vision_transformer
1.0.0
In diesem Repository veröffentlichen wir Modelle aus den Papieren
Die Modelle wurden auf den Datensätzen imageNet- und imageNET-21K vorgebracht. Wir bieten den Code zur Feinabstimmung der freigegebenen Modelle in Jax/Flachs.
Die Modelle dieser Codebasis wurden ursprünglich in https://github.com/google-research/big_vision/ trainiert, wo Sie fortgeschrittenere Code (z. B. Multi-Host-Training) sowie einige der ursprünglichen Trainingsskripte (z. B. Konfigurationen) finden können /vit_i21k.py für die Vorausbildung eines VIT oder configs/Transfer.py zur Übertragung eines Modells).
Inhaltsverzeichnis:
Unterhalb von Colabs laufen sowohl mit GPUs als auch mit TPUs (8 Kerne, Datenparallelität).
Der erste Colab demonstriert den JAX -Code für Vision -Transformatoren und MLP -Mixer. Mit diesem Colab können Sie die Dateien aus dem Repository direkt in der Colab -Benutzeroberfläche bearbeiten, und verfügt über kommentierte Colab -Zellen, die Sie Schritt für Schritt durch den Code führen und mit den Daten interagieren können.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
Mit dem zweiten Colab können Sie den> 50 -km -Vision -Transformator und die Hybrid -Kontrollpunkte untersuchen, mit denen die Daten des dritten Papiers "So trainieren Sie Ihren Vit? ...". Der Colab enthält Code zum Erkunden und Auswählen von Checkpoints sowie zur Inferenz, die sowohl den JAX -Code aus diesem Repo als auch die beliebte timm Pytorch -Bibliothek verwenden, mit der diese Kontrollpunkte direkt geladen werden können. Beachten Sie, dass eine Handvoll Modelle auch direkt von TF-Hub erhältlich sind: Sayakpaul/Sammlungen/Vision_Transformer (externer Beitrag von Sayak Paul).
Mit dem zweiten Colab können Sie auch die Checkpoints in jedem TFDS-Datensatz und in Ihrem eigenen Datensatz mit Beispielen in einzelnen JPEG-Dateien (optional direkt von Google Drive) abstellen.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
HINWEIS : Wie derzeit (20.06.21) unterstützt Google Colab nur eine einzige GPU (Nvidia Tesla T4), und TPU Schlechte Trainingsgeschwindigkeit. Normalerweise möchten Sie eine dedizierte Maschine einrichten, wenn Sie eine nicht triviale Datenmenge zur Feinabstimmung haben. Weitere Informationen finden Sie im Abschnitt Cloud.
Stellen Sie sicher, dass Sie Python>=3.10 auf Ihrem Computer installiert haben.
Installieren Sie die Abhängigkeiten von Jax und Python, indem Sie ausführen:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
Befolgen Sie für neuere Versionen von JAX den Anweisungen im entsprechenden hier verknüpften Repository. Beachten Sie, dass die Installationsanweisungen für CPU, GPU und TPU geringfügig unterscheiden.
Installieren Sie Flaxformer und befolgen Sie die Anweisungen im entsprechenden hier verknüpften Repository.
Weitere Informationen finden Sie im Abschnitt, der auf der folgenden Cloud ausgeführt wird.
Sie können das heruntergeladene Modell auf Ihrem interessierenden Datensatz ausführen. Alle Modelle teilen die gleiche Befehlszeilenschnittstelle.
