Awesome LLM 3D
1.0.0
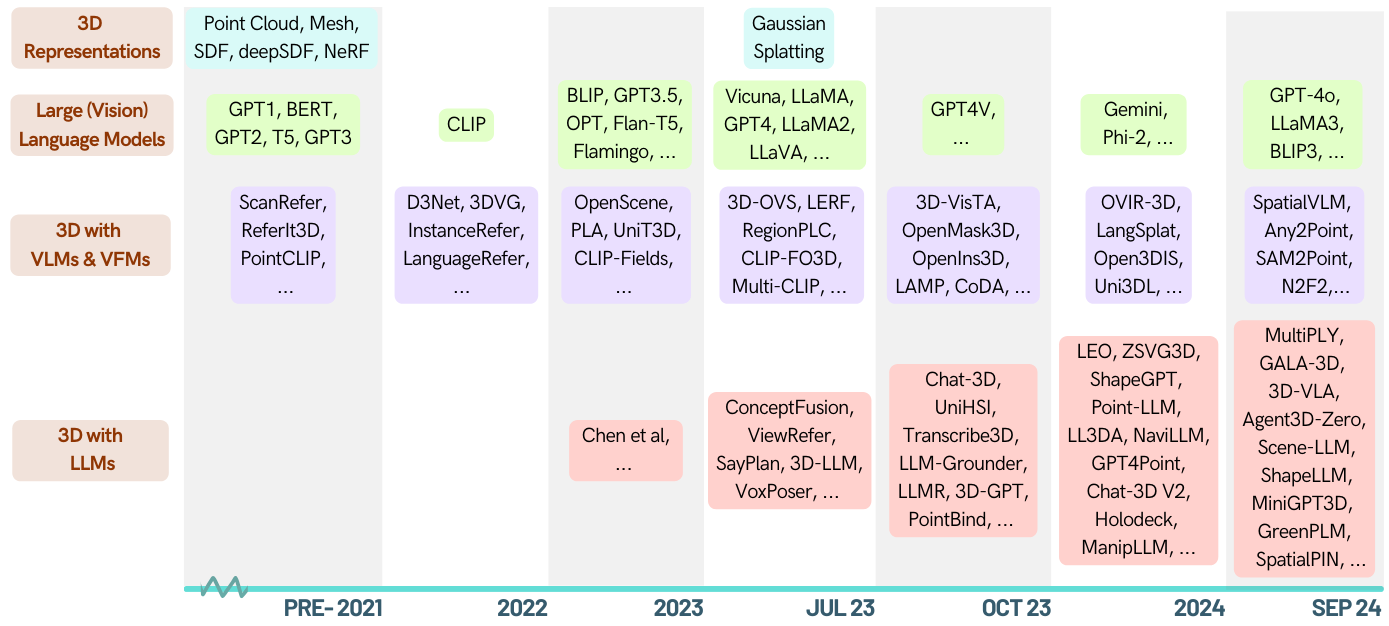
Hier finden Sie eine kuratierte Liste von Arbeiten über 3D-bezogene Aufgaben, die durch Großsprachenmodelle (LLMs) gestärkt werden. Es enthält verschiedene Aufgaben, darunter 3D -Verständnis, Argumentation, Generation und verkörperte Wirkstoffe. Außerdem enthalten wir andere Grundlagenmodelle (Clip, SAM) für das gesamte Bild dieses Gebiets.
Dies ist ein aktives Repository. Sie können sich nach den neuesten Fortschritten befolgen. Wenn Sie es nützlich finden, speichern Sie bitte dieses Repo und zitieren Sie das Papier.
[2024-05-16]? Schauen Sie sich das erste Umfragepapier in der 3D-LLM-Domäne an: Wenn LLMs in die 3D-Welt eintreten: eine Umfrage und Meta-Analyse von 3D-Aufgaben über multi-modale Großsprachenmodelle
[2024-01-06] Runsen Xu fügte chronologische Informationen hinzu, und Xianzheng Ma hat sie in ZA-Reihenfolge neu organisiert, um nach den neuesten Fortschritten besser zu werden.
