Entwickeln Sie die REST -API, um die maschinelle Übersetzung mit dem SEQ2SEQ -Modell durchzuführen. Die Modellbereitstellung erfolgt über die Plattform von Google, die Plattform hat.
Projekt wird erstellt mit:
Die Daten für dieses Projekt sind als Textdatei auf der Datenquelle verfügbar, wobei jede Zeile einen Satz in Kannada und die Übersetzung davon auf Englisch mit Platzgrenzwert hat. Wir haben manuell zufällig verifiziert, um sicherzustellen, dass jedes Beispiel Sinn ergab.
Zuerst erstellen wir das Encoder -Decoder -Modell mit Aufmerksamkeitsmechanismus unter Verwendung von Gru Rnn. Das Training wurde mit dem hier verfügbaren Python -Skript durchgeführt
Erstellen Sie eine Flask -Anwendung, die vom lokalen Computer unter der Adresse http://127.0.0.1:5000/Predict zugreifen kann.
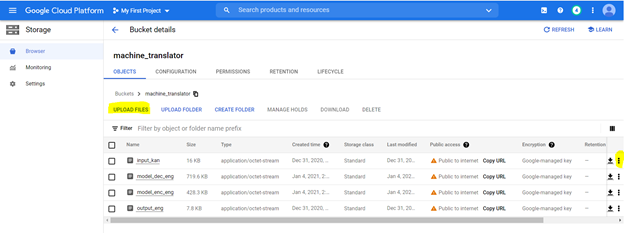
Wir werden das Skript verwenden, um das Modell zu trainieren. Nach dem Training des Modells speichern wir die Modellgewichte in einer .PT -Datei und speichern im Google Cloud -Speicher. Wir bauen auch das Vokabular -Wörterbuch auf, indem wir jedes Wort zu einer Nummer indexieren und sie einweichen. Diese Pickle -Dateien werden auch in der Speicherdatei gespeichert. Sobald diese Dateien vorhanden sind, können Sie darauf zugreifen
Wir werden die Dateien auf einem Speicherkorb hochladen. So erstellen Sie einen Eimer mit den folgenden Optionen, die mit den folgenden Spezifikationen hervorgehoben werden
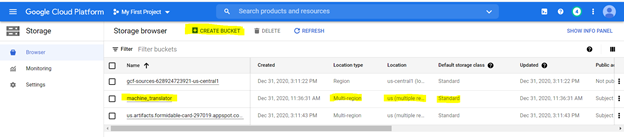
Um die Cloud -Funktion zu erstellen, durchsuchen Sie sie auf der GCP -Plattform und verwenden Sie die unten hervorgehobenen Optionen, um eine Funktion zu erstellen.
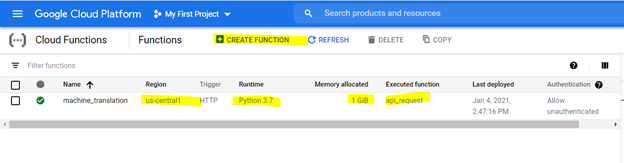
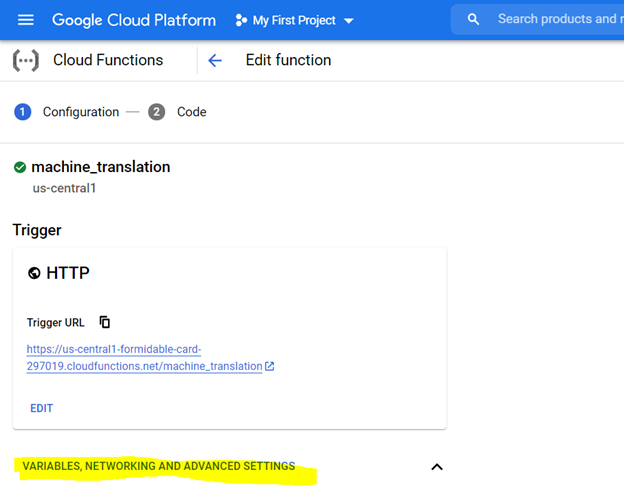
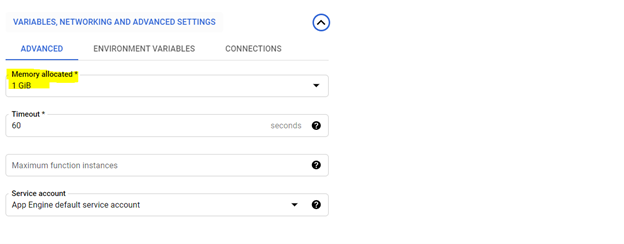
*Die Zuweisung von 1 GIB -Speicher wird empfohlen. Klicken Sie nach der Einstellung auf "Weiter" und stellen Sie den Code in der Cloud -Funktionskonsole bereit.
Konfigurieren Sie zum Bereitstellen des Code
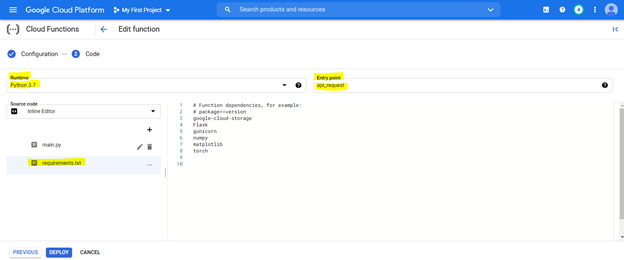
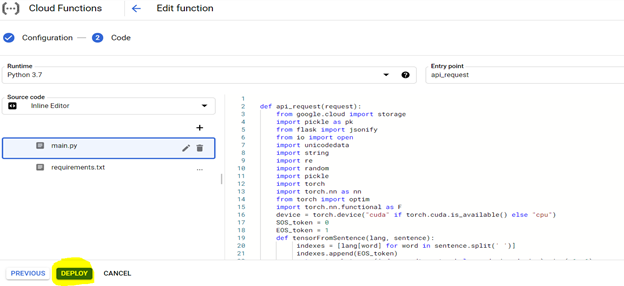

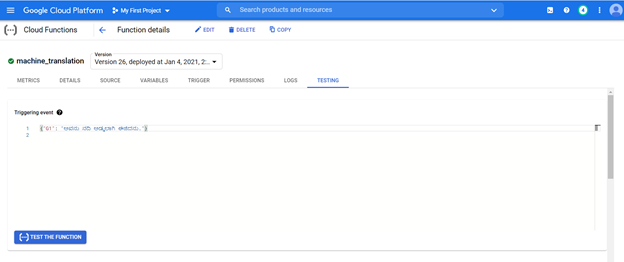

Auf das bereitgestellte Modell kann von der URL von jedem System zugegriffen werden, um Kannada -Sätze in Englisch zu übersetzen.