Zum Beispiel zur Feinabstimmung eines Vit-B/16 (vorab auf ImageNet21K) auf CIFAR10 (Beachten Sie, wie wir b16,cifar10 als Argumente an die Konfiguration angeben und wie wir den Code anweisen, direkt von einem GCS-Bucket aus auf die Modelle zuzugreifen Anstatt sie zuerst in das lokale Verzeichnis herunterzuladen):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'Um einen Mixer-B/16 (vorgebildet auf ImageNet21k) auf CIFAR10 zu optimieren:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' Das "Wie trainiere du deinen Vit? ...". Papier addiert> 50k Checkpoints, die Sie mit der configs/augreg.py -Konfiguration fein stimmen können. Wenn Sie nur den Modellnamen angeben (den config.name von configs/model.py ), dann wird der beste I21K -Kontrollpunkt für die nach vorgelagerte Validierungsgenauigkeit ("Empfohlener" Checkpoint, siehe Abschnitt 4.5 des Papiers) ausgewählt. Um sich zu entscheiden, welches Modell Sie verwenden möchten, schauen Sie sich Abbildung 3 im Papier an. Es ist auch möglich, einen anderen Checkpoint auszuwählen (siehe Colab vit_jax_augreg.ipynb ) und dann den Wert aus der Spalte filename oder adapt_filename angeben, die den Dateinamen ohne .npz aus dem Verzeichnis gs://vit_models/augreg entsprechen.
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 Derzeit lädt der Code automatisch CIFAR-10- und CIFAR-100-Datensätze herunter. Andere öffentliche oder benutzerdefinierte Datensätze können mithilfe der TensorFlow -Datasets -Bibliothek einfach integriert werden. Beachten Sie, dass Sie auch vit_jax/input_pipeline.py aktualisieren müssen, um einige Parameter zu jedem hinzugefügten Datensatz anzugeben.
Beachten Sie, dass unser Code alle verfügbaren GPUs/TPUs zur Feinabstimmung verwendet.
Um eine detaillierte Liste aller verfügbaren Flags anzuzeigen, führen Sie python3 -m vit_jax.train --help aus.
Anmerkungen zum Speicher:
--config.accum_steps=8 erhöhen-Alternativ können Sie auch die --config.batch=512 verringern (und verringern --config.base_lr entsprechend).--config.shuffle_buffer=50000 . Von Alexey Dosovitskiy*†, Lucas Beyer*, Alexander Kolesnikov*, Dirk Weissenborn*, Xiaohua Zhai*, Thomas Enttiner, Mostafa Dehghani, Matthias Mindlerer, Georgold, Sylvain Gelly, Jakob Uszkore und NEEL HOULSBY*†.
(*) Gleicher technischer Beitrag, (†) gleichberechtigte Beratung.
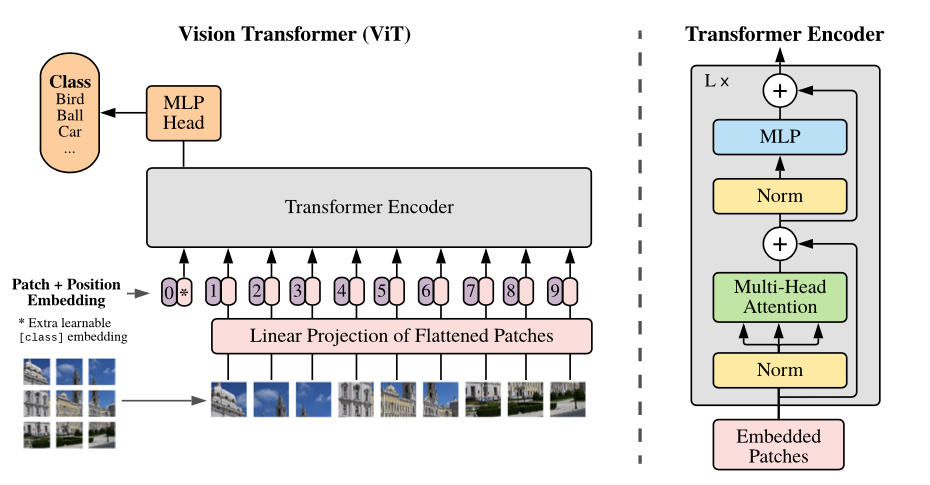
Übersicht über das Modell: Wir haben ein Bild in Fixierflecken aufgeteilt, jeweils linear einbetten, Positionsbettendings hinzufügen und die resultierende Sequenz von Vektoren zu einem Standardtransformator-Encoder füttern. Um die Klassifizierung durchzuführen, verwenden wir den Standardansatz, der Sequenz ein extra gelerntes "Klassifizierungs -Token" hinzuzufügen.
