whisper.cpp
v1.7.2
Stabil: v1.7.2 / Roadmap | FAQ
Hochleistungs-Inferenz von OpenAs Whisper Automatic Speech Recognition (ASR) Modell:
Unterstützte Plattformen:
Die gesamte hochrangige Implementierung des Modells ist in Whisper.H und Whisper.cpp enthalten. Der Rest des Codes ist Teil der ggml -Bibliothek für maschinelles Lernen.
Eine solche leichte Implementierung des Modells ermöglicht es, es einfach in verschiedene Plattformen und Anwendungen zu integrieren. Beispiel hier ist ein Video, das das Modell auf einem iPhone 13 -Gerät ausführt - vollständig offline, On -Device: whisper.objc
Sie können auch problemlos Ihre eigene Offline -Sprachassistentenantrag: Befehl erstellen
Auf Apple Silicon läuft die Inferenz über Metall vollständig auf der GPU:
Oder Sie können es sogar gerade im Browser laufen: Talk. Gasmus
Die Tensoroperatoren sind für Apple Silicon CPUs stark optimiert. Abhängig von der Berechnungsgröße werden Arm -Neon -Simd -Intrinsik oder CBLAs -Beschleunigungsroutinen verwendet. Letztere sind besonders effektiv für größere Größen, da das Beschleunigungsgerüst den in modernen Apple-Produkten erhältlichen AMX-Koprozessor mit Spezialzweck verwendet.
Erster Klon das Repository:
git clone https://github.com/ggerganov/whisper.cpp.gitNavigieren Sie in das Verzeichnis:
cd whisper.cpp
Laden Sie dann eines der im ggml -Format konvertierten Flüstermodelle herunter. Zum Beispiel:
sh ./models/download-ggml-model.sh base.enErstellen Sie nun das Hauptbeispiel und transkribieren Sie eine solche Audiodatei wie folgt:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav Für eine kurze Demo einfach run make base.en ::
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
Der Befehl lädt das base.en .wav ggml samples
Ausführliche Verwendungsanweisungen leiten Sie: ./main -h
Beachten Sie, dass das Hauptbeispiel derzeit nur mit 16-Bit-WAV-Dateien ausgeführt wird. Stellen Sie daher sicher, dass Sie Ihre Eingabe konvertieren, bevor Sie das Tool ausführen. Zum Beispiel können Sie ffmpeg wie folgt verwenden:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavWenn Sie einige zusätzliche Audio -Samples spielen möchten, rennen Sie einfach:
make -j samples
Dadurch wird ein paar weitere Audiodateien von Wikipedia heruntergeladen und sie über ffmpeg in ein 16-Bit-WAV-Format umgewandelt.
Sie können die anderen Modelle wie folgt herunterladen und ausführen:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| Modell | Scheibe | Mem |
|---|---|---|
| winzig | 75 MIB | ~ 273 MB |
| Base | 142 MIB | ~ 388 MB |
| klein | 466 MIB | ~ 852 MB |
| Medium | 1,5 Gib | ~ 2,1 GB |
| groß | 2.9 Gib | ~ 3,9 GB |
whisper.cpp unterstützt die ganzzahlige Quantisierung der Whisper ggml -Modelle. Quantisierte Modelle erfordern weniger Speicher- und Festplattenraum, und abhängig von der Hardware kann effizienter verarbeitet werden.
Hier sind die Schritte zum Erstellen und Verwenden eines quantisierten Modells:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav Bei Apple Silicon -Geräten kann die Encoder -Inferenz über den Kern -ML auf der Apple Neural Engine (ANE) ausgeführt werden. Dies kann zu einer signifikanten Beschleunigung führen-mehr als X3 schneller im Vergleich zur CPU-Ausführung. Hier finden Sie die Anweisungen zum Erstellen eines Kern -ML -Modells und der Verwendung mit whisper.cpp :
Installieren Sie Python -Abhängigkeiten, die für die Erstellung des Kern -ML -Modells benötigt werden:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools korrekt funktioniert, bestätigen Sie bitte, dass XCode installiert ist, und können Sie xcode-select --install ausführen, um die Befehlszeilen-Tools zu installieren.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper Generieren Sie ein Kern -ML -Modell. Verwenden Sie beispielsweise, um ein base.en -Modell zu generieren.
./models/generate-coreml-model.sh base.en Dadurch werden die models/ggml-base.en-encoder.mlmodelc erzeugt
Bauen Sie whisper.cpp mit Kern -ML -Unterstützung:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config ReleaseFühren Sie die Beispiele wie gewohnt aus. Zum Beispiel:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
Der erste Lauf auf einem Gerät ist langsam, da der ANE-Dienst das Kern-ML-Modell für ein Gerätespezifischer Format zusammenstellt. Die nächsten Läufe sind schneller.
