
Die offizielle Implementierung von GFT, einem Cross-Domain-Cross-Task-Foundation-Modell für Diagramme. Das Logo wird von Dall · e 3 erzeugt.
Verfasst von Zehong Wang, Zheyuan Zhang, Nitesh gegen Chawla, Chuxu Zhang und Yanfang Ye.
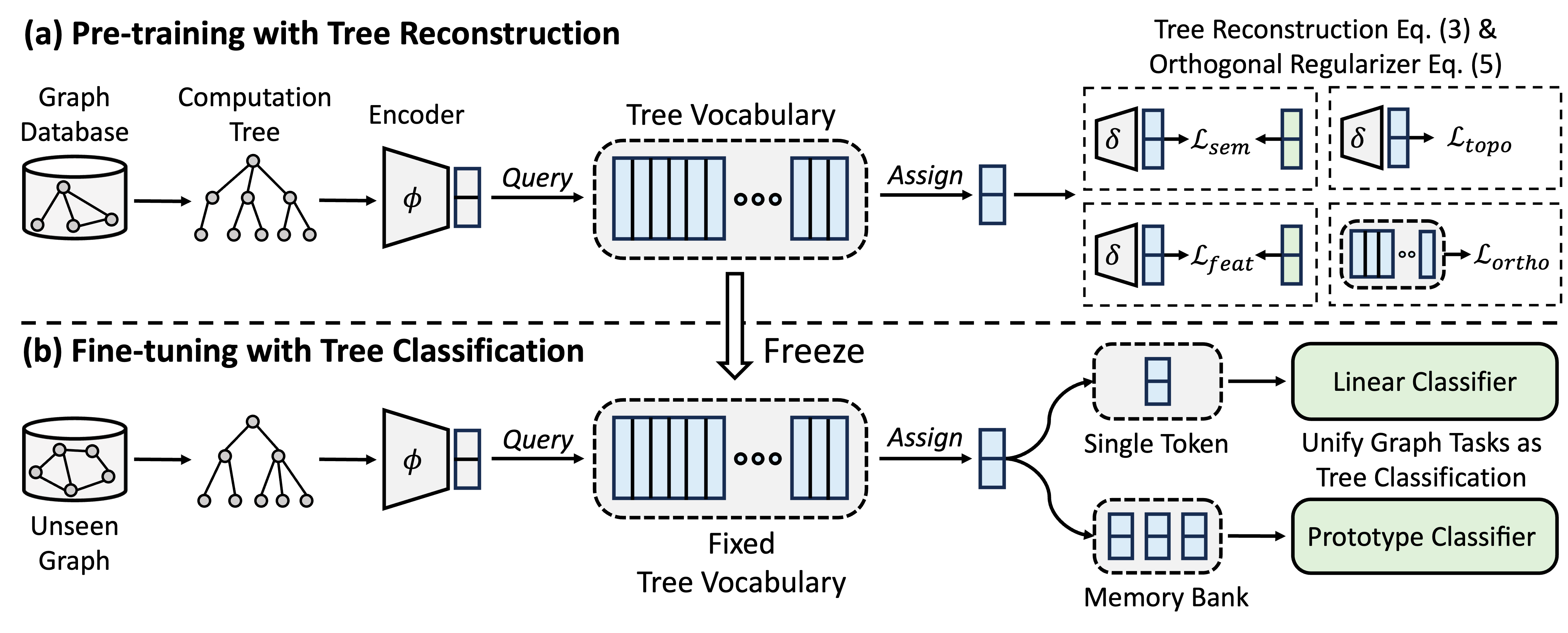
GFT ist ein Cross-Domain- und Cross-Task-Graph Foundation-Modell, das Berechnungsbäume als übertragbare Muster behandelt, um einen übertragbaren Baumvokabular zu erhalten. Darüber hinaus bietet GFT ein einheitliches Framework zum Ausrichten von Diagrammaufgaben und ermöglicht ein einzelnes Graphenmodell, z.
Während der Vorausbildung codiert das Modell Allgemeinwissen aus einer Diagrammdatenbank in ein Baumvokabular durch eine Baumrekonstruktionsaufgabe. Bei der Feinabstimmung wird das gelernte Baumvokabular angewendet, um die Aufgaben der graphischen Aufgaben als Baumklassifizierungsaufgaben zu vereinen, wodurch das erworbene allgemeine Wissen an bestimmte Aufgaben angepasst wird.
