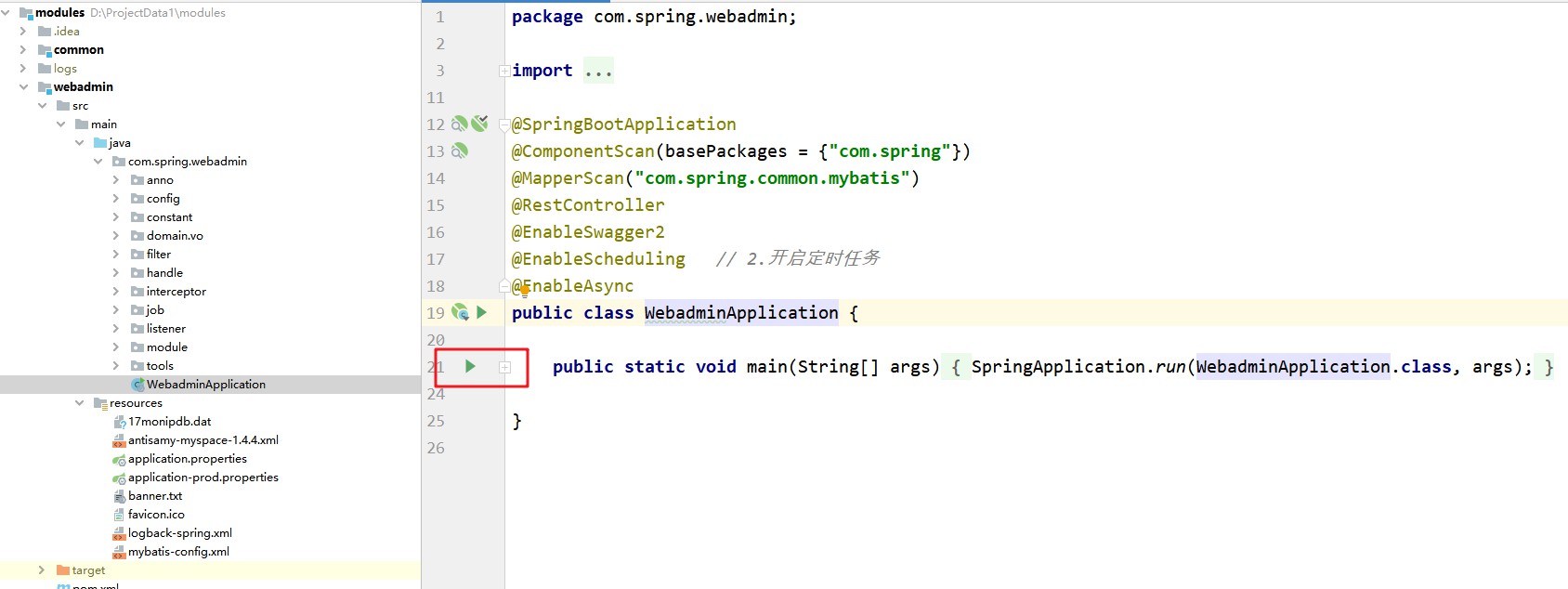
Starten Sie das Frontend und verwenden Sie Port 9523
Öffnen Sie den Browser und besuchen Sie http://localhost:9523 admin a123456
Die Essenz von Sharding oder Sharding ist das Scheitern des Mooreschen Gesetzes. Die Lösung, Daten zentral auf einem einzelnen Datenknoten zu speichern, war hinsichtlich Leistung, Verfügbarkeit sowie Betriebs- und Wartungskosten schwierig.