Wir bieten eine Vielzahl von VIT -Modellen in verschiedenen GCS -Eimer. Die Modelle können mit EG heruntergeladen werden:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
Die Modelldilenamen (ohne die .npz -Erweiterung) entsprechen der config.model_name in vit_jax/configs/models.py
gs://vit_models/imagenet21k -Modelle, die auf ImageNet-21k vorgebracht sind.gs://vit_models/imagenet21k+imagenet2012 -Modelle, die auf ImageNet-21k vorgebracht und auf ImageNet abgestimmt sind.gs://vit_models/augreg -Modelle, die auf ImageNet-21k vorgebracht sind und unterschiedliche Mengen von Augreg anwenden. Verbesserte Leistung.gs://vit_models/sam - Modelle, die auf ImageNet mit sam ausgebildet sind.gs://vit_models/gsam - Modelle, die auf ImageNet mit GSAM ausgebildet sind.Wir empfehlen, die folgenden Kontrollpunkte mit Augreg zu verwenden, die die besten Metriken vor dem Training haben:
| Modell | Vorausgebildeter Kontrollpunkt | Größe | Feinabstimmung | Auflösung | IMG/Sek | Bildnahrung |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85,59% |
| B/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85,49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83,73% |
| R50+l/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85,99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83,85% |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78,22% |
| B/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83,59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79,58% |
| R+ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 MIB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75,40% |
Die Ergebnisse des ursprünglichen VIT -Papiers (https://arxiv.org/abs/2010.11929) wurden unter Verwendung der Modelle von gs://vit_models/imagenet21k repliziert:
| Modell | Datensatz | Tropfen = 0,0 | Tropfen = 0,1 |
|---|---|---|---|
| R50+Vit-B_16 | CIFAR10 | 98,72%, 3,9h (A100), TB.Dev | 98,94%, 10,1H (V100), TB.Dev |
| R50+Vit-B_16 | CIFAR100 | 90,88%, 4,1H (A100), TB.Dev | 92,30%, 10,1H (V100), TB.Dev |
| R50+Vit-B_16 | ImageNet2012 | 83,72%, 9,9H (A100), TB.Dev | 85,08%, 24,2H (V100), TB.Dev |
| Vit-B_16 | CIFAR10 | 99,02%, 2,2H (A100), TB.Dev | 98,76%, 7,8H (V100), TB.Dev |
| Vit-B_16 | CIFAR100 | 92,06%, 2,2H (A100), TB.Dev | 91,92%, 7,8H (V100), TB.Dev |
| Vit-B_16 | ImageNet2012 | 84,53%, 6,5H (A100), TB.Dev | 84,12%, 19,3H (V100), TB.Dev |
| Vit-B_32 | CIFAR10 | 98,88%, 0,8H (A100), TB.Dev | 98,75%, 1,8H (V100), TB.Dev |
| Vit-B_32 | CIFAR100 | 92,31%, 0,8H (A100), TB.Dev | 92,05%, 1,8H (V100), TB.Dev |
| Vit-B_32 | ImageNet2012 | 81,66%, 3,3H (A100), TB.Dev | 81,31%, 4,9h (V100), TB.Dev |
| Vit-L_16 | CIFAR10 | 99,13%, 6,9H (A100), TB.Dev | 99,14%, 24,7H (V100), TB.Dev |
| Vit-L_16 | CIFAR100 | 92,91%, 7,1H (A100), TB.Dev | 93,22%, 24,4H (V100), TB.Dev |
| Vit-L_16 | ImageNet2012 | 84,47%, 16,8H (A100), TB.Dev | 85,05%, 59,7H (V100), TB.Dev |
| Vit-L_32 | CIFAR10 | 99,06%, 1,9H (A100), TB.Dev | 99,09%, 6,1H (V100), TB.Dev |
| Vit-L_32 | CIFAR100 | 93,29%, 1,9H (A100), TB.Dev | 93,34%, 6,2H (V100), TB.Dev |
| Vit-L_32 | ImageNet2012 | 81,89%, 7,5H (A100), TB.Dev | 81,13%, 15,0H (V100), TB.dev |
Wir möchten auch betonen, dass qualitativ hochwertige Ergebnisse mit kürzeren Schulungsplänen erzielt werden können, und die Benutzer unseres Codes ermutigen, mit Hyper-Parametern zur Kompromissgenauigkeit und dem Rechenbudget zu spielen. Einige Beispiele für CIFAR-10/100-Datensätze sind in der folgenden Tabelle angezeigt.