Sie können Conda verwenden, um die Umgebung zu installieren. Bitte führen Sie das folgende Skript aus. Wir führen alle Experimente an einer einzelnen A40 48G-GPU durch, doch eine GPU mit 24 g Speicher reicht aus, um alle Datensätze mit Mini-Batch zu verarbeiten.
conda env create -f environment.yml
conda activate GFT
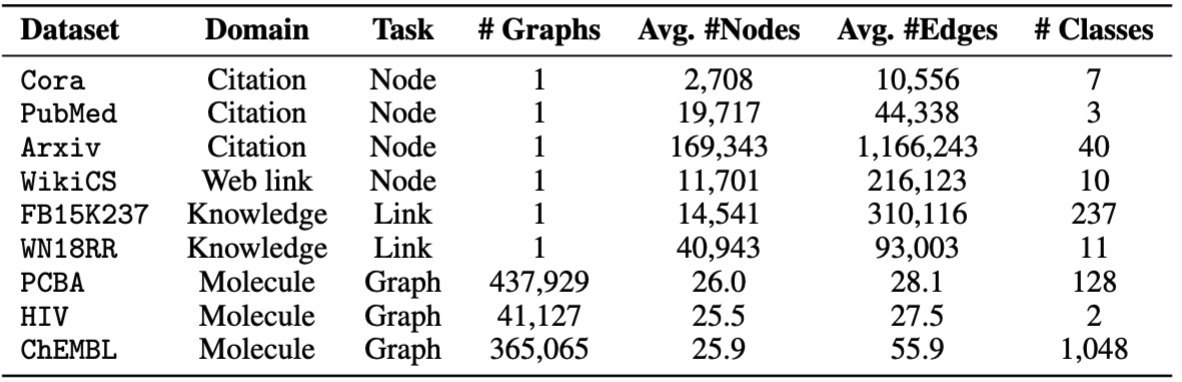
Wir verwenden Datensätze von OFA. Sie /data den pretrain.py ausführen. Die Pipeline wird die Datensätze automatisch vorbereiten, indem Textualbeschreibungen in Texteinbettungen konvertiert werden.
Alternativ können Sie unsere vorverarbeiteten Datensätze herunterladen und auf dem Ordner /data entpacken.
Der GFT -Code ist in Ordner /GFT dargestellt. Die Struktur ist wie folgt.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
Sie können pretrain.py für eine Vielzahl von Diagrammen und finetune.py für die Anpassung an bestimmte nachgelagerte Aufgaben mit grundlegendem Flossen oder weniger Schuss-Lernen ausführen.
Um die Ergebnisse zu reproduzieren, bieten wir detaillierte Hyperparameter für Vorab- und Flossen, die in config/pretrain.yaml bzw. config/finetune.yaml aufrechterhalten werden. Um die Standard-Hyperparameter zu nutzen, geben wir einen Befehl --use_params für Pretrain und Finetune.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Für die Finetuning stellen wir acht Datensätze an, darunter cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv und chempcba .
Alternativ können Sie das Skript ausführen, um die Experimente zu reproduzieren.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
Hinweis: Das vorbereitete Modell wird standardmäßig in ckpts/pretrain_model/ standardmäßig gespeichert.
# The basic command for pretraining GFT
python GFT/pretrain.py
Wenn Sie pretrain.py ausführen, können Sie die Datensätze und Hyperparameter vorab anpassen.
Sie können --pretrain_dataset (OR --pt_data ) verwenden, um die verwendeten Vorbereitungsdatensätze und die entsprechenden Gewichte festzulegen. Die vordefinierte Datenkonfiguration befindet sich in config/pt_data.yaml mit den folgenden Strukturen.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
Im obigen Fall ist das all der Name der Einstellung, was bedeutet, dass alle Datensätze bei der Vorabbildung verwendet werden. Für jeden Datensatz gibt es ein Schlüsselwertpaar, bei dem der Schlüssel der Datensatzname ist und der Wert das Abtastgewicht ist. Zum Beispiel bedeutet cora: 5 , dass der cora -Datensatz 5 -mal in einer einzelnen Epoche abgetastet wird. Sie können Ihre eigene Datensatzkombination für die Vorab -GFT entwerfen.
Sie können die Vorbereitungsphase anpassen, indem Sie Hyperparameter von Encoder, Vektorquantisierung und Modelltraining verändern.