Weitere Informationen zur Kern -ML -Implementierung finden Sie unter PR #566.
Auf Plattformen, die OpenVino unterstützen, können die Encoder-Inferenz auf OpenVino-unterstützten Geräten wie X86-CPUs und Intel GPUs (integriert und diskret) ausgeführt werden.
Dies kann zu einer erheblichen Beschleunigung der Encoder -Leistung führen. Hier finden Sie die Anweisungen zum Generieren des OpenVino -Modells und verwenden Sie es mit whisper.cpp :
Zunächst, Setup Python Virtual Env. und installieren Sie Python -Abhängigkeiten. Python 3.10 wird empfohlen.
Fenster:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux und MacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt Generieren Sie ein OpenVino -Encodermodell. Verwenden Sie beispielsweise, um ein base.en -Modell zu generieren.
python convert-whisper-to-openvino.py --model base.en
Dies erzeugt ggml-base.en-ccoder-openvino.xml/.bin ir-Modelldateien. Es wird empfohlen, diese in denselben Ordner wie ggml -Modelle zu verlegen, da dies der Standardort ist, den die OpenVino -Erweiterung zur Laufzeit durchsucht.
Bauen Sie whisper.cpp mit OpenVino -Unterstützung:
Laden Sie das OpenVino -Paket von der Release -Seite herunter. Die empfohlene Version ist 2023.0.0.
Setzen Sie nach dem Herunterladen und Extrahieren von Paket in Ihr Entwicklungssystem die erforderliche Umgebung ein, indem Sie das SetupVARS -Skript beschaffen. Zum Beispiel:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batUnd dann das Projekt mit CMake erstellen:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config ReleaseFühren Sie die Beispiele wie gewohnt aus. Zum Beispiel:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
Das erste Mal auf einem OpenVino-Gerät ist langsam, da das OpenVino-Framework das IR-Modell (Intermediate Repräsentation) in einem Gerätsspezifischen "Blob" kompiliert. Dieser Gerätsspezifische Blob wird für den nächsten Lauf zwischengespeichert.
Weitere Informationen zur Kern -ML -Implementierung finden Sie unter PR #1037.
Bei NVIDIA -Karten erfolgt die Verarbeitung der Modelle über Cublas und benutzerdefinierte Cuda -Kerne effizient auf der GPU. Stellen Sie zunächst sicher, dass Sie cuda installiert haben: https://developer.nvidia.com/cuda-downloads
Bauen Sie jetzt whisper.cpp mit CUDA -Unterstützung:
make clean
GGML_CUDA=1 make -j
Cross-Vendor-Lösung, mit der Sie die Arbeitsbelastung auf Ihrer GPU beschleunigen können. Stellen Sie zunächst sicher, dass Ihr Grafikkartentreiber die Vulkan -API unterstützt.
Bauen Sie jetzt whisper.cpp mit vulkanunterstützung:
make clean
make GGML_VULKAN=1 -j
Die Encoder -Verarbeitung kann über Openblas auf der CPU beschleunigt werden. Stellen Sie zunächst sicher, dass Sie openblas installiert haben: https://www.openblas.net/
Erstellen Sie jetzt whisper.cpp mit Openblas -Unterstützung:
make clean
GGML_OPENBLAS=1 make -j
Die Encoder -Verarbeitung kann über die BLAS -kompatible Schnittstelle der Mathematikkernbibliothek von Intel auf der CPU beschleunigt werden. Stellen Sie zunächst sicher, dass Sie die MKL-Laufzeit- und Entwicklungspakete von Intel installiert haben: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-download.html
Erstellen Sie nun whisper.cpp mit Intel MKL Blas -Unterstützung:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPU bietet Inferenzbeschleunigung über CANN und KI -Kerne.
Überprüfen Sie zunächst, ob Ihr Ascend NPU -Gerät unterstützt wird:
Verifizierte Geräte
| NPU aufsteigen | Status |
|---|---|
| Atlas 300T A2 | Unterstützung |
Stellen Sie dann sicher, dass Sie CANN toolkit installiert haben. Die dauerte Version von Cann wird empfohlen.
Bauen Sie nun whisper.cpp mit Cann Support:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
Führen Sie beispielsweise die Inferenzbeispiele wie gewohnt aus:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
Anmerkungen:
Verified devices Tabelle. Für dieses Projekt stehen zwei Docker -Bilder zur Verfügung:
ghcr.io/ggerganov/whisper.cpp:main : Dieses Bild enthält die wichtigste ausführbare Datei sowie curl und ffmpeg . (Plattformen: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : Wie main , aber mit CUDA-Unterstützung zusammengestellt. (Plattformen: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Sie können vorgefertigte Binärdateien für whisper.cpp installieren oder es mit Conan aus der Quelle erstellen. Verwenden Sie den folgenden Befehl:
conan install --requires="whisper-cpp/[*]" --build=missing
Ausführliche Anweisungen zur Verwendung von Conan finden Sie in der Conan -Dokumentation.