| stromaufwärts | Modell | Datensatz | Total_Steps / Warmup_Steps | Genauigkeit | Wandverkaufszeit | Link |
|---|---|---|---|---|---|---|
| ImageNet21k | Vit-B_16 | CIFAR10 | 500 /50 | 98,59% | 17m | Tensorboard.dev |
| ImageNet21k | Vit-B_16 | CIFAR10 | 1000 /100 | 98,86% | 39m | Tensorboard.dev |
| ImageNet21k | Vit-B_16 | CIFAR100 | 500 /50 | 89,17% | 17m | Tensorboard.dev |
| ImageNet21k | Vit-B_16 | CIFAR100 | 1000 /100 | 91,15% | 39m | Tensorboard.dev |
Von Ilya Tolstikhin*, Neil Houlsby*, Alexander Kolesnikov*, Lucas Beyer*, Xiaohua Zhai, Thomas Untertiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy.
(*) Gleicher Beitrag.
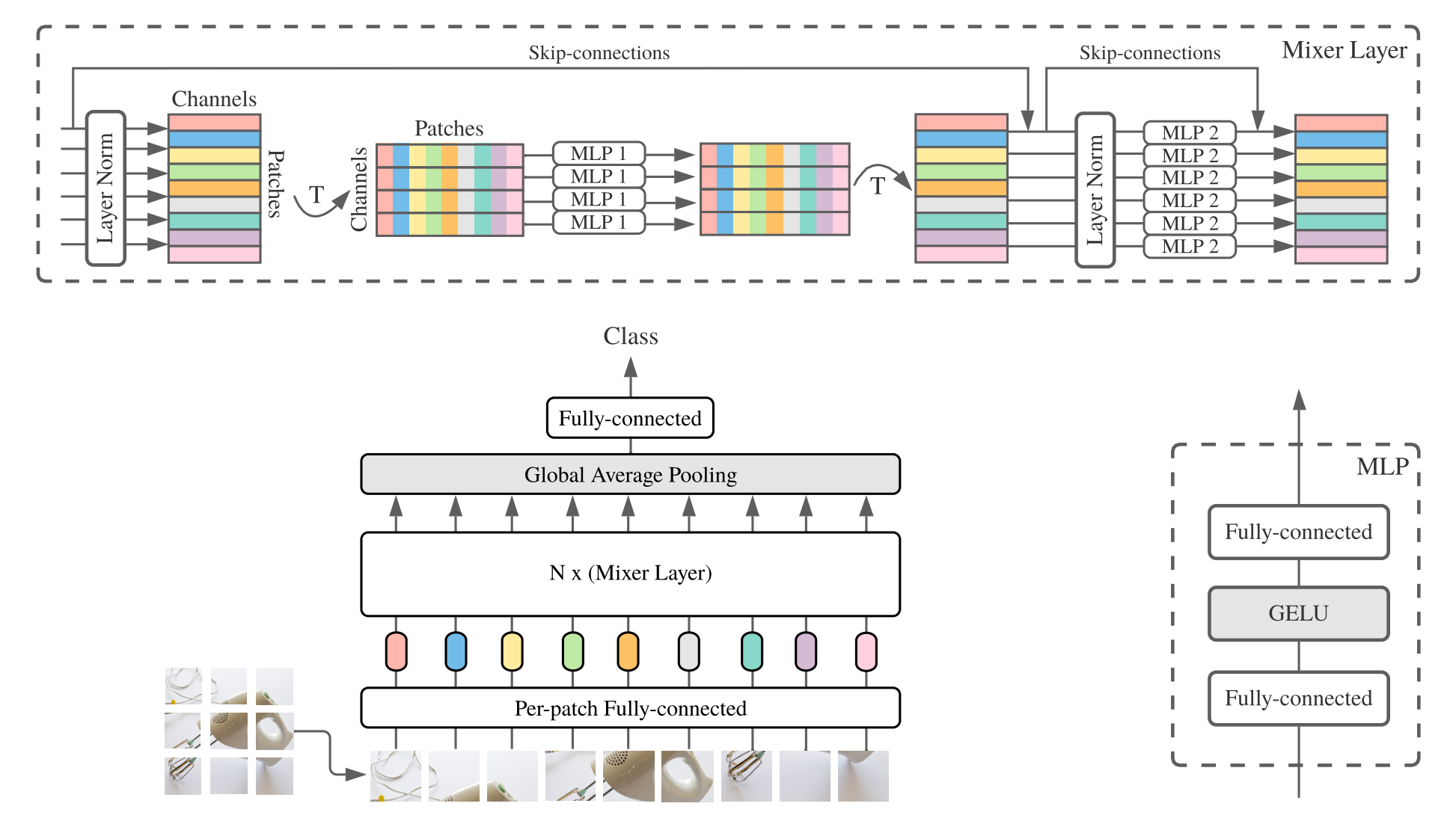
MLP-Mixer (kurzmischer Mixer ) besteht aus linearen Einbettungen pro Patch, Mixerschichten und einem Klassifikatorkopf. Mixerschichten enthalten einen Token-Mixing-MLP und einen Kanalmischmisch-MLP, der jeweils aus zwei vollständig vernetzten Schichten und einer Gelu-Nichtlinearität besteht. Weitere Komponenten umfassen: Überspringen von Verbindungen, Dropout und linearer Klassifikatorkopf.
Für die Installation folgen Sie den gleichen Schritten wie oben.