--pretrain_dataset : Geben Sie den Datensatz vorangeben. Das gleiche zum oben genannten.--use_params : Verwenden Sie die vordefinierten Hyperparameter.--seed : Der Samen, der für die Vorbereitung verwendet wird.--hidden_dim : Die Dimension in der verborgenen Schicht von GNNs.--num_layers : Die GNN-Schichten.--activation : Die Aktivierungsfunktion.--backbone : Das Backbone Gnn.--normalize : Die Normalisierungsschicht.--dropout : Der Ausfall der GNN-Schicht.--code_dim : Die Dimension jedes Codes im Wortschatz.--codebook_size : Die Anzahl der Codes im Wortschatz.--codebook_head : Die Anzahl der Codebuchköpfe. Wenn die Zahl größer als 1 ist, verwenden Sie gemeinsam mehrere Vokabeln.--codebook_decay : Die Zerfallsrate von Codes.--commit_weight : Das Gewicht des Verpflichtungsbegriffs.--pretrain_epochs : Die Anzahl der Epochen.--pretrain_lr : Die Lernrate.--pretrain_weight_decay : Das Gewicht des L2-Stammschusses.--pretrain_batch_size : Die Stapelgröße.--feat_p : Die Korruptionsrate der Funktion.--edge_p : Die Korruptionsrate der Kante/Struktur.--topo_recon_ratio : Das Verhältnis der Kanten sollte rekonstruiert werden.--feat_lambda : Das Gewicht des Feature-Verlustes.--topo_lambda : Das Gewicht des Topologieverlusts.--topo_sem_lambda : Das Gewicht des Topologieverlusts bei Rekonstruktionskantenmerkmalen.--sem_lambda : Das Gewicht des semantischen Verlustes.--sem_encoder_decay : Die Impuls-Update-Rate für den semantischen Encoder. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
Sie können --dataset , um den nachgeschalteten Datensatz anzugeben, und --use_params um die vordefinierten Hyperparameter für jeden Datensatz zu verwenden. Andere Hyperparameter, die Sie angeben können, werden wie folgt dargestellt.
Für Diagramme mit 1 vordefinierter Aufteilung können Sie einstellen --repeat wiederholen Sie mehrere Experimente.
--hidden_dim : Die Dimension in der verborgenen Schicht von GNNs.--num_layers : Die GNN-Schichten.--activation : Die Aktivierungsfunktion.--backbone : Das Backbone Gnn.--normalize : Die Normalisierungsschicht.--dropout : Der Ausfall der GNN-Schicht.--code_dim : Die Dimension jedes Codes im Wortschatz.--codebook_size : Die Anzahl der Codes im Wortschatz.--codebook_head : Die Anzahl der Codebuchköpfe. Wenn die Zahl größer als 1 ist, verwenden Sie gemeinsam mehrere Vokabeln.--codebook_decay : Die Zerfallsrate von Codes.--commit_weight : Das Gewicht des Verpflichtungsbegriffs.--finetune_epochs : Die Anzahl der Epochen.--finetune_lr : Die Lernrate.--early_stop : Die maximale Epoche der frühen Stop.--batch_size : Wenn Sie auf 0 gesetzt sind, führen Sie das vollständige Diagrammtraining durch. --lambda_proto : Das Gewicht des Prototyp-Klassifizierers bei der Finetuning.
--lambda_act : Das Gewicht des linearen Klassifikators bei der Finetuning.
--trade_off : Der Kompromiss zwischen der Verwendung von Prototypen-Klasser oder der Verwendung eines linearen Klassifizierers in Inferenz.
Sie können addieren --no_lin_clf oder --no_proto_clf , um die Verwendung von linearem Klassifizierer bzw. Prototyp -Klassifikator zu vermeiden. Beachten Sie, dass diese beiden Begriffe Konflikte sind, da Sie mindestens einen Klassifikator verwenden müssen.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
Sie können --dataset , um den nachgeschalteten Datensatz anzugeben, und --use_params um die vordefinierten Hyperparameter für jeden Datensatz zu verwenden. Andere Hyperparameter, die Sie angeben können, werden wie folgt dargestellt.
Die Hyper-Parameters, die für wenige Schüsse gewidmet sind, sind
--n_train : Die Anzahl der Trainingsinstanzen pro Klasse für die Fülle des Modells. Beachten Sie, dass kleiner n_train die wünschenswerte Leistung erzielt --n_task : Die Anzahl der abgetasteten Aufgaben.--n_way : Die Anzahl der Wege.--n_query : Die Größe des Abfragestells pro Weg.--n_shot : Die Größe des Unterstützungssatzes pro Weg.--hidden_dim : Die Dimension in der verborgenen Schicht von GNNs.--num_layers : Die GNN-Schichten.--activation : Die Aktivierungsfunktion.--backbone : Das Backbone Gnn.--normalize : Die Normalisierungsschicht.--dropout : Der Ausfall der GNN-Schicht.--code_dim : Die Dimension jedes Codes im Wortschatz.--codebook_size : Die Anzahl der Codes im Wortschatz.--codebook_head : Die Anzahl der Codebuchköpfe. Wenn die Zahl größer als 1 ist, verwenden Sie gemeinsam mehrere Vokabeln.--codebook_decay : Die Zerfallsrate von Codes.--commit_weight : Das Gewicht des Verpflichtungsbegriffs.--finetune_epochs : Die Anzahl der Epochen.--finetune_lr : Die Lernrate.--early_stop : Die maximale Epoche der frühen Stop.--batch_size : Wenn Sie auf 0 gesetzt sind, führen Sie das vollständige Diagrammtraining durch. --lambda_proto : Das Gewicht des Prototyp-Klassifizierers bei der Finetuning.