[2023-12-16] Xianzheng Ma und Yash Balgat kuratierten diese Liste und veröffentlichten die erste Version;
Awesome-Llm-3D
3D -Verständnis (LLM)
3D -Verständnis (andere Fundamentmodelle)
3D -Argumentation
3D -Generation
3D -verkörperter Wirkstoff
3D -Benchmarks
Beitragen
| Datum | Schlüsselwörter | Institut (zuerst) | Papier | Veröffentlichung | Andere |
|---|---|---|---|---|---|
| 2024-10-12 | Situation3d | UIUC | Situationsbewusstsein ist im 3D -Vision -Sprachgelände wichtig | CVPR '24 | Projekt |
| 2024-09-28 | Llava-3d | HKU | LLAVA-3D: Ein einfacher, aber effektiver Weg zur Stärkung von LMMs mit 3D-Wahrnehmung | Arxiv | Projekt |
| 2024-09-08 | Msr3d | Bigai | Multi-Modal-Argumentation in 3D-Szenen | Neurips '24 | Projekt |
| 2024-08-28 | GreenPlm | Hust | Mehr Text, Weniger Punkt: Auf dem Weg zum dateneffizienten 3D-Point-Sprachverständnis | Arxiv | Github |
| 2024-06-17 | Llana | Unibo | Llana: Große Sprache und Nerf Assistent | Neurips '24 | Projekt |
| 2024-06-07 | Spatialpin | Oxford | Spatialpin: Verbesserung der räumlichen Argumentationsfunktionen von Visionsprachmodellen durch Aufforderung und Interaktion von 3D-Priors | Neurips '24 | Projekt |
| 2024-06-03 | Spatialrgpt | UCSD | SpatialRGPT: geerdetes räumliches Denken in Sehsprachmodellen | Neurips '24 | Github |
| 2024-05-02 | Minigpt-3d | Hust | MiniGPT-3D: Effizientes Ausrichten von 3D-Punktwolken mit großen Sprachmodellen mit 2D-Priors | ACM MM '24 | Projekt |
| 2024-02-27 | Shapellm | Xjtu | Shapellm: Universal 3D -Objektverständnis für eine verkörperte Interaktion | Arxiv | Projekt |
| 2024-01-22 | Räumlichvlm | Google DeepMind | Räumlichvlm: Sehvermögensmodelle mit räumlichen Argumentationsfunktionen ausgeben | CVPR '24 | Projekt |
| 2023-12-21 | Lidar-llm | PKU | Lidar-Llm: Erforschung des Potenzials großer Sprachmodelle für 3D-Lidar-Verständnis | Arxiv | Projekt |
| 2023-12-15 | 3DAP | Shanghai AI Lab | 3Daxiesprompts: Entfesseln Sie die 3D-räumlichen Aufgabenfunktionen von GPT-4V | Arxiv | Projekt |
| 2023-12-13 | Chat-Szene | Zju | CHAT-Szene: 3D-Szene und große Sprachmodelle mit Objektidentifikatoren überbrücken | Neurips '24 | Github |
| 2023-12-5 | Gpt4point | HKU | GPT4Point: Ein einheitlicher Rahmen für das Verständnis und die Erzeugung von Punkten Sprache und Generation | Arxiv | Github |
| 2023-11-30 | Ll3da | Fudan University | LL3DA: Visuelle interaktive Anweisungsabstimmung für OMNI-3D-Verständnis, Argumentation und Planung | Arxiv | Github |
| 2023-11-26 | ZSVG3D | CUHK (SZ) | Visuelle Programmierung für Null-Shot Open-Vocabulary 3D visuelle Erdung | Arxiv | Projekt |
| 2023-11-18 | LÖWE | Bigai | Ein verkörperter Generalist in der 3D -Welt | Arxiv | Github |
| 2023-10-14 | Jm3d-llm | Xiamen University | JM3D & JM3D-LlM: Erhöhen der 3D-Darstellung mit gemeinsamen multimodalen Hinweisen | ACM MM '23 | Github |
| 2023-10-10 | Uni3d | Baai | UNI3D: Erforschung einer einheitlichen 3D -Darstellung in Maßstab | ICLR '24 | Projekt |
| 2023-9-27 | - - | KAUST | Null-Shot-3D-Formkorrespondenz | Siggraph Asia '23 | - - |
| 2023-9-21 | LLM-Grounder | U-Mich | LLM-Grounder: Open-Vocabulary 3D Visuelle Erdung mit großer Sprachmodell als Agent | ICRA '24 | Github |
| 2023-9-1 | Point-Bind | CUHK | Point-Bind & Point-LlM: Ausrichtung der Punktwolke mit Multi-Modalität für 3D-Verständnis, Generation und Anweisungen folgen | Arxiv | Github |