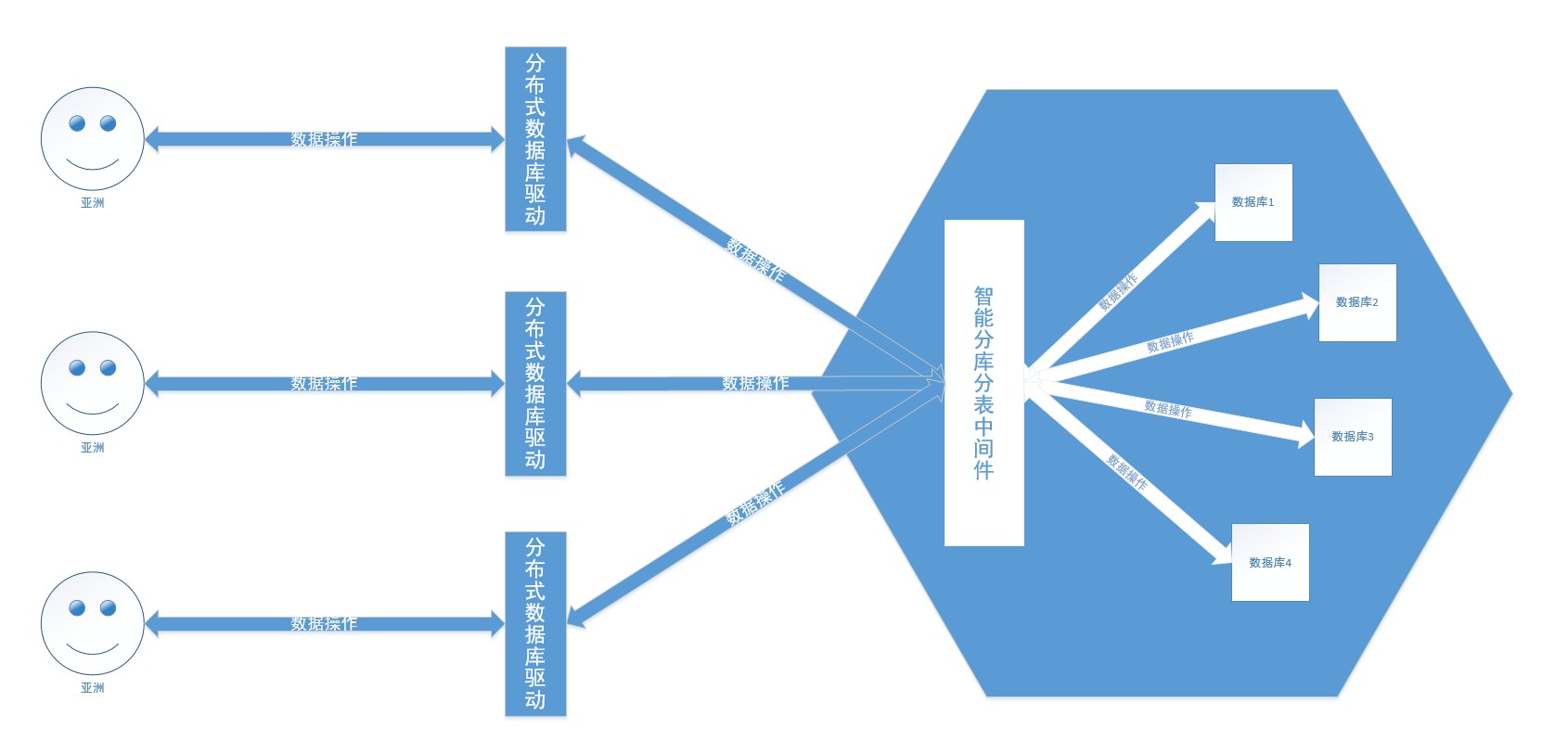
Eine einzelne Datenbank kann bestehende Unternehmen nicht unterstützen, daher sind Unterdatenbanken und Tabellen entstanden und mehrere Datenbanken werden zur Datenspeicherung verwendet. Das einfache Verständnis von Unterdatenbank und Untertabelle besteht darin, dass der Inhalt eines Korbs begrenzt ist, was sich auf die Sucheffizienz und -kapazität auswirkt. Der Inhalt des Korbs wird in N Teile unterteilt und in verschiedene Körbe gelegt. Dadurch werden Kapazitätsbeschränkungen aufgehoben und die Abfrageeffizienz verbessert.
Dann lassen Sie uns über verteilte Datenbanken sprechen. Zu den beliebtesten in China gehören TDSQL von Tencent, OceanBase von Alibaba, PolarDB, GaussDB von Huawei usw. Im Grunde werden sie unabhängig voneinander entwickelt, mit starker Konsistenz und hoher Verfügbarkeit, globaler Bereitstellungsarchitektur, verteilter unbegrenzter horizontaler Erweiterung, hoher Leistung, Hunderten von Milliarden Datensätzen und zeilen- und tabellenübergreifenden Transaktionen auf Hunderten von TB Daten (z. B das Mutterland) . Die verteilte Datenbank verbirgt die Strategie des Datenbank-Shardings und Tabellen-Shardings, teilt Daten intelligent in Datenbanken und Tabellen auf und verwendet sie wie den Betrieb einer Datenbank.