Hier ist ein weiteres Beispiel für die Transkription einer 3:24 -minütigen Rede in etwa einer halben Minute auf einem MacBook M1 Pro mit medium.en -Modell:
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
Dies ist ein naives Beispiel für die Durchführung von Echtzeit-Inferenz in Audio aus Ihrem Mikrofon. Das Stream -Tool zeichnet die Audio alle halbe Sekunde lang ab und führt die Transkription kontinuierlich aus. Weitere Informationen finden Sie in Ausgabe Nr. 10.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 Das Hinzufügen des Arguments --print-colors -Argument wird den transkribierten Text unter Verwendung einer experimentellen Farbcodierungsstrategie drucken, um Wörter mit hohem oder geringem Vertrauen hervorzuheben:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors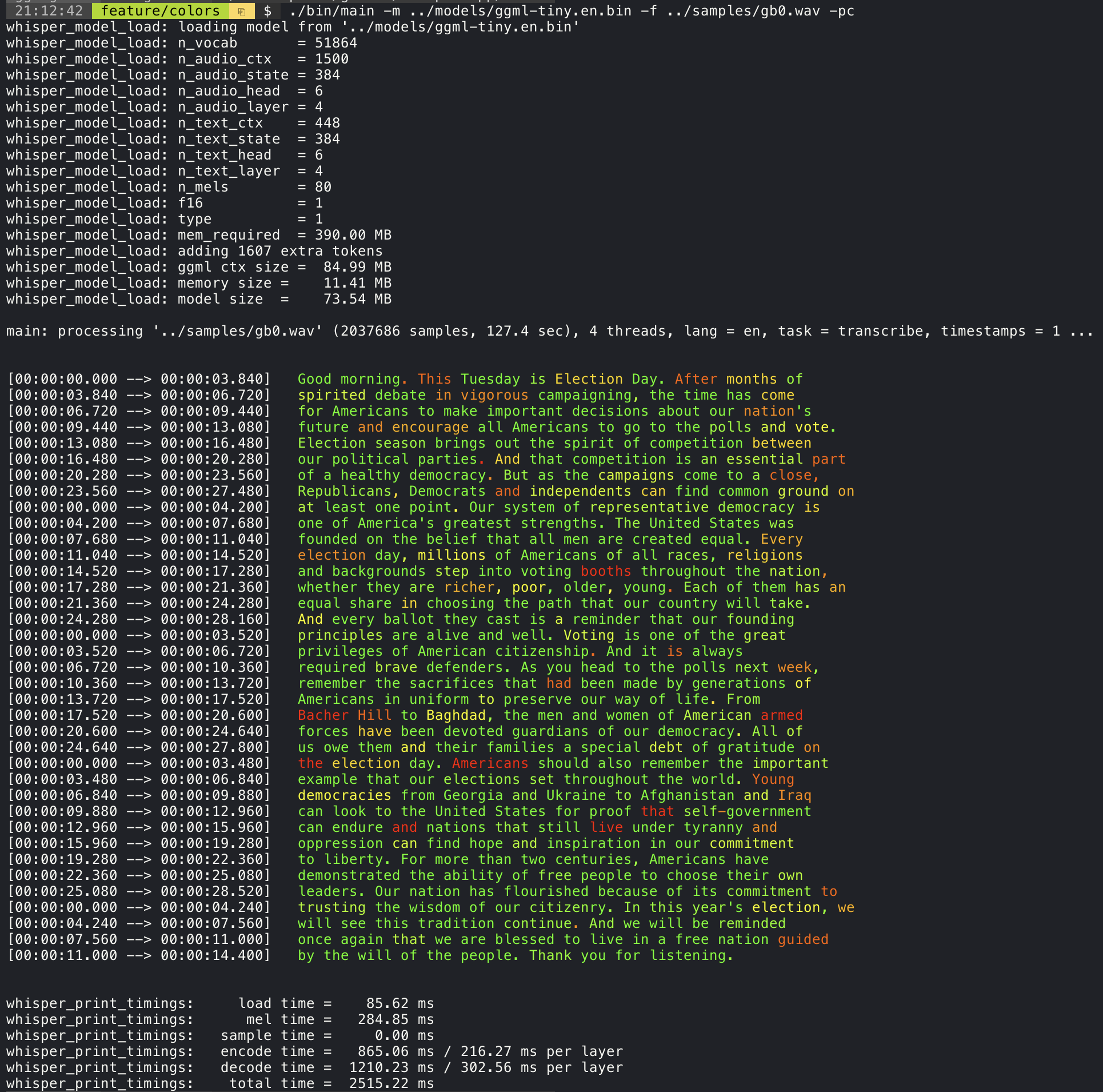
Um die Zeilenlänge beispielsweise auf maximal 16 Zeichen zu begrenzen, fügen Sie einfach -ml 16 hinzu:
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
Das Argument --max-len kann verwendet werden, um Zeitstempel auf Wortebene zu erhalten. Verwenden Sie einfach -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
Weitere Informationen zu diesem Ansatz finden Sie hier: #1058
Stichprobenverbrauch:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . Das Hauptbeispiel bietet Unterstützung für die Ausgabe von Filmen im Karaoke-Stil, in denen das derzeit ausgesprochene Wort hervorgehoben wird. Verwenden Sie das Argument -wts und führen Sie das generierte Bash -Skript aus. Dies erfordert, dass ffmpeg installiert ist.