Wir bieten die Modelle für Mixer-B/16 und Mixer-L/16, die auf den Datensätzen imageNet- und imagNet-21k vorgebracht sind. Details finden Sie in Tabelle 3 des Mixerpapiers. Alle Modelle finden Sie unter:
https://console.cloud.google.com/storage/mixer_models/
Beachten Sie, dass diese Modelle auch direkt bei TF-Hub erhältlich sind: Sayakpaul/Sammlungen/MLP-Mixer (externer Beitrag von Sayak Paul).
Wir haben den Feinabstimmungscode auf dem Google Cloud-Computer mit vier V100-GPUs mit den Standardanpassungsparametern dieses Repositorys ausgeführt. Hier sind die Ergebnisse:
| stromaufwärts | Modell | Datensatz | Genauigkeit | WALL_CLOCK_TIME | Link |
|---|---|---|---|---|---|
| Bildnische | Mixer-B/16 | CIFAR10 | 96,72% | 3.0h | Tensorboard.dev |
| Bildnische | Mixer-L/16 | CIFAR10 | 96,59% | 3.0h | Tensorboard.dev |
| ImageNet-21k | Mixer-B/16 | CIFAR10 | 96,82% | 9.6H | Tensorboard.dev |
| ImageNet-21k | Mixer-L/16 | CIFAR10 | 98,34% | 10.0h | Tensorboard.dev |
Weitere Informationen finden Sie im Google AI-Blog-Beitrag Lit: Hinzufügen von Sprachverständnis zu Bildmodellen oder lesen Sie das CVPR-Papier "Lit: Zero-Shot-Übertragung mit gesperrten Textabstimmung" (https://arxiv.org/abs/2111.07991 ).