Da Speicheroperationen und Festplattenoperationen überhaupt nicht in der gleichen Größenordnung liegen, benötigen große Projekte eine speicherartige Pufferschicht für Festplattendatenbanken, um Festplattendaten im Speicher zwischenzuspeichern. Die Daten-Caching-Schicht wird zum Zwischenspeichern der Daten der gesamten Datenschicht verwendet, um den Zugriff auf die Website zu beschleunigen. Dieses Projekt nutzt die AOP-Technologie und die Redis-In-Memory-Datenbank als Daten-Cache-Schicht. Weitere Informationen finden Sie im Code com/spring/common/aop/CacheDaoAspect.java.
Dieses Projekt verwendet Sharding JDBC, um die Datenbank und Tabellen der Datenbank zu verarbeiten. Teilen Sie die Daten selbst nach Geschäftsszenarien auf.
Normalerweise verfügen Projekte nur über eine Datenbank, und der Druide von Alibaba Cloud wird in China häufiger als Datenbankverbindungspool verwendet. Dieses Projekt verwendet MySQL, Druid und Sharding JDBC. Das Prinzip des Daten-Shardings besteht darin , mehrere Datenbankverbindungspools im Programm zu verwalten, und jeder Datenbankverbindungspool entspricht einer Datenbank. Die Shard-Datenbank und die Shard-Tabellen verwenden eine zweiphasige Transaktionsverarbeitung basierend auf dem XA-Protokoll . Konfigurationspfad com.spring.common.config.shardingJDBC
Vertikale Aufteilung: Die Methode der Geschäftsaufteilung wird als vertikales Sharding oder auch als vertikale Aufteilung bezeichnet. Verteilen Sie Tabellen je nach Geschäft auf verschiedene Datenbanken und verteilen Sie so den Druck auf verschiedene Datenbanken.
Horizontale Aufteilung: Es kümmert sich nicht um die Klassifizierung der Geschäftslogik, sondern verteilt die Daten gemäß bestimmten Regeln über ein bestimmtes Feld (oder mehrere Felder) einer bestimmten Tabelle auf mehrere Bibliotheken oder Tabellen. Die Regeln hier und der beteiligte Algorithmus werden Sharding-Algorithmen genannt.
( Der folgende Inhalt stammt aus der ShardingJDBC-Dokumentation .)
Entspricht PreciseShardingAlgorithm und wird zur Handhabung des Szenarios von = und IN -Sharding unter Verwendung eines einzelnen Schlüssels als Sharding-Schlüssel verwendet. Muss mit StandardShardingStrategy verwendet werden.
Entspricht dem RangeShardingAlgorithm, der zur Handhabung von Sharding-Szenarien mit BETWEEN AND , > , < , >= und <= unter Verwendung eines einzelnen Schlüssels als Sharding-Schlüssel verwendet wird. Muss mit StandardShardingStrategy verwendet werden.
Entspricht dem ComplexKeysShardingAlgorithm, der zur Handhabung von Szenarien verwendet wird, in denen mehrere Schlüssel als Sharding-Schlüssel für das Sharding verwendet werden. Die Logik, die mehrere Sharding-Schlüssel enthält, ist komplex und Anwendungsentwickler müssen die Komplexität selbst bewältigen. Muss mit ComplexShardingStrategy verwendet werden.
Entspricht HintShardingAlgorithm und wird zur Behandlung von Szenarien verwendet, in denen Hint Zeilen-Sharding verwendet wird. Muss mit HintShardingStrategy verwendet werden.
Der Benutzer meldet sich an, um das Token zu erhalten und lokal zu speichern (adminLogin).
Der Benutzer sendet ein Token, um Benutzerinformationen und Berechtigungsinformationen zu erhalten, und speichert diese im Store. Da F5 zum Verlust des Speichers führt, wird der Front-End-Anfrage ein Interceptor hinzugefügt. Wenn keine Benutzerinformationen und Berechtigungsinformationen vorhanden sind, werden Benutzerinformationen und Berechtigungen erneut abgerufen (getAdminInfo).