--lambda_act : Das Gewicht des linearen Klassifikators bei der Finetuning.
--trade_off : Der Kompromiss zwischen der Verwendung von Prototypen-Klasser oder der Verwendung eines linearen Klassifizierers in Inferenz.
Sie können addieren --no_lin_clf oder --no_proto_clf , um die Verwendung von linearem Klassifizierer bzw. Prototyp -Klassifikator zu vermeiden. Beachten Sie, dass diese beiden Begriffe Konflikte sind, da Sie mindestens einen Klassifikator verwenden müssen.
Die experimentellen Ergebnisse können aufgrund der randomisierten Initialisierung während der Vorbereitung variieren. Wir liefern die experimentellen Ergebnisse unter Verwendung verschiedener Zufallssamen (dh 1-5) in der Vorabbildung, um den potenziellen Einfluss der zufälligen Initialisierung zu zeigen.
| Cora | PubMed | Wiki-CS | Arxiv | WN18RR | FB15K237 | HIV | PCBA | Durchschnitt | |
|---|---|---|---|---|---|---|---|---|---|
| Samen = 1 | 78,58 ± 0,90 | 77,55 ± 1,54 | 79,38 ± 0,57 | 72,24 ± 0,16 | 91,56 ± 0,33 | 89,67 ± 0,35 | 72,69 ± 1,93 | 78,24 ± 0,23 | 79,99 |
| Samen = 2 | 78,27 ± 1,26 | 76,41 ± 1,36 | 79,36 ± 0,62 | 72,13 ± 0,24 | 91,72 ± 0,19 | 89,66 ± 0,31 | 71,62 ± 2,45 | 78,20 ± 0,33 | 79,67 |
| Samen = 3 | 78,16 ± 1,62 | 76,28 ± 1,37 | 79,32 ± 0,65 | 72,13 ± 0,30 | 91,57 ± 0,44 | 89,78 ± 0,23 | 71,58 ± 2,28 | 78,12 ± 0,37 | 79,62 |
| Samen = 4 | 78,42 ± 1,37 | 75,76 ± 1,58 | 79,44 ± 0,62 | 72,36 ± 0,34 | 91,70 ± 0,24 | 89,73 ± 0,21 | 72,57 ± 2,46 | 78,34 ± 0,27 | 79,79 |
| Samen = 5 | 78,56 ± 1,62 | 76,49 ± 2,00 | 79,27 ± 0,55 | 72,18 ± 0,26 | 91,47 ± 0,39 | 89,80 ± 0,19 | 72,27 ± 0,93 | 78,31 ± 0,34 | 79,79 |
| Gemeldet | 78,62 ± 1,21 | 77,19 ± 1,99 | 79,39 ± 0,42 | 71,93 ± 0,12 | 91,91 ± 0,34 | 89,72 ± 0,20 | 72,67 ± 1,38 | 77,90 ± 0,64 | 79,92 |
Um die Reproduzierbarkeit besser sicherzustellen, stellen wir die Kontrollpunkte von Saatgut = 1 in diesem Link bereit. Wir wählen dies aufgrund seiner besten durchschnittlichen Leistung aus. Sie können die heruntergeladene Datei in den Pfad ckpts/pretrain_model/ entpucken und die --pt_seed 1 festlegen, wenn Sie finetune.py verwenden, um unsere bereitgestellten Kontrollpunkte zart zu nutzen.
Bitte wenden Sie sich an [email protected] oder eröffnen Sie ein Problem, wenn Sie Fragen haben.
Wenn Sie feststellen, dass das Repo für Ihre Recherche nützlich ist, zitieren Sie bitte das Originalpapier richtig.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}Dieses Repository basiert auf der Codebasis von OFA, PYG, OGB und VQ. Danke für ihr Teilen!