Wir haben ein Transformator B/16-Base-Modell mit einer ImageNet-Zeroshot-Genauigkeit von 72,1%und einem L/16-Large-Modell mit einer Genauigkeit von 75,7%von 72,1%veröffentlicht. Weitere Informationen zu diesen Modellen finden Sie in der LIT -Modellkarte.
Wir bieten eine In-Browser-Demo mit kleinen Textcodierern für den interaktiven Gebrauch (die kleinsten Modelle sollten sogar auf einem modernen Handy ausgeführt werden):
https://google-research.github.io/vision_transformer/lit/
Und schließlich ein Colab, um die JAX -Modelle mit Bild- und Textcodierern zu verwenden:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
Beachten Sie, dass noch keiner der oben genannten Modelle mehrsprachige Eingaben unterstützen, aber wir arbeiten an der Veröffentlichung solcher Modelle und aktualisieren dieses Repository, sobald sie verfügbar sind.
Dieses Repository enthält nur Bewertungscode für LIT -Modelle. Sie finden den Trainingscode im big_vision -Repository:
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
Erwartete Zeroshot -Ergebnisse von model_cards/lit.md (Beachten Sie, dass sich die Zeroshot -Bewertung geringfügig von der vereinfachten Bewertung im Colab unterscheidet):
| Modell | B16B_2 | L16L |
|---|---|---|
| ImagNet Zero-Shot | 73,9% | 75,7% |
| ImageNet V2 Zero-Shot | 65,1% | 66,6% |
| CIFAR100 Null-Shot | 79,0% | 80,5% |
| PETS37 Zero-Shot | 83,3% | 83,3% |
| Resisc45 Zero-Shot | 25,3% | 25,6% |
| MS-Coco-Bildunterschriften Bild-zu-Text-Abruf | 51,6% | 48,5% |
| MS-Coco-Bildunterschriften Text-zu-Image-Abruf | 31,8% | 31,1% |
Während über Colabs ziemlich nützlich sind, um loszulegen, möchten Sie normalerweise auf einer größeren Maschine mit leistungsstärkeren Beschleunigern trainieren.
Sie können die folgenden Befehle verwenden, um eine VM mit GPUs auf Google Cloud einzurichten:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEAlternativ können Sie die folgenden ähnlichen Befehle verwenden, um eine Cloud -VM mit angeschlossenen TPUs einzurichten (folgende Befehle, die aus dem TPU -Tutorial kopiert wurden):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME Und dann das Repository und die Installationsabhängigkeiten (einschließlich jaxlib mit TPU -Unterstützung) wie gewohnt ab:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateWenn Sie mit einem VM mit angeschlossenem GPUs verbunden sind, installieren Sie JAX und andere Abhängigkeiten mit dem folgenden Befehl:
pip install -r vit_jax/requirements.txtWenn Sie mit einem VM mit angeschlossenem TPUs verbunden sind, installieren Sie JAX und andere Abhängigkeiten mit dem folgenden Befehl:
pip install -r vit_jax/requirements-tpu.txtInstallieren Sie Flaxformer und befolgen Sie die Anweisungen im entsprechenden hier verknüpften Repository.
Überprüfen Sie sowohl für GPUs als auch für TPUs, dass JAX mit dem Befehl eine Verbindung zu beigefügten Beschleunigern herstellen kann:
python -c ' import jax; print(jax.devices()) 'Und schließlich einen der im Abschnitt genannten Befehle ausführen, die ein Modell fein abtun.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
In umgekehrter chronologischer Reihenfolge:
2022-08-18: Das Modell von LIT-B16B_2 wurde für 60K-Schritte (LIT_B16B: 30K) ohne linearen Kopf auf der Bildseite (Lit_B16b: 768) hinzugefügt und hat eine bessere Leistung.