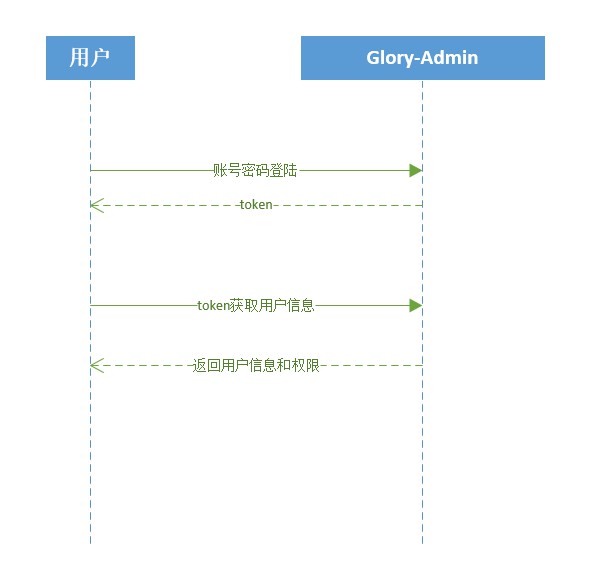
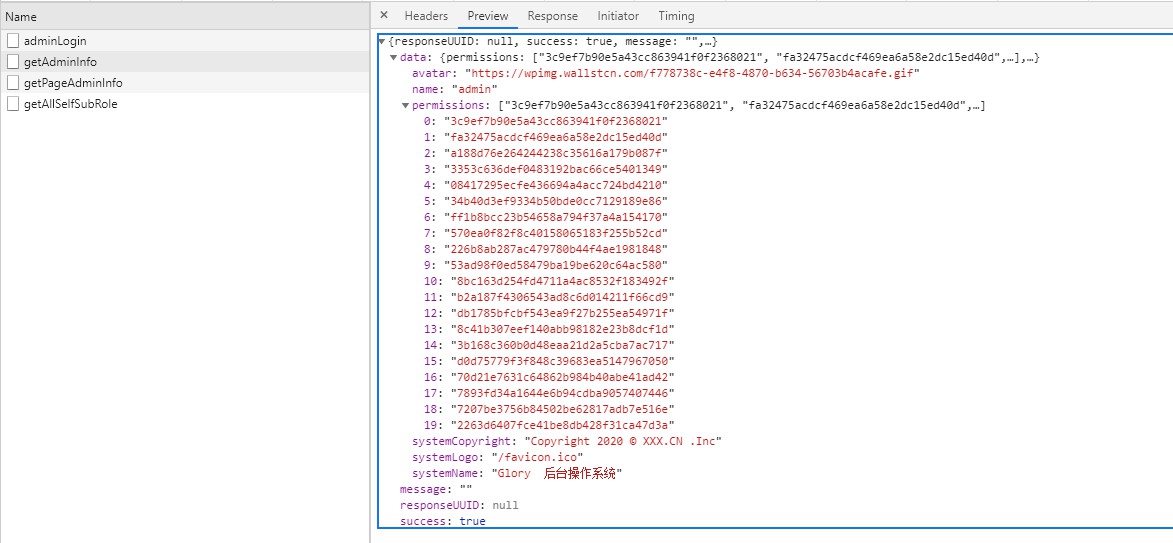
Hier werden alle Berechtigungen des Benutzers anstelle der Rolle zurückgegeben. Der Benutzer generiert dynamisch Front-End-Routen.
asyncRoutes ist eine dynamisch generierte Berechtigung. Wenn die Berechtigung des Benutzers der Berechtigung der Route entspricht, wird sie angezeigt.