| 2023-8-31 | Pointllm | CUHK | Pointllm: Ermächtigung großer Sprachmodelle, Punktwolken zu verstehen | ECCV '24 | Github |
| 2023-8-17 | CHAT-3D | Zju | CHAT-3D: dateneffizientes Tuning von Großsprachenmodell für den universellen Dialog von 3D-Szenen | Arxiv | Github |
| 2023-8-8 | 3D-Vista | Bigai | 3D-Vista: Vorausgebildeter Transformator für 3D-Seh- und Textausrichtung | ICCV '23 | Github |
| 2023-7-24 | 3D-Llm | UCLA | 3D-LlM: Injizieren der 3D-Welt in große Sprachmodelle | Neurips '23 | Github |
| 2023-3-29 | Viewrefer | CUHK | Viewrefer: Greifen Sie das Wissen über die Multi-View für 3D-visuelle Erdung aus | ICCV '23 | Github |
| 2022-9-12 | - - | MIT | Nutzung großer (visueller) Sprachmodelle für das Verständnis der Roboter -3D -Szene | Arxiv | Github |
| AUSWEIS | Schlüsselwörter | Institut (zuerst) | Papier | Veröffentlichung | Andere |
|---|---|---|---|---|---|
| 2024-10-12 | Lexikon3d | UIUC | Lexicon3d: Modelle der visuellen Grundlage für komplexes 3D -Szenenverständnis untersuchen | Neurips '24 | Projekt |
| 2024-10-07 | Diff2scene | CMU | Semantische Segmentierung von Open-Vokabeln mit Text-zu-Image-Diffusionsmodellen | ECCV 2024 | Projekt |
| 2024-04-07 | Any2Point | Shanghai AI Lab | Any2Point: Stärkung aller Modalität großer Modelle für ein effizientes 3D-Verständnis | ECCV 2024 | Github |
| 2024-03-16 | N2F2 | Oxford-Vgg | N2F2: Hierarchisches Szenenverständnis mit verschachtelten neuronalen Feldern | Arxiv | - - |
| 2023-12-17 | Sai3d | PKU | SAI3D: Segmentieren Sie jede Instanz in 3D -Szenen | Arxiv | Projekt |
| 2023-12-17 | Open3dis | Vinai | Open3DIS: Open-Vocabulary 3D-Instanzsegmentierung mit 2D-Maskenanleitung | Arxiv | Projekt |
| 2023-11-6 | Ovir-3d | Rutgers University | OVIR-3D: Open-Vocabulary 3D-Instanzabruf ohne Schulung auf 3D-Daten | Corl '23 | Github |
| 2023-10-29 | OpenMask3d | Eth | OpenMask3d: Open-Vocabulary 3D-Instanzsegmentierung | Neurips '23 | Projekt |
| 2023-10-5 | Offenfusion | - - | Open-Fusion: Echtzeit Open-Vocabulary 3D-Mapping und abfragbare Szenenrepräsentation | Arxiv | Github |
| 2023-9-22 | Ov-3ddet | Hkust | CODA: Kollaborative Roman-Box-Entdeckung und Kreuzmodalausrichtung zur Erkennung von 3D-Objekten offener Vokabeln | Neurips '23 | Github |
| 2023-9-19 | LAMPE | - - | Von der Sprache zu 3D -Welten: Anpassung des Sprachmodells für die Point Cloud -Wahrnehmung | OpenReview | - - |
| 2023-9-15 | Opennerf | - - | OpenSerf: Open-Set 3D-Segmentierung der Neuralen Szene mit pixel-weisen Merkmalen und gerenderten neuartigen Ansichten | OpenReview | Github |
| 2023-9-1 | Openins3d | Cambridge | OpenIns3d: Snap und suchen nach 3D Open-Vocabulary-Instanzsegmentierung | Arxiv | Projekt |
| 2023-6-7 | Kontrastierender Aufzug | Oxford-Vgg | Kontrastiven Auftrieb: Segmentierung der 3D-Objektinstanz durch langsame kontrastive Fusion | Neurips '23 | Github |
| 2023-6-4 | Multi-Clip | Eth | Multi-Clip: kontrastive Vision-Sprache vor dem Training für Fragen zur Beantwortung von Aufgaben in 3D-Szenen | Arxiv | - - |
| 2023-5-23 | 3D-OVS | NTU | Schwach beaufsichtigte 3D Open-Vocabulary-Segmentierung | Neurips '23 | Github |
| 2023-5-21 | VL-Felder | Universität von Edinburgh | VL-Feld | ICRA '23 | Projekt |
| 2023-5-8 | Clip-Fo3d | Tsinghua Universität | Clip-FO3D: Lernen Sie kostenlose 3D-Szene-Darstellungen der Open-World-Szene aus dem 2D-dichten Clip | ICCVW '23 | - - |