Hier sind einige "typische" Beispiele:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4Verwenden Sie das Skripts/Bank-wts.sh-Skript, um ein Video im folgenden Format zu generieren:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4Um einen objektiven Vergleich der Leistung der Inferenz über verschiedene Systemkonfigurationen hinweg zu haben, verwenden Sie das Bank -Tool. Das Tool führt einfach den Encoder -Teil des Modells aus und druckt, wie viel Zeit für die Ausführung in Anspruch genommen wurde. Die Ergebnisse sind in der folgenden Github -Ausgabe zusammengefasst:
Benchmark -Ergebnisse
Zusätzlich wird ein Skript zum Ausführen von flüstertem.cpp mit verschiedenen Modellen und Audio -Dateien erhalten Bank.py.
Sie können es mit dem folgenden Befehl ausführen, standardmäßig wird es mit jedem Standardmodell im Modelsordner ausgeführt.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2Es ist in Python mit der Absicht geschrieben, leicht zu ändern und für Ihr Benchmarking -Anwendungsfall zu ändern.
Es gibt eine CSV -Datei mit den Ergebnissen des Benchmarkings aus.
ggml -FormatDie ursprünglichen Modelle werden in ein benutzerdefiniertes binäres Format umgewandelt. Auf diese Weise können Sie alles in eine einzelne Datei einpacken:
Sie können die konvertierten Modelle mit den Modellen/Download-ggml-model.sh-Skript oder manuell herunterladen:
Weitere Informationen finden Sie in den Konvertierungsskriptmodellen/konvert-pt-zu-ggml.py oder models/readme.md.
Es gibt verschiedene Beispiele für die Verwendung der Bibliothek für verschiedene Projekte im Beispiel -Ordner. Einige der Beispiele werden sogar so portiert, dass sie im Browser mithilfe von WebAssembly ausgeführt werden. Schau sie dir an!
| Beispiel | Netz | Beschreibung |
|---|---|---|
| hauptsächlich | flüster.wasmus | Werkzeug zum Übersetzen und Transkriptieren von Audio mit Flüstern |
| Bank | Bank. Gasmus | Benchmarkmarke die Leistung von Flüstern auf Ihrer Maschine |
| Strom | stream.wasmus | Echtzeit-Transkription von Roh-Mikrofoneinnahmen |
| Befehl | Befehl. Gasmus | Basis -Sprachassistentenbeispiel für den Empfang von Sprachbefehlen vom Mikrofon |
| wchess | wchess.wasmus | Sprachgesteuerter Schach |
| sprechen | Talk. Gasmus | Sprechen Sie mit einem GPT-2-Bot |
| Talk-Llama | Sprechen Sie mit einem Lama -Bot | |
| flüster.objc | iOS -mobile Anwendung mit flüster.cpp | |
| flüster.swiftui | Swiftui iOS / macOS -Anwendung mit wihsper.cpp | |
| flüster.android | Android -mobile Anwendung mit flüster.cpp | |
| flüster.nvim | Rede-to-Text-Plugin für Neovim | |
| generate-karaoke.sh | Helfer -Skript, um einfach ein Karaoke -Video von Raw Audio Capture zu generieren | |
| livestream.sh | Livestream -Audio -Transkription | |
| yt-wsp.sh | Download + transkribieren und/oder übersetzen Sie VOD (Original) | |
| Server | HTTP-Transkriptionsserver mit OAI-ähnlicher API |
Wenn Sie ein Feedback zu diesem Projekt haben, können Sie den Abschnitt Diskussionen verwenden und ein neues Thema eröffnen. Sie können mit der Kategorie "Sendung" angeben, Ihre eigenen Projekte zu teilen, die whisper.cpp verwenden. Wenn Sie eine Frage haben, überprüfen Sie die häufig gestellten Fragen (Nr. 126).