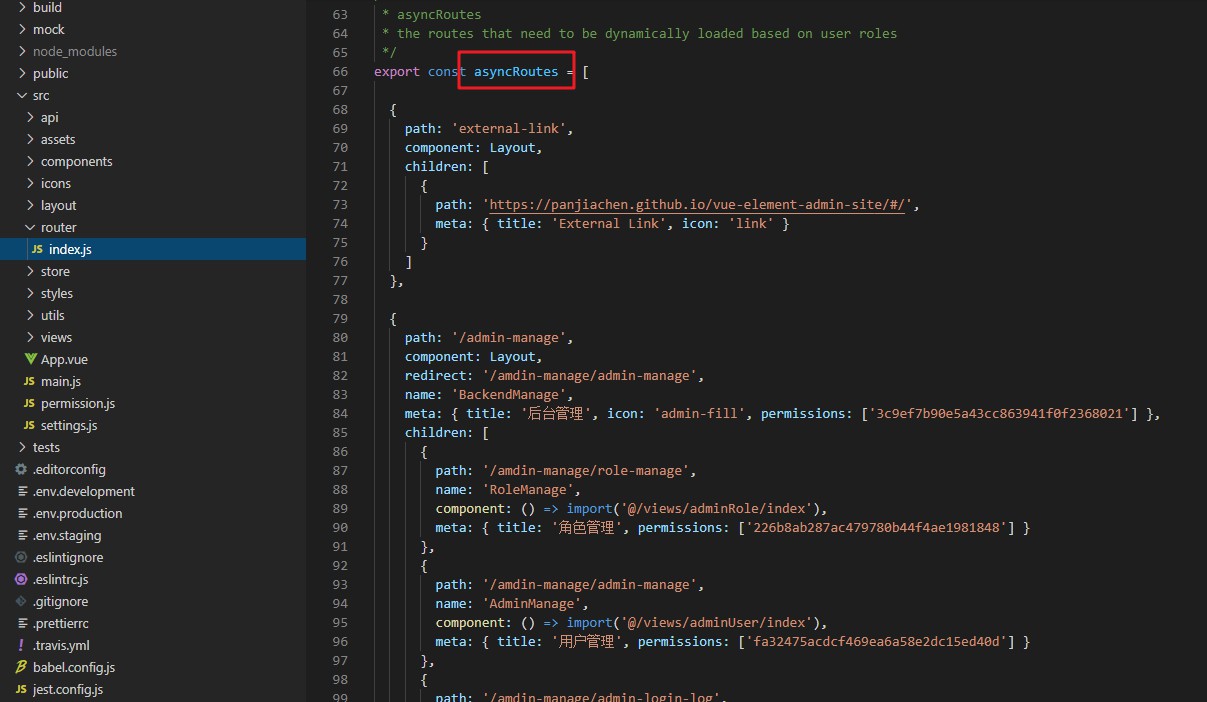
Häufig: Datenoperationen, Daten-Caching, Transaktionsoperationen
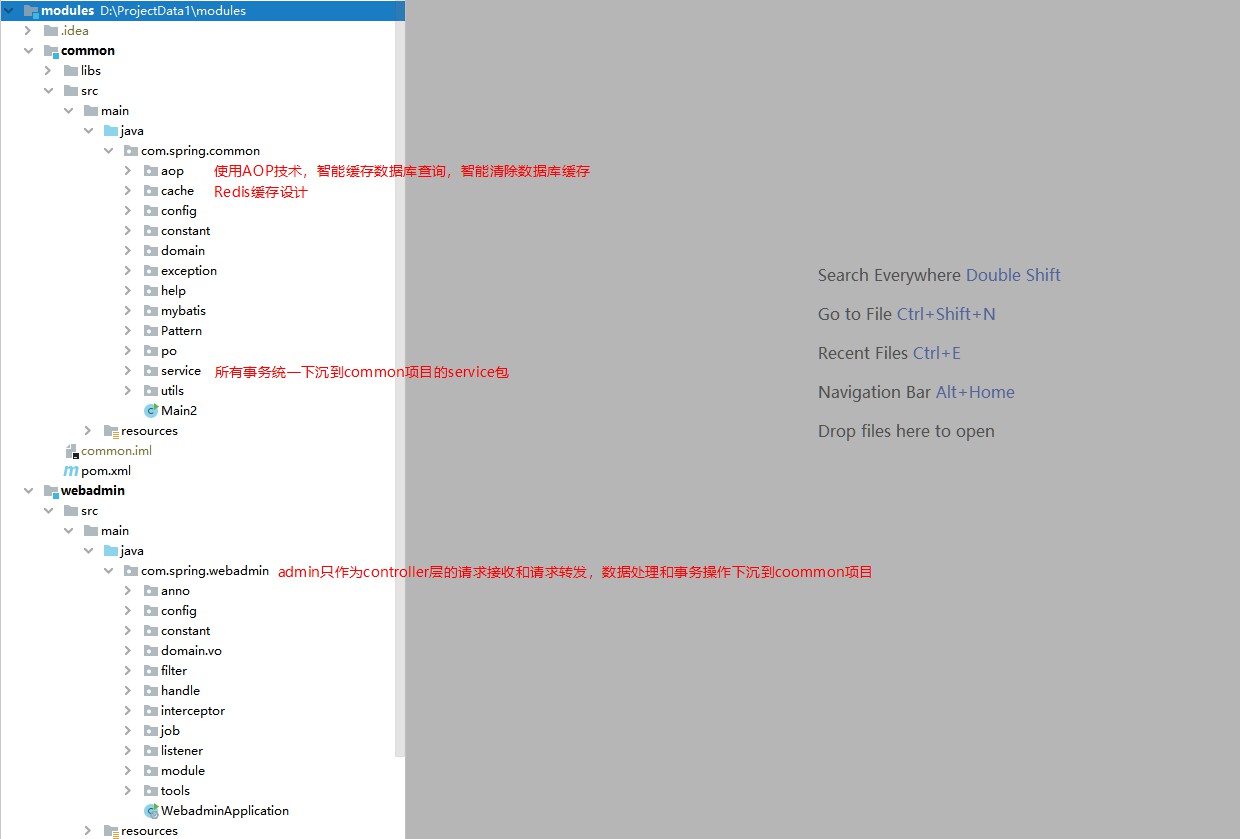
Der Administrator fungiert lediglich als Controller, der für die Weiterleitung zwischen Benutzeranfragen und Back-End-Geschäften zuständig ist. (Warum ist es so konzipiert?) Weil einige Middleware-Systeme das RPC-Framework für die Anforderungsweiterleitung verwenden müssen und einige vertrauliche Systeme