| 2023-4-12 | 3D-VQA | Eth | Clip-gesteuerte Visionsprachen vor dem Training für die Beantwortung von Fragen in 3D-Szenen | CVPRW '23 | Github |
| 2023-4-3 | RegionPlc | HKU | RegionPLC: Regionales punktsprachiges kontrastives Lernen für die 3D-Szenenverständnis der Open-World-Szene | Arxiv | Projekt |
| 2023-3-20 | CG3D | JHU | Clip Goes 3D: Nutzung eines sofortigen Einstellens für die Sprachgeerblichkeit 3D -Erkennung | Arxiv | Github |
| 2023-3-16 | Lerf | UC Berkeley | LERF: Sprache eingebettete Strahlungsfelder | ICCV '23 | Github |
| 2023-2-14 | Konzeptfusion | MIT | Konzeptfusion: Open-set multimodal 3D-Mapping | RSS '23 | Projekt |
| 2023-1-12 | Clip2scene | HKU | Clip2scene: Auf dem Weg zu labbeereffizienten 3D-Szenenverständnis durch Clip | CVPR '23 | Github |
| 2022-12-1 | Einheit3d | Tum | UNIT3D: Ein einheitlicher Transformator für 3D -dichte Bildunterschriften und visuelle Erdung | ICCV '23 | Github |
| 2022-11-29 | PLA | HKU | PLA: Sprachgetriebenes Open-Vocabular-3D-Szenenverständnis | CVPR '23 | Github |
| 2022-11-28 | OpenScene | Ethz | OpenScene: 3D -Szenenverständnis mit offenen Vokabeln | CVPR '23 | Github |
| 2022-10-11 | Clip-Felder | NYU | Clip-Felder: Schwach beaufsichtigte semantische Felder für Robotergedächtnis | Arxiv | Projekt |
| 2022-7-23 | Semantische Abstraktion | Columbia | Semantische Abstraktion: Open-World 3D-Szenenverständnis aus 2D-Visionsprachemodellen | Corl '22 | Projekt |
| 2022-4-26 | Scannet200 | Tum | Semantische Segmentierung der 3D-3D-Segmentierung in der Wildnis in freier Wildbahn in freier Wildbahn | ECCV '22 | Projekt |
| Datum | Schlüsselwörter | Institut (zuerst) | Papier | Veröffentlichung | Andere |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-CLR | UCLA | 3D-Konzept-Lernen und Argumentation aus Multi-View-Bildern | CVPR '23 | Github |
| - - | Transcribe3d | TTI, Chicago | Transcribe3D: Grounding LLMs unter Verwendung von transkribierten Informationen für 3D-Referenziell-Argumentation mit selbstkorrigiertem Finetuning | Corl '23 | Github |
| Datum | Schlüsselwörter | Institut | Papier | Veröffentlichung | Andere |
|---|---|---|---|---|---|
| 2023-11-29 | SHAPEGPT | Fudan University | ShapEGPT: 3D-Formerzeugung mit einem einheitlichen multimodalen Sprachmodell | Arxiv | Github |
| 2023-11-27 | Meshgpt | Tum | Meshgpt: Erzeugen von Dreiecksnetzen mit nur Decoder-Transformatoren | Arxiv | Projekt |
| 2023-10-19 | 3D-GPT | Anu | 3D-GPT: prozedurale 3D-Modellierung mit großen Sprachmodellen | Arxiv | Github |
| 2023-9-21 | Llmr | MIT | LLMR: Echtzeit-Aufforderung interaktiver Welten mit großer Sprachmodellen | Arxiv | - - |
| 2023-9-20 | Dreamllm | Megvii | Dreamllm: Synergistisches multimodales Verständnis und Schöpfung | Arxiv | Github |
| 2023-4-1 | Chatavatar | Technos technisch | Dreamface: Progressive Generation animatierbarer 3D -Gesichter unter Textanleitung | ACM Tog | Webseite |
| Datum | Schlüsselwörter | Institut | Papier | Veröffentlichung | Andere |
|---|---|---|---|---|---|
| 2024-01-22 | Räumlichvlm | Deepmind | Räumlichvlm: Sehvermögensmodelle mit räumlichen Argumentationsfunktionen ausgeben | CVPR '24 | Projekt |
| 2023-11-27 | Dobb-e | NYU | Roboter nach Hause bringen | Arxiv | Github |
| 2023-11-26 | Steve | Zju | Siehe und denken: verkörperte Agent in virtueller Umgebung | Arxiv | Github |
| 2023-11-18 | LÖWE | Bigai | Ein verkörperter Generalist in der 3D -Welt | Arxiv | Github |