2022-06-09: Die VIT-und-Mixer-Modelle wurden mit GSAM auf ImageNet ohne starke Datenvergrößerungen hinzugefügt. Die resultierenden Vits übertreffen diejenigen ähnlichen Größen, die mit Adamw Optimizer oder dem ursprünglichen SAM -Algorithmus oder mit starken Datenvergrößerungen trainiert wurden.
2022-04-14: Modelle und Colab für LIT-Modelle hinzugefügt.
2021-07-29: Zusätzliche Vit-B/8-Augreg-Modelle (3 Upstream-Checkpoints und Anpassungen mit Auflösung = 224).
2021-07-02: Das Papier "Wenn Vision-Transformatoren übertrieben ..." hinzugefügt wird
2021-07-02: SAM (SHARPNESS-ANMILE-MINIMIERUNG) optimierte VIT- und MLP-Mixer-Checkpoints.
2021-06-20: Fügte das Papier "Wie man Ihren Vit? ..." und ein neues Colab hinzugefügt, um die in der Zeitung erwähnten> 50K vorgeborenen und fein abgestimmten Kontrollpunkte zu erkunden.
2021-06-18: Dieses Repository wurde neu geschrieben, um Flax-Leinen-API und ml_collections.ConfigDict für die Konfiguration zu verwenden.
2021-05-19: Mit der Veröffentlichung des Papiers "Wie man Ihr Vit? ..." veröffentlicht hat, haben wir mehr als 50.000 VIT- und Hybridmodelle hinzugefügt, die auf ImageNet und ImageNet-21K mit verschiedenen Datenvergrößerungen und Model-Regularisierung vorhanden sind und fein abgestimmt auf ImageNet, PETS37, Kitti-Distanz, Cifar-100 und Resisc45. Schauen Sie sich vit_jax_augreg.ipynb an, um diese Schatztrove von Models zu navigieren! Sie können beispielsweise diesen Colab verwenden, um die Dateinamen der empfohlenen vorgeborenen und fein abgestimmten Kontrollpunkte aus der Spalte i21k_300 in Tabelle 3 im Papier abzurufen.
2020-12-01: Das R50+Vit-B/16-Hybridmodell (Vit-B/16 über einem Resnet-50-Rückgrat) hinzugefügt. Bei der Vorbereitung auf ImageNet21K erreicht dieses Modell fast die Leistung des L/16 -Modells mit weniger als der Hälfte der Rechenfonetuning -Kosten. Beachten Sie, dass "R50" für die B/16-Variante etwas modifiziert ist: Der ursprüngliche ResNET-50 hat [3,4,6,3] Blöcke, wodurch jeweils die Auflösung des Bildes um einen Faktor zwei verringert wird. In Kombination mit dem RESNET-Stamm würde dies zu einer Reduzierung von 32x führen, so dass die Vit-B/16-Variante auch bei einer Patchgröße von (1,1) nicht mehr realisiert werden kann. Aus diesem Grund verwenden wir stattdessen [3,4,9] Blöcke für die R50+B/16 -Variante.
2020-11-09: Das Vit-L/16-Modell hinzugefügt.
2020-10-29: Zusätzte Modelle Vit-B/16 und Vit-L/16, die auf ImageNet-21k vorgebracht und dann bei der Auflösung von 224x224 auf dem Bild von 284 x 384 auf der 224x224-Auflösung abgestimmt sind. Diese Modelle haben das Suffix "-224" in ihrem Namen. Es wird erwartet, dass sie 81,2% bzw. 82,7% der Top-1-Genauigkeiten erreichen.
Open Source -Release von Andreas Steiner.
Hinweis: Dieses Repository wurde von Google-Research/Big_Transfer geändert und geändert.
Dies ist kein offizielles Google -Produkt.