die Verwendung von SpringMVC verachten und Vertx wählen, um die Anforderungsschicht unabhängig zu entwickeln.
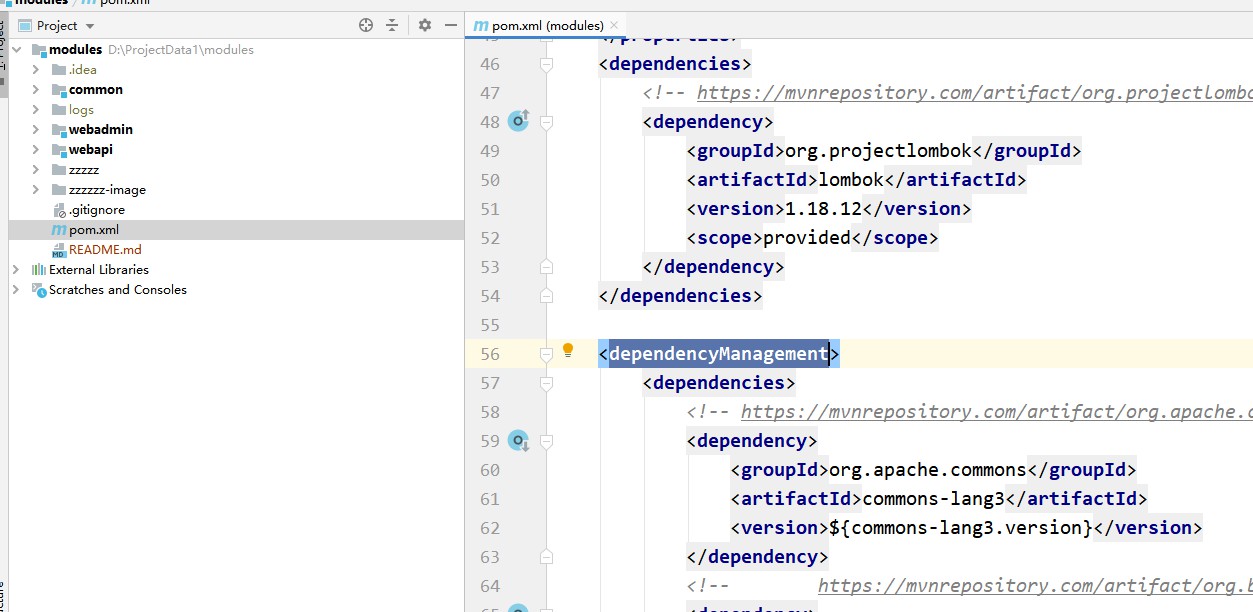
Verwenden Sie die Maven-Vererbung, um Projektabhängigkeiten zu verwalten. In Modulen werden Abhängigkeiten über dependencyManagement eingeführt und die Versionen werden angegeben. Unterprojekte erben Module und es ist nicht erforderlich, Versionen anzugeben, wenn Abhängigkeiten eingeführt werden.