| 2023-9-14 | Unihsi | Shanghai AI Lab | Einheitliche Wechselwirkung der Menschenszene über die kontaktierte Kontenkette | Arxiv | Github |
| 2023-7-28 | RT-2 | Google-Deepmind | RT-2: Vision-Sprach-Action-Modelle übertragen Webwissen auf Roboterkontrolle | Arxiv | Github |
| 2023-7-12 | SayPlan | QUT Center für Robotik | SayPlan: Erde große Sprachmodelle mithilfe von 3D -Szenengrafiken für skalierbare Roboter -Aufgabenplanung | Corl '23 | Github |
| 2023-7-12 | Voxposer | Stanford | Voxposer: komponierbare 3D -Wertkarten für Robotermanipulation mit Sprachmodellen | Arxiv | Github |
| 2022-12-13 | RT-1 | RT-1: Robotics-Transformator für die reale Steuerung im Maßstab | Arxiv | Github | |
| 2022-12-8 | LLM-Planner | Die Ohio State University | LLM-Planner: Wenige Schuss-geerdete Planung für verkörperte Wirkstoffe mit großen Sprachmodellen | ICCV '23 | Github |
| 2022-10-11 | Clip-Felder | NYU, Meta | Clip-Felder: Schwach beaufsichtigte semantische Felder für Robotergedächtnis | RSS '23 | Github |
| 2022-09-20 | NLMAP-SAYCAN | Repräsentationen für offene Vokabeln für die Planung der realen Welt | ICRA '23 | Github |
| Datum | Schlüsselwörter | Institut | Papier | Veröffentlichung | Andere |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | Bigai | Multi-Modal-Argumentation in 3D-Szenen | Neurips '24 | Projekt |
| 2024-06-10 | 3D-Engrand / 3D-Pope | Umich | 3D-Grand: Ein Million im Maßstab für 3D-LLLMs mit besserer Erdung und weniger Halluzination | Arxiv | Projekt |
| 2024-06-03 | Spatialrgpt-Bank | UCSD | SpatialRGPT: geerdetes räumliches Denken in Sehsprachmodellen | Neurips '24 | Github |
| 2024-1-18 | Szeneverse | Bigai | Szeneverse: Skalierung von 3D-Visionsprachlern für fundierte Szenenverständnis | Arxiv | Github |
| 2023-12-26 | Verkörpertes | Shanghai AI Lab | Verkörperter SCAN: Eine ganzheitliche multimodale 3D-Wahrnehmungssuite für verkörperte KI | Arxiv | Github |
| 2023-12-17 | M3dbench | Fudan University | M3dbench: Lasst uns große Modelle mit multimodalen 3D-Eingabeaufforderungen anweisen | Arxiv | Github |
| 2023-11-29 | - - | Deepmind | Bewertung von VLMs für Score-basierte, multi-probe-Annotation von 3D-Objekten | Arxiv | Github |
| 2023-09-14 | Crosskohärenz | Unibo | Sehen Sie sich Wörter und Punkte mit Aufmerksamkeit an: Ein Maßstab für Text-to-Form-Kohärenz | ICCV '23 | Github |
| 2022-10-14 | SQA3D | Bigai | SQA3D: In 3D -Szenen beantwortet die Frage | ICLR '23 | Github |
| 2021-12-20 | Scanqa | Riken Aip | Scanqa: 3D -Frage Beantwortung für das Verständnis der räumlichen Szene | CVPR '23 | Github |
| 2020-12-3 | Scan2Cap | Tum | Scan2Cap: Kontextbewusste dichte Bildunterschrift in RGB-D-Scans | CVPR '21 | Github |
| 2020-8-23 | Referit3d | Stanford | Referit3d: Neuronale Zuhörer für feinkörnige 3D-Objektidentifikation in realen Szenen | ECCV '20 | Github |
| 2019-12-18 | Scanrefer | Tum | Scanrefer: 3D-Objektlokalisierung in RGB-D-Scans mit natürlicher Sprache | ECCV '20 | Github |
Ihre Beiträge sind immer willkommen!
Ich werde einige Pull -Anfragen offen halten, wenn ich nicht sicher bin, ob sie für 3D -LLMs großartig sind. Sie könnten für sie stimmen, indem Sie hinzufügen? für sie.
Wenn Sie Fragen zu dieser Meinung haben, wenden Sie sich bitte an [email protected] oder Wechat ID: MXZ1997112.
Wenn Sie dieses Repository nützlich finden, sollten Sie dieses Papier zitieren:
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}Dieses Repo ist inspiriert von Awesome-Llm