Globale Protokollverarbeitung
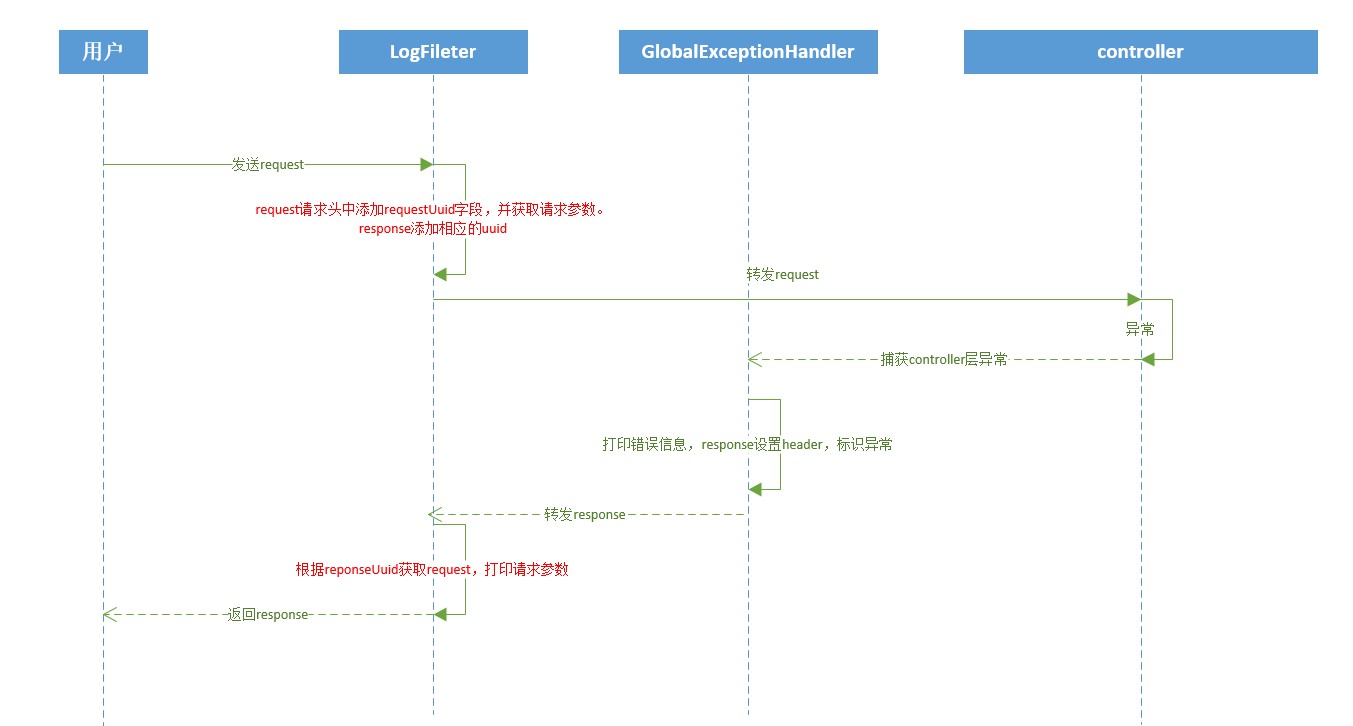
Benutzerbetriebsprotokolle verwenden Anmerkungsmethoden. Wenn diese Methode Betriebsprotokolle aufzeichnen muss, fügen Sie einfach die Annotation **@OperateLog** über dem Methodennamen hinzu.
@ OperateLog
@ ApiOperation ( value = "登出" , notes = "登出" )
@ GetMapping ( Route . Admin . adminLogout )
public ResponseDate adminLogout ( HttpServletRequest httpServletRequest ) {
AdminInfoDTO adminInfoDTO = AdminTool . getAdminUser ( httpServletRequest );
AdminUser adminUser = adminUserMapper . selectByPrimaryKey ( adminInfoDTO . getAdminUk ());
adminUser . setNowToken ( "log-out" );
int result = adminUserService . updateAdminToken ( adminUser );
return ResponseDate . builder ()
. success ( result == 1 )
. build ();
}